Tencent Youtu Lab et d'autres institutions ont open source le premier grand modèle de langage multimodal VITA, qui peut traiter des vidéos, des images, du texte et de l'audio en même temps et offrir une expérience interactive fluide. L'émergence de VITA vise à combler les lacunes des modèles linguistiques à grande échelle existants dans le traitement du dialecte chinois. Basé sur le modèle Mixtral8×7B, le vocabulaire chinois est élargi et les instructions bilingues sont affinées, ce qui permet de maîtriser l'anglais. et parle couramment le chinois. Cela marque un progrès significatif pour la communauté open source en matière de compréhension et d’interaction multimodales.
Récemment, des chercheurs du Tencent Youtu Lab et d'autres institutions ont lancé le premier modèle de langage multimodal open source VITA, qui peut traiter simultanément des vidéos, des images, du texte et de l'audio, et son expérience interactive est également de première classe.
Le modèle VITA est né pour combler les lacunes des grands modèles linguistiques dans le traitement des dialectes chinois. Il est basé sur le puissant modèle Mixtral8×7B, un vocabulaire chinois étendu et des instructions bilingues affinées, ce qui permet à VITA non seulement de maîtriser l'anglais, mais également de parler couramment le chinois.
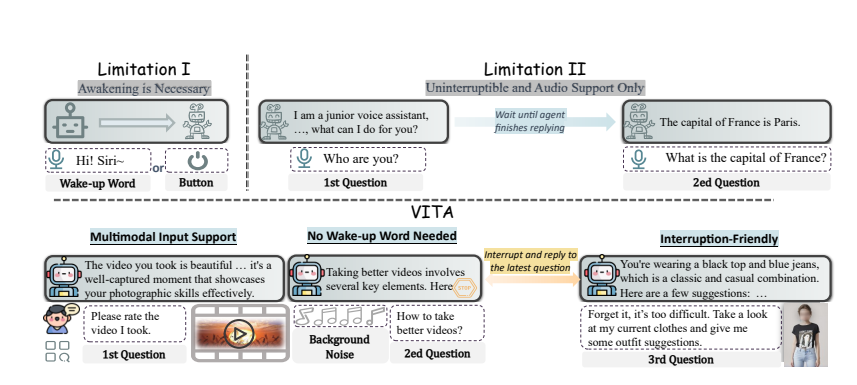
Principales caractéristiques :
Compréhension multimodale : la capacité de VITA à traiter la vidéo, les images, le texte et l'audio est sans précédent parmi les modèles open source.
Interaction naturelle : Pas besoin de dire « Hey, VITA » à chaque fois, il peut répondre à tout moment lorsque vous parlez, et même lorsque vous parlez à d'autres, il peut rester poli et ne pas vous interrompre à volonté.
Pionnier de l'Open Source : VITA constitue une étape importante pour la communauté open source dans la compréhension et l'interaction multimodales, jetant les bases de recherches ultérieures.
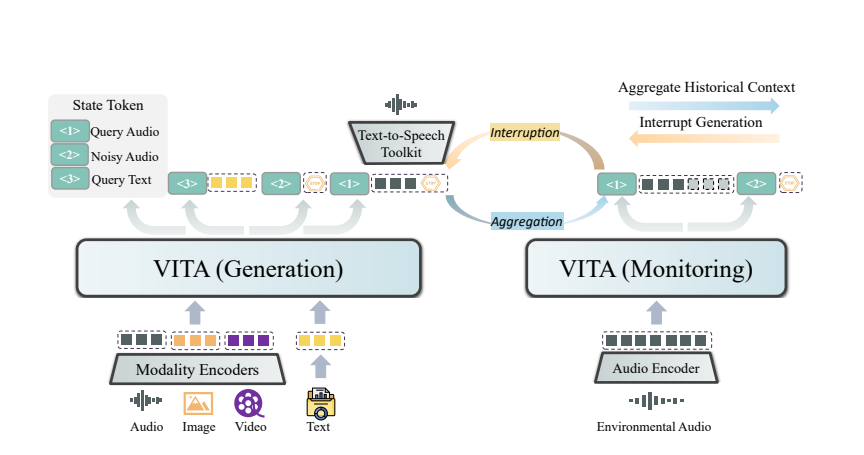
La magie de VITA vient de son déploiement double modèle. Un modèle est chargé de générer des réponses aux requêtes des utilisateurs, et l'autre modèle suit en permanence les entrées environnementales pour garantir que chaque interaction est précise et opportune.
VITA peut non seulement discuter, mais également servir de partenaire de discussion lorsque vous faites de l'exercice et même vous donner des conseils lorsque vous voyagez. Il peut également répondre à des questions basées sur les images ou le contenu vidéo que vous fournissez, démontrant ainsi sa grande fonctionnalité.
Bien que VITA ait montré un grand potentiel, elle continue d'évoluer en termes de synthèse vocale émotionnelle et de support multimodal. Les chercheurs prévoient de permettre à la prochaine génération de VITA de générer un son de haute qualité à partir d'une entrée vidéo et textuelle, et même d'explorer la possibilité de générer simultanément un son et une vidéo de haute qualité.
L'open source du modèle VITA n'est pas seulement une victoire technique, mais aussi une profonde innovation en matière d'interaction intelligente. Avec l'approfondissement de la recherche, nous avons des raisons de croire que VITA nous apportera une expérience interactive plus intelligente et plus humaine.
Adresse papier : https://arxiv.org/pdf/2408.05211
L'open source de VITA ouvre une nouvelle direction pour le développement de grands modèles de langage multimodaux. Ses fonctions puissantes et son expérience interactive pratique indiquent que l'interaction homme-machine sera plus intelligente et humaine à l'avenir. Nous espérons que VITA réalisera de plus grandes percées à l’avenir et apportera plus de commodité à la vie des gens.