Le domaine du traitement du langage naturel (NLP) évolue chaque jour, et le développement rapide des grands modèles de langage (LLM) nous a apporté des opportunités et des défis sans précédent. Parmi eux, la dépendance de l'évaluation du modèle à l'égard des données annotées par l'homme constitue un goulot d'étranglement. Le travail de collecte de données coûteux et long limite l'évaluation efficace et l'amélioration continue du modèle. L'éditeur de Downcodes vous présentera une nouvelle solution proposée par les chercheurs de Meta FAIR - "Self-learning Evaluator", qui apporte une nouvelle idée pour résoudre ce problème.
À l'ère actuelle, le domaine du traitement du langage naturel (NLP) se développe rapidement et les grands modèles de langage (LLM) peuvent effectuer des tâches complexes liées au langage avec une grande précision, offrant ainsi davantage de possibilités d'interaction homme-machine. Cependant, un problème important en PNL est le recours aux annotations humaines pour l’évaluation des modèles.
Les données générées par l'homme sont essentielles à la formation et à la validation des modèles, mais la collecte de ces données est coûteuse et prend du temps. De plus, à mesure que les modèles continuent de s'améliorer, les annotations précédemment collectées peuvent devoir être mises à jour, ce qui les rend moins utiles pour évaluer de nouveaux modèles. Cela entraîne la nécessité d'acquérir continuellement de nouvelles données, ce qui pose des défis en termes d'échelle et de durabilité d'une évaluation efficace des modèles.
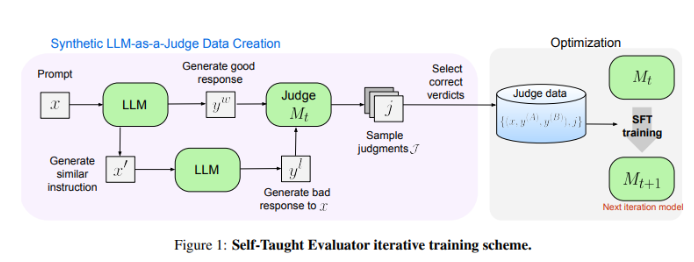
Les chercheurs de Meta FAIR ont mis au point une nouvelle solution : l'« évaluateur autodidacte ». Cette approche ne nécessite pas d'annotations humaines et est formée sur des données générées synthétiquement. Tout d'abord, un modèle de départ génère des paires de préférences synthétiques contrastées, puis le modèle évalue ces paires et les améliore de manière itérative, en utilisant son propre jugement pour améliorer les performances dans les itérations suivantes, réduisant ainsi considérablement le recours aux annotations générées par l'homme.
Les chercheurs ont testé les performances de « l'évaluateur auto-apprenant » à l'aide du modèle Llama-3-70B-Instruct. Cette méthode améliore la précision du modèle sur le benchmark RewardBench de 75,4 à 88,7, correspondant voire dépassant les performances des modèles entraînés avec des annotations humaines. Après plusieurs itérations, le modèle final a atteint une précision de 88,3 avec une seule inférence et de 88,7 avec un vote majoritaire, démontrant sa forte stabilité et sa fiabilité.
L'« Évaluateur d'auto-apprentissage » fournit une solution évolutive et efficace pour l'évaluation des modèles PNL, exploitant les données synthétiques et l'auto-amélioration itérative, relevant les défis liés au recours aux annotations humaines et faisant progresser le développement de modèles de langage.
Adresse papier : https://arxiv.org/abs/2408.02666
L'« évaluateur d'auto-apprentissage » de Meta FAIR a apporté des changements révolutionnaires à l'évaluation des modèles NLP, et ses fonctionnalités efficaces et évolutives favoriseront efficacement la progression continue des futurs modèles de langage. Ce résultat de recherche réduit non seulement la dépendance à l’égard des données annotées par l’homme, mais ouvre surtout la voie à la création de modèles PNL plus puissants et plus fiables. Nous attendons avec impatience d’autres innovations similaires à l’avenir !