Alibaba a lancé un nouveau modèle vocal open source Qwen2-Audio, qui a considérablement amélioré la reconnaissance vocale, la traduction et l'analyse audio. Ses fonctions et performances surpassent le produit de la génération précédente Qwen-Audio, et l'ont même surpassé dans plusieurs tests de référence d'OpenAI. grand-v3. Qwen2-Audio prend en charge plusieurs langues et fournit une version de base et une version affinée avec des instructions. Les utilisateurs peuvent poser des questions vocalement et effectuer une reconnaissance et une analyse de contenu audio, comme déterminer l'âge et l'émotion de l'orateur ou analyser divers sons. composants dans l’audio. Le modèle utilise des invites en langage plus naturel pour la pré-formation, améliorant considérablement les capacités de compréhension et de réponse, et introduit deux modes de chat vocal et d'analyse audio pour améliorer le naturel de l'interaction de l'utilisateur.
Récemment, Alibaba a lancé un nouveau modèle vocal open source Qwen2-Audio basé sur son Qwen-Audio. Ce modèle fonctionne non seulement bien en matière de reconnaissance vocale, de traduction et d'analyse audio, mais permet également d'améliorer considérablement les fonctionnalités et les performances. Qwen2-Audio fournit une version de base et une version affinée des instructions. Les utilisateurs peuvent poser des questions au modèle audio par la voix, reconnaître et analyser le contenu.
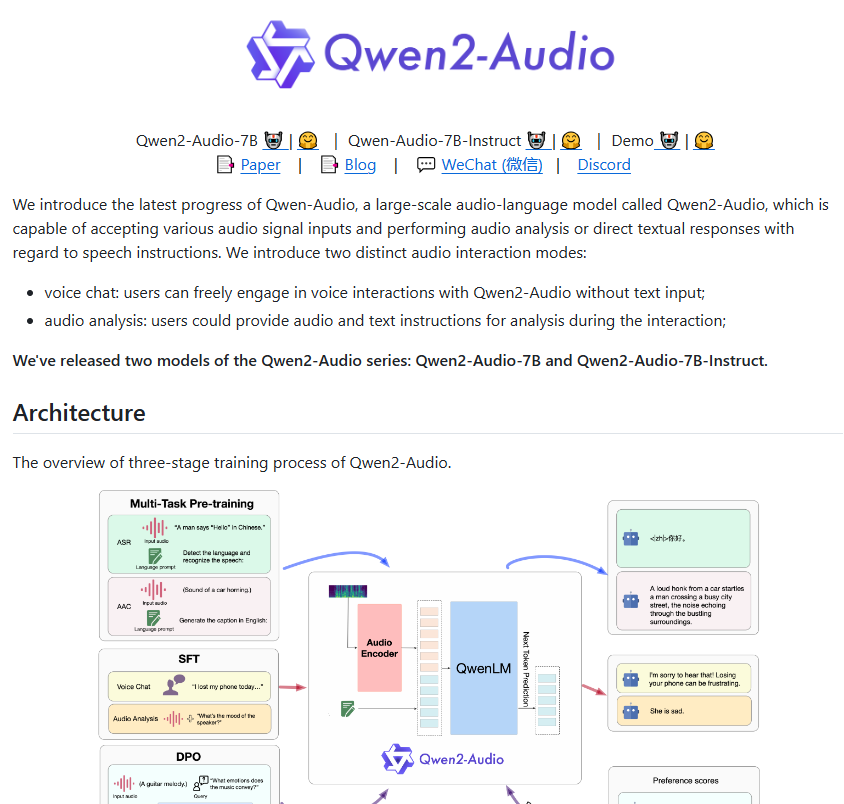
Par exemple, l'utilisateur peut demander à une femme de parler, et Qwen2-Audio peut déterminer son âge ou analyser ses émotions ; si un son bruyant est émis, le modèle peut analyser les différentes composantes sonores ; Qwen2-Audio prend en charge plusieurs langues, dont le chinois, le cantonais, le français, l'anglais et le japonais, ce qui offre une grande commodité pour le développement d'applications d'analyse et de traduction des sentiments.
Entrée du produit : https://top.aibase.com/tool/qwen2-audio
Par rapport au Qwen-Audio de première génération, Qwen2-Audio a été entièrement optimisé en termes d'architecture et de performances. Au cours de la phase de pré-formation, ce nouveau modèle utilise davantage d'indices de langage naturel pour remplacer les anciennes étiquettes hiérarchiques complexes. Cette amélioration rend le modèle plus facile à comprendre et à répondre à diverses tâches, et sa capacité de généralisation a également été considérablement améliorée.
La capacité de suivi des commandes de Qwen2-Audio a également été grandement améliorée et il peut comprendre les commandes de l'utilisateur avec plus de précision. Par exemple, lorsque l'utilisateur émet la commande « analyser la tendance émotionnelle dans cet audio », Qwen2-Audio peut déterminer avec précision l'émotion contenue dans l'audio. De plus, le modèle introduit deux modes : le chat vocal et l'analyse audio, rendant l'interaction vocale des utilisateurs plus naturelle. En mode d'analyse audio, Qwen2-Audio peut analyser en profondeur différents types d'audio et fournir des résultats d'analyse détaillés et précis.
Pour garantir que le résultat du modèle répond aux attentes humaines, Qwen2-Audio introduit également des technologies avancées telles que le réglage fin supervisé et l'optimisation directe des préférences. Les modèles semblent plus naturels et plus précis lorsqu’ils interagissent avec des humains.
En termes de tests de performances, Qwen2-Audio a obtenu de bons résultats dans plusieurs tests de référence courants, notamment en termes de précision de la reconnaissance vocale et de la traduction, surpassant Whisper-large-v3 d'OpenAI. Les performances de ce nouveau modèle ont non seulement attiré l’attention du secteur, mais ont également annoncé un nouvel avenir pour la technologie vocale.
Souligner:
Qwen2-Audio est le dernier modèle vocal open source d'Alibaba, qui prend en charge plusieurs langues et dispose de puissantes capacités de reconnaissance et d'analyse.
Par rapport à la génération précédente, Qwen2-Audio a été considérablement optimisé en termes de performances et d'architecture, améliorant ainsi sa capacité à comprendre et à répondre.
? Dans plusieurs tests de performances, Qwen2-Audio a surpassé Whisper d'OpenAI, démontrant une forte compétitivité.
L'open source de Qwen2-Audio favorisera le développement du domaine des technologies vocales, fournira aux développeurs des outils puissants et favorisera la naissance d'applications plus innovantes. Ses avantages en matière de prise en charge multilingue et de performances en font une direction importante pour le développement futur de la technologie vocale. Dans l'attente de l'application de Qwen2-Audio dans davantage de scénarios.