L'équipe OpenDataLab de la base de données de grands modèles du Laboratoire d'intelligence artificielle de Shanghai (Shanghai AI Laboratory) a publié un nouvel outil d'extraction de données intelligent MinerU lors du forum principal WAIC Science Frontier 2024. Cet outil open source vise à simplifier le processus de traitement des données de l’IA et à aider les chercheurs à extraire plus efficacement des données de haute qualité à partir de documents volumineux. MinerU prend en charge une variété de formats de documents, notamment PDF, pages Web, epub, mobi et docx, etc., et les convertit au format Markdown facile à analyser. Ses modules fonctionnels de base Magic-PDF et Magic-Doc se concentrent respectivement sur l'extraction de documents PDF et de pages Web/livres électroniques, et utilisent des modèles tels que LayoutLMv3, YOLOv8, UniMERNet et PaddleOCR pour obtenir une extraction de données de haute qualité, améliorant considérablement les données. efficacité du traitement.
Lors du forum principal WAIC Science Frontier 2024, l'équipe OpenDataLab de la base de données de grands modèles du Laboratoire d'intelligence artificielle de Shanghai (Shanghai AI Laboratory) a publié un nouvel outil d'extraction de données intelligent appelé MinerU. Cet outil est conçu pour simplifier le processus de traitement des données d'IA et aider les chercheurs en IA à extraire des données de haute qualité à partir de documents volumineux.
MinerU est un outil d'extraction de données de documents et de pages Web open source tout-en-un qui peut convertir des documents PDF multimodaux, notamment des images, des tableaux, des formules, etc., au format Markdown clair et facile à analyser. Il peut également analyser et extraire rapidement le contenu formel de pages Web contenant des informations d'interférence telles que des publicités, et prend en charge la conversion par lots de plusieurs formats tels que epub, mobi, docx, etc. vers Markdown.
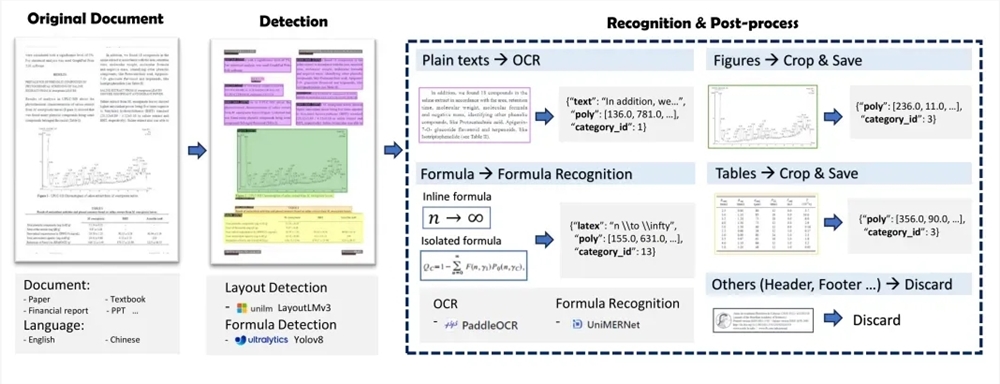
MinerU se compose de deux parties principales : Magic-PDF et Magic-Doc. Magic-PDF se concentre sur l'extraction de documents PDF et convertit les PDF au format Markdown. Il peut identifier rapidement les éléments de mise en page PDF, supprimer automatiquement le contenu non textuel et conserver la structure et le format du document original. Magic-Doc est responsable de l'extraction de pages Web et de livres électroniques, prenant en charge l'extraction d'informations courantes sur les pages Web telles que les articles, les forums, la musique, les vidéos, etc., ainsi que la conversion des formats de livres électroniques.
Au niveau technique, le processus d'extraction de documents PDF de MinerU comprend le prétraitement de la classification des documents PDF, l'analyse du modèle, le traitement du pipeline et l'inspection de la qualité des résultats de l'extraction PDF. Il utilise une série de modèles, tels que LayoutLMv3, YOLOv8, UniMERNet et PaddleOCR, pour obtenir une extraction de données documentaires de haute qualité.
La sortie de MinerU fournit non seulement aux chercheurs en IA un puissant outil de traitement de données, mais favorise également la mise à niveau de l'ensemble du système d'outils de chaîne pour le développement et l'application de grands modèles.
Lien vers l'expérience de la communauté Magic :
https://modelscope.cn/studios/OpenDataLab/MinerU
Lien du code open source :
https://github.com/opendatalab/MinerU/
Modèle open source MinerU (PDF-Extract-Kit) :
https://modelscope.cn/models/OpenDataLab/PDF-Extract-Kit
L'open source et la facilité d'utilisation de MinerU faciliteront grandement les chercheurs et les développeurs en IA, accéléreront l'efficacité du traitement des données dans le domaine de l'IA et fourniront un soutien solide au développement de grands modèles. Bienvenue pour visiter le lien pour découvrir et utiliser MinerU.