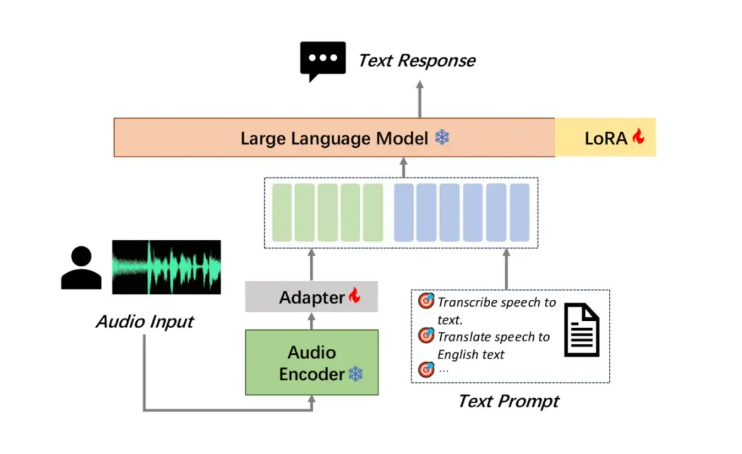
Moore Thread a rendu open source son grand modèle de compréhension audio MooER, qui est le premier grand modèle vocal open source du secteur basé sur la formation et l'inférence GPU nationales complètes, ce qui constitue une étape importante. MooER prend en charge la reconnaissance vocale en chinois et en anglais et la traduction phonétique chinois-anglais, démontrant de puissantes capacités de traitement multilingue. Sa structure de modèle innovante en trois parties (encodeur, adaptateur et décodeur) permet au modèle de traiter efficacement l'audio et d'effectuer des tâches en aval. À l'heure actuelle, le code d'inférence et le modèle formé sur la base de 5 000 heures de données sont open source. À l'avenir, le code de formation et le modèle amélioré formé sur la base de 80 000 heures de données seront open source, ce qui favorisera grandement le développement. de la technologie audio AI au pays et à l’étranger.
MooER a obtenu de bons résultats lors des tests comparatifs de plusieurs grands modèles audio open source bien connus, avec un taux d'erreur sur les mots chinois (CER) aussi bas que 4,21 % et un taux d'erreur sur les mots anglais (WER) de 17,98 %, en particulier BLEU sur le chinois. -Ensemble de tests de traduction en anglais Le score atteint 25,2, en tête des autres modèles open source. Le modèle MooER-80k formé sur la base de 80 000 heures de données présente des performances plus élevées, avec un CER et un WER réduits respectivement à 3,50 % et 12,66 %, montrant un grand potentiel. Cette décision de Moore Thread démontre non seulement la forte force des GPU nationaux dans le domaine de l'IA, mais injecte également une nouvelle vitalité dans le développement de la technologie mondiale de l'IA audio. On s'attend à ce que MooER apporte davantage de percées à l'avenir.
Lors de tests comparatifs avec plusieurs modèles audio open source bien connus comprenant de grands modèles, le MooER-5K a obtenu d'excellents résultats. Dans le test chinois, son taux d'erreur sur les mots (CER) a atteint 4,21 % ; dans le test en anglais, son taux d'erreur sur les mots (WER) était de 17,98 %, ce qui est meilleur ou équivalent à celui des autres modèles haut de gamme. Il convient particulièrement de mentionner que sur l'ensemble de tests de traduction chinois-anglais Covost2zh2en, le score BLEU de MooER atteint 25,2, nettement en avance sur les autres modèles open source et atteint un niveau comparable aux applications de niveau industriel.
Ce qui est encore plus excitant, c'est que le modèle MooER-80k formé sur la base de 80 000 heures de données montre des performances plus puissantes sur l'ensemble de test chinois a encore chuté à 3,50 %, et le WER sur l'ensemble de test anglais a également été optimisé à 12,66. %. Montre un énorme potentiel de développement.
Le MooER open source de Moore Thread démontre non seulement la force d'application des GPU nationaux dans le domaine de l'IA, mais injecte également une nouvelle vitalité dans le développement de la technologie mondiale d'IA audio. À mesure que davantage de données et de codes de formation deviennent open source, l'industrie s'attend à ce que MooER apporte davantage de percées dans la reconnaissance vocale, la traduction et d'autres domaines, et favorise la vulgarisation et l'application innovante de la technologie audio d'IA.
Adresse : https://arxiv.org/pdf/2408.05101
L'open source de MooER marque que les GPU nationaux ont fait des progrès significatifs dans le domaine des grands modèles d'IA, fournissant des ressources et des plates-formes précieuses aux développeurs nationaux et étrangers. On s'attend à ce que MooER puisse jouer un rôle dans davantage de scénarios d'application à l'avenir et promouvoir l'innovation et le développement continus de la technologie de l'IA audio.