Récemment, le modèle d'IA open source Reflection70B a attiré l'attention du secteur en raison de sa controverse sur ses performances. Le modèle a été publié par HyperWrite, qui prétendait à l'origine qu'il s'agissait du modèle open source le plus puissant au monde et a attiré beaucoup d'attention en raison de ses excellentes performances lors de tests tiers. Cependant, certaines institutions indépendantes et utilisateurs ont ensuite remis en question ses performances, et les résultats des tests différaient considérablement des affirmations initiales d'HyperWrite.
Le modèle d'IA open source Reflection70B, qui vient de faire ses débuts, a récemment été largement remis en question par l'industrie.
Ce modèle publié par la startup new-yorkaise HyperWrite, qui prétend être la variante Llama3.1 de Meta, a attiré l'attention en raison de ses excellentes performances lors de tests tiers. Cependant, à mesure que certains résultats de tests étaient publiés, la réputation de Reflection70B a commencé à être remise en question.
La cause du problème était que le co-fondateur et PDG d'HyperWrite, Matt Shumer, a annoncé Reflection70B sur le réseau social X le 6 septembre et l'a qualifié avec confiance de "modèle open source le plus puissant au monde".
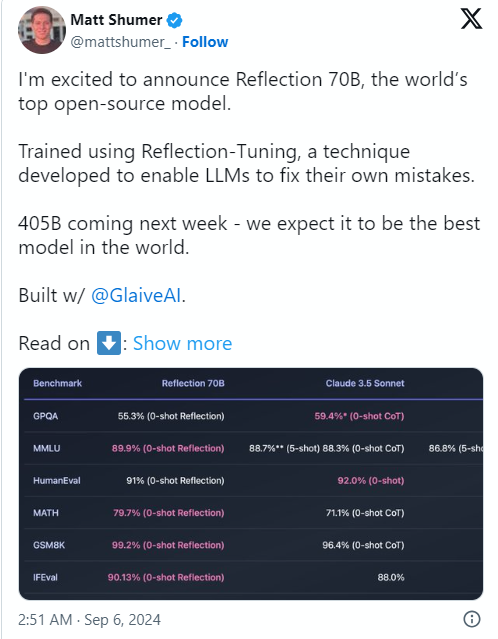
Shumer a également parlé de la technologie de « réglage réfléchi » du modèle, affirmant que cette méthode permet au modèle de se réviser avant de générer du contenu, améliorant ainsi la précision.
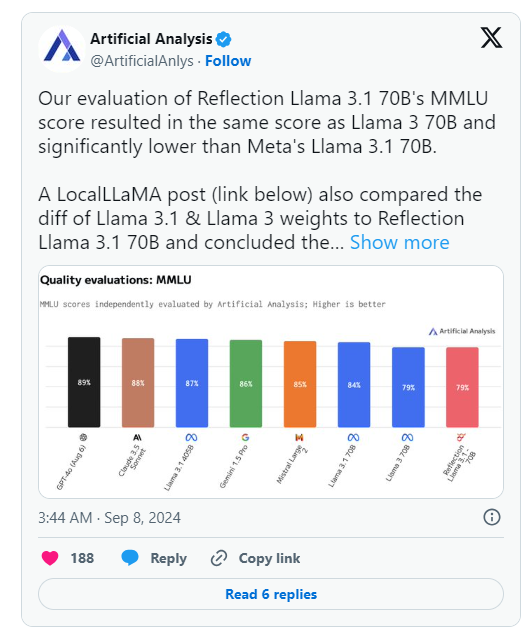
Cependant, le lendemain de l'annonce d'HyperWrite, Artificial Analysis, un groupe spécialisé dans « l'analyse indépendante des modèles d'IA et des fournisseurs d'hébergement », a publié sa propre analyse sur X, notant qu'il avait évalué le score MMLU (Massive Multitask Language Understanding) de Reflection Llama3.170B. est identique à Llama370B, mais nettement inférieur à Llama3.170B de Meta, ce qui constitue une différence significative par rapport aux résultats initialement publiés par HyperWrite/Shumer.
