Les grands modèles de langage (LLM) sont confrontés à des problèmes de compréhension de textes longs, et la taille de leur fenêtre contextuelle limite leurs capacités de traitement. Pour résoudre ce problème, les chercheurs ont développé le test de référence LooGLE pour évaluer la capacité de compréhension du contexte long des LLM. LooGLE contient 776 documents ultra-longs (19,3 000 mots en moyenne) publiés après 2022 et 6 448 instances de test, couvrant plusieurs domaines, visant à évaluer de manière plus complète la capacité du modèle à comprendre et à traiter des textes longs. Ce benchmark évalue les performances des LLM existants et fournit une référence précieuse pour le développement de futurs modèles.
Dans le domaine du traitement du langage naturel, la compréhension d’un contexte long a toujours été un défi. Bien que les grands modèles de langage (LLM) fonctionnent bien sur une variété de tâches linguistiques, ils sont souvent limités lors du traitement de texte qui dépasse la taille de leur fenêtre contextuelle. Afin de surmonter cette limitation, les chercheurs ont travaillé dur pour améliorer la capacité des LLM à comprendre des textes longs, ce qui est non seulement important pour la recherche universitaire, mais également pour des scénarios d'application réels, tels que la compréhension des connaissances spécifiques à un domaine, les longs textes. la génération de dialogues et de longues histoires ou la génération de codes, etc., sont également cruciales.
Dans cette étude, les auteurs proposent un nouveau test de référence - LooGLE (Long Context Generic Language Evaluation), spécialement conçu pour évaluer la capacité de compréhension du contexte long des LLM. Ce benchmark contient 776 documents ultra-longs après 2022, chaque document contient en moyenne 19,3 000 mots et compte 6 448 instances de test, couvrant plusieurs domaines, tels que les universitaires, l'histoire, les sports, la politique, l'art, les événements et le divertissement, etc.
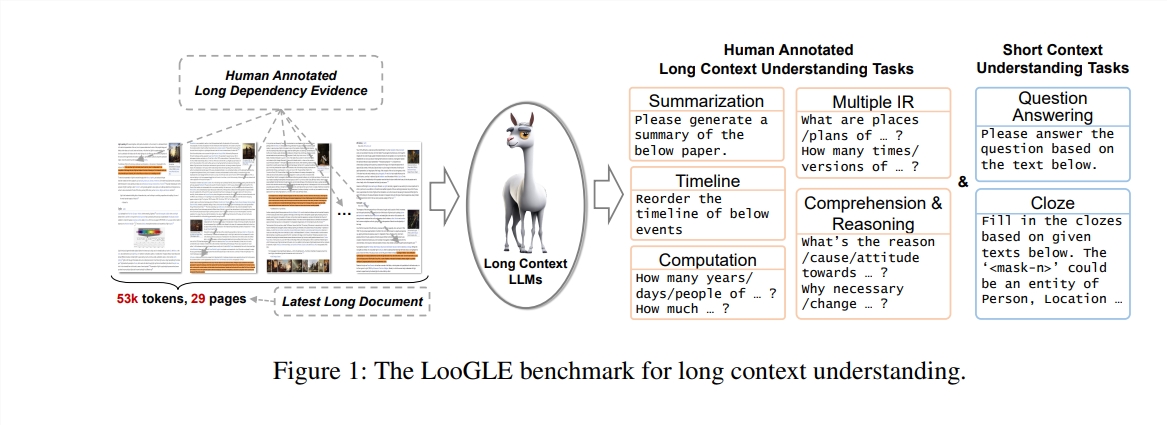
Caractéristiques de LooGLE
Documents réels ultra-longs : la longueur des documents dans ooGLE dépasse de loin la taille de la fenêtre contextuelle des LLM, ce qui nécessite que le modèle soit capable de mémoriser et de comprendre un texte plus long.
Tâches de dépendance longues et courtes conçues manuellement : le test de référence contient 7 tâches principales, y compris des tâches de dépendance courte et de dépendance longue, pour évaluer la capacité des LLM à comprendre le contenu des dépendances longues et courtes.
Documents relativement nouveaux : tous les documents ont été publiés après 2022, ce qui garantit que la plupart des LLM modernes n'ont pas été exposés à ces documents pendant la pré-formation, ce qui permet une évaluation plus précise de leurs capacités d'apprentissage contextuel.
Données communes inter-domaines : les données de référence proviennent de documents open source populaires, tels que des articles arXiv, des articles Wikipédia, des scripts de films et de séries télévisées, etc.
Les chercheurs ont mené une évaluation complète de huit LLM de pointe, et les résultats ont révélé les principales conclusions suivantes :
Le modèle commercial surpasse le modèle open source en termes de performances.
Les LLM fonctionnent bien sur les tâches à courte dépendance, mais présentent des défis sur les tâches plus complexes à longue dépendance.
Les méthodes basées sur l’apprentissage du contexte et les chaînes de pensée n’apportent que des améliorations limitées dans la compréhension du contexte à long terme.
Les techniques basées sur la récupération présentent des avantages significatifs dans la réponse à des questions courtes, tandis que les stratégies visant à étendre la longueur de la fenêtre contextuelle grâce à une architecture Transformer optimisée ou à un codage positionnel ont un impact limité sur la compréhension d'un contexte long.
Le benchmark LooGLE fournit non seulement un schéma d'évaluation systématique et complet pour évaluer les LLM à contexte long, mais fournit également des conseils pour le développement futur de modèles dotés de capacités de « véritable compréhension du contexte long ». Tout le code d'évaluation a été publié sur GitHub pour référence et utilisation par la communauté de recherche.
Adresse papier : https://arxiv.org/pdf/2311.04939
Adresse du code : https://github.com/bigai-nlco/LooGLE
Le benchmark LooGLE fournit un outil important pour évaluer et améliorer les capacités de compréhension de textes longs des LLM, et ses résultats de recherche sont d'une grande importance pour promouvoir le développement du domaine du traitement du langage naturel. Les pistes d'amélioration proposées par les chercheurs méritent attention. Je pense que des LLM de plus en plus puissants apparaîtront à l'avenir pour mieux gérer les textes longs.