Mini-Omni, un modèle de langage multimodal open source à grande échelle, révolutionne la technologie d'interaction vocale. Il intègre une technologie avancée pour réaliser une entrée et une sortie vocales en temps réel, et a la capacité de penser et de parler en même temps, apportant une expérience d'interaction homme-machine plus naturelle et plus fluide. Le principal avantage de Mini-Omni réside dans ses capacités de traitement vocal en temps réel de bout en bout. Aucune configuration supplémentaire des modèles ASR ou TTS n'est requise pour profiter de conversations fluides. Il prend en charge plusieurs entrées modales et les convertit de manière flexible pour s'adapter à divers scénarios complexes et répondre à divers besoins.
Aujourd'hui, avec le développement rapide de l'intelligence artificielle, un modèle de langage multimodal open source à grande échelle appelé Mini-Omni est à la pointe de l'innovation en matière de technologie d'interaction vocale. Ce système d'IA intégré à plusieurs technologies avancées permet non seulement l'entrée et la sortie vocales en temps réel, mais possède également la capacité unique de penser et de parler en même temps, offrant aux utilisateurs une expérience d'interaction naturelle sans précédent.
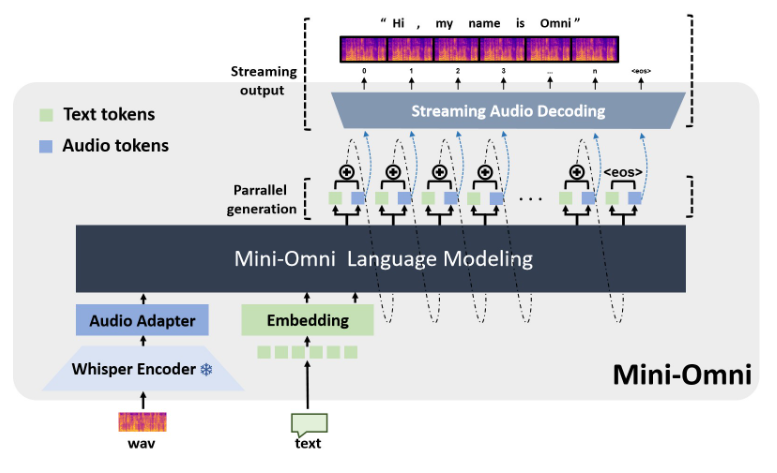
Le principal avantage de Mini-Omni réside dans ses capacités de traitement vocal en temps réel de bout en bout. Les utilisateurs peuvent profiter de conversations vocales fluides sans configuration supplémentaire des modèles de reconnaissance vocale automatique (ASR) ou de synthèse vocale (TTS). Cette conception transparente améliore considérablement l’expérience utilisateur et rend l’interaction homme-machine plus naturelle et intuitive.
En plus de la fonction vocale, Mini-Omni prend également en charge la saisie dans plusieurs modes tels que le texte, et peut basculer de manière flexible entre différents modes. Cette capacité de traitement multimodal permet au modèle de s'adapter à divers scénarios d'interaction complexes et de répondre aux divers besoins des utilisateurs.
Il convient particulièrement de mentionner la fonction Any Model Can Talk de Mini-Omni. Cette innovation permet à d’autres modèles d’IA d’intégrer facilement les capacités vocales en temps réel du Mini-Omni, élargissant ainsi considérablement les possibilités des applications d’IA. Cela offre non seulement plus de choix aux développeurs, mais ouvre également la voie à l’application multidisciplinaire de la technologie de l’IA.
En termes de performances, Mini-Omni montre toute sa force. Il fonctionne non seulement bien dans les tâches vocales traditionnelles telles que la reconnaissance vocale (ASR) et la génération vocale (TTS), mais montre également un fort potentiel dans les tâches multimodales qui nécessitent des capacités de raisonnement complexes telles que TextQA et SpeechQA. Cette capacité complète permet à Mini-Omni de gérer une variété de scénarios d'interaction complexes, des simples commandes vocales aux tâches de questions et réponses qui nécessitent une réflexion approfondie.
La mise en œuvre technique de Mini-Omni intègre plusieurs modèles et technologies d'IA avancés. Il utilise Qwen2 comme base d'un grand modèle de langage, utilise litGPT pour la formation et l'inférence, utilise Whisper pour le codage audio et snac est responsable du décodage audio. Cette méthode de fusion multitechnologique améliore non seulement les performances globales du modèle, mais améliore également son adaptabilité dans différents scénarios.
Pour les développeurs et les chercheurs, Mini-Omni offre une utilisation pratique. Avec des étapes d'installation simples, les utilisateurs peuvent lancer Mini-Omni dans leur environnement local et réaliser des démonstrations interactives via des outils tels que Streamlit et Gradio. Cette fonctionnalité ouverte et facile à utiliser apporte un soutien solide à la vulgarisation et à l’application innovante de la technologie de l’IA.
Adresse du projet : https://github.com/gpt-omni/mini-omni
Avec ses fonctions puissantes, son utilisation pratique et ses fonctionnalités open source, Mini-Omni apporte de nouvelles possibilités dans le domaine de l'interaction vocale IA et mérite l'attention et l'exploration des développeurs et des chercheurs. Son développement futur mérite également d’être attendu.