L'éditeur de Downcodes vous fera comprendre en profondeur les secrets du modèle Transformer ! Récemment, un article intitulé "Transformer Layers as Painters" a expliqué de manière vivante le mécanisme de fonctionnement de la couche intermédiaire du modèle Transformer du point de vue d'un "peintre". Grâce à des métaphores et des expériences intelligentes, cet article révèle le fonctionnement de la hiérarchie Transformer, nous fournissant de nouvelles idées pour comprendre les opérations internes des grands modèles de langage. Dans cet article, l'auteur compare chaque couche du Transformer à un peintre travaillant ensemble pour créer une grande image linguistique, et vérifie cette vision à travers une série d'expériences.
Dans le monde de l'intelligence artificielle, il existe un groupe spécial de peintres : la structure hiérarchique du modèle Transformer. Ils sont comme des pinceaux magiques, peignant un monde coloré sur la toile du langage. Récemment, un article intitulé Transformer Layers as Painters nous offre une nouvelle perspective pour comprendre le mécanisme de fonctionnement de la couche intermédiaire du Transformer.
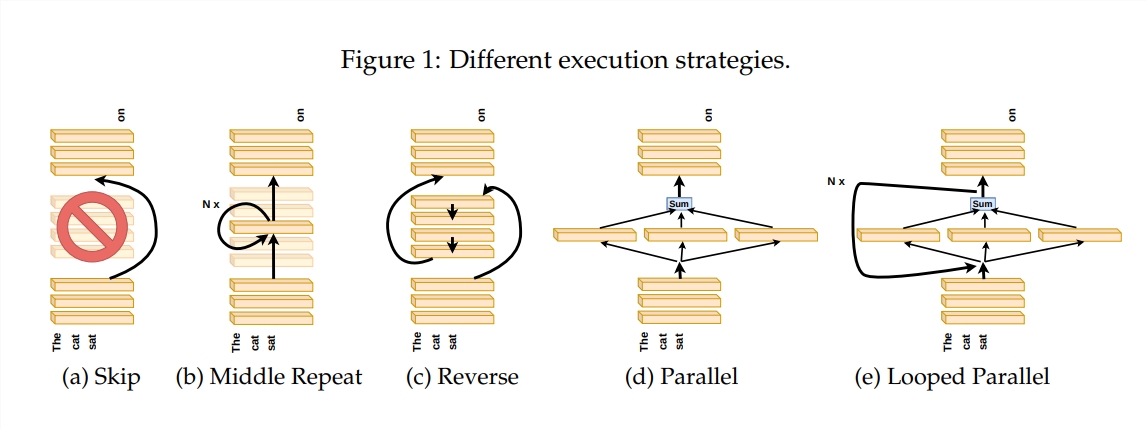
Le modèle Transformer, en tant que modèle de langage à grande échelle le plus populaire à l'heure actuelle, comporte des milliards de paramètres. Chaque couche est comme un peintre, travaillant ensemble pour compléter un grand tableau linguistique. Mais comment ces peintres ont-ils travaillé ensemble ? En quoi les pinceaux et les peintures qu'ils ont utilisés différaient-ils ? Cet article tente de répondre à ces questions.
Afin d'explorer le fonctionnement de la couche Transformer, l'auteur a conçu une série d'expériences, notamment en sautant certaines couches, en modifiant l'ordre des couches ou en exécutant des couches en parallèle. Ces expériences reviennent à établir différentes règles de peinture pour les peintres afin de voir s'ils peuvent s'adapter.
Dans la métaphore du « pipeline du peintre », l'entrée est considérée comme une toile, et le processus de passage à travers les couches intermédiaires est comme le passage de la toile sur la chaîne de montage. Chaque « peintre », c'est-à-dire chaque couche du Transformer, modifiera le tableau selon sa propre expertise. Cette analogie nous aide à comprendre le parallélisme et l'évolutivité de la couche Transformer.