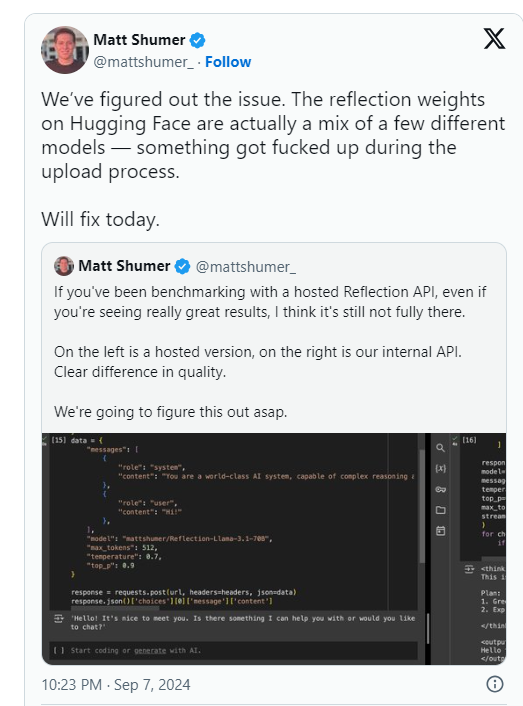
Shumer a déclaré plus tard qu'il y avait un problème avec les poids de Reflection70B (ou les paramètres du modèle open source) lors du téléchargement sur Hugging Face (un référentiel et une société d'hébergement de code d'IA tiers), ce qui aurait pu entraîner de moins bonnes performances que "l'API interne" d'HyperWrite. " version. .
Artificial Analysis a déclaré dans une déclaration ultérieure qu'ils avaient eu accès à l'API privée et avaient constaté des performances impressionnantes, mais pas au niveau initialement indiqué. Étant donné que ce test a été effectué sur une API privée, ils n’ont pas pu vérifier de manière indépendante ce qu’ils testaient.
Le groupe a soulevé deux problèmes clés qui remettent sérieusement en question les performances initiales d'HyperWrite et de Shumer :
Pendant ce temps, les utilisateurs de plusieurs communautés d’apprentissage automatique et d’IA sur Reddit ont également remis en question les performances et les origines revendiquées de Reflection70B. Certains ont souligné que Reflection70B semble être une variante de Llama3 plutôt que de Llama-3.1 , sur la base d'une comparaison de modèles publiée par un tiers sur Github, jetant davantage de doute sur les affirmations initiales de Shumer et HyperWrite.
Cela a amené au moins un utilisateur X, Shin Megami Boson, à publier le 8 septembre HE.
À 20 h 07 HAE, Shumer a publiquement accusé Shumer de « conduite frauduleuse » dans la communauté de recherche sur l’IA et a publié une longue liste de captures d’écran et d’autres preuves.
D'autres ont allégué que le modèle est en fait un « wrapper » ou une application construite sur Claude3, un concurrent propriétaire/à source fermée d'Anthropic.
Cependant, d'autres utilisateurs de X ont pris la défense de Shumer et du Reflection70B, certains affichant également des performances impressionnantes de leur côté du modèle.
Actuellement, la communauté de recherche en IA attend la réponse de Shumer à ces accusations de fraude et la mise à jour des poids des modèles sur Hugging Face.
Après la sortie du modèle Reflection70B, les performances ont été remises en question, les résultats des tests ne reproduisant pas les affirmations initiales.
⚙️ Le fondateur d'HyperWrite a expliqué que les problèmes de téléchargement de modèle entraînaient une dégradation des performances et a attiré l'attention sur la version mise à jour.
Le modèle a été vivement débattu sur les réseaux sociaux, avec des accusations et des défenses mêlées.
À l'heure actuelle, l'incident Reflection70B continue de fermenter et le résultat final doit encore attendre une enquête plus approfondie et une réponse. Cet incident nous rappelle également que nous devons être prudents quant à la promotion des performances de tout modèle d'IA et nous fier aux résultats de vérifications indépendantes pour porter des jugements.