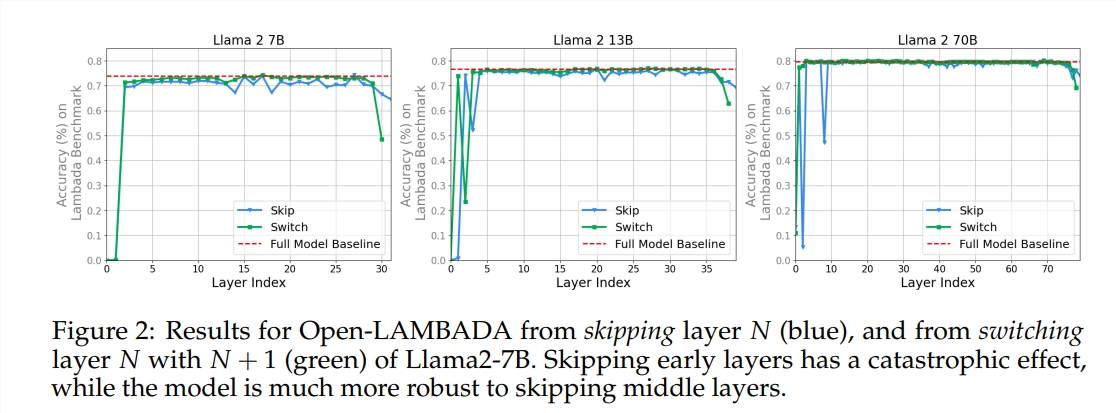
L'expérience a utilisé deux grands modèles de langage (LLM) pré-entraînés : Llama2-7B et BERT. L’étude a révélé que les peintres des niveaux intermédiaires semblaient partager une boîte de peinture commune – représentant l’espace – différente de celle des peintres des premier et dernier niveaux. Les peintres qui sautent certaines couches intermédiaires ont peu d’impact sur l’ensemble du tableau, ce qui indique que tous les peintres ne sont pas nécessaires.
Bien que les peintres de la couche intermédiaire utilisent la même boîte de peinture, ils utilisent leurs propres compétences pour peindre différents motifs sur la toile. Si vous réutilisez simplement une certaine technique de peintre, le tableau perdra son charme originel.
L'ordre dans lequel vous dessinez est particulièrement important pour les tâches mathématiques et de raisonnement qui nécessitent une logique stricte. Pour les tâches qui reposent sur la compréhension sémantique, l’impact de l’ordre est relativement faible.
Les résultats de la recherche montrent que la couche intermédiaire du Transformer présente un certain degré de cohérence mais n'est pas redondante. Pour les tâches mathématiques et de raisonnement, l’ordre des couches est plus important que pour les tâches sémantiques.
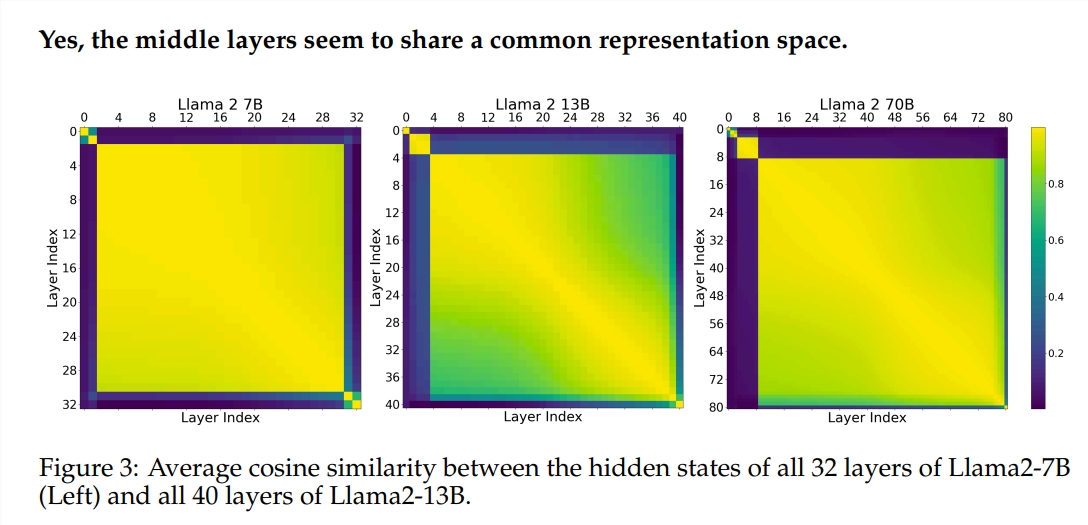
L'étude a également révélé que toutes les couches ne sont pas nécessaires et que les couches intermédiaires peuvent être ignorées sans affecter de manière catastrophique les performances du modèle. De plus, bien que les couches intermédiaires partagent le même espace de représentation, elles remplissent des fonctions différentes. La modification de l'ordre d'exécution des couches entraînait une dégradation des performances, ce qui indique que l'ordre a un impact important sur les performances du modèle.
En route vers l'exploration du modèle Transformer, de nombreux chercheurs tentent de l'optimiser, notamment en l'élaguant, en réduisant les paramètres, etc. Ces travaux fournissent une expérience et une inspiration précieuses pour comprendre le modèle Transformer.
Adresse papier : https://arxiv.org/pdf/2407.09298v1
Dans l'ensemble, cet article nous offre une nouvelle perspective pour comprendre le mécanisme interne du modèle Transformer et fournit de nouvelles idées pour l'optimisation future du modèle. L'éditeur de Downcodes recommande aux lecteurs intéressés de lire l'article complet pour comprendre en profondeur les mystères du modèle Transformer !