Apple et Meta AI ont lancé conjointement une nouvelle technologie appelée LazyLLM, conçue pour améliorer considérablement l'efficacité des grands modèles de langage (LLM) dans le traitement du raisonnement de textes longs. Lorsque le LLM actuel traite de longues invites, la complexité informatique du mécanisme d'attention augmente avec le carré du nombre de jetons, ce qui entraîne une vitesse lente, en particulier dans la phase de pré-chargement. LazyLLM sélectionne dynamiquement les jetons importants pour le calcul, réduisant ainsi efficacement la quantité de calculs, et introduit le mécanisme Aux Cache pour restaurer efficacement les jetons élagués, augmentant ainsi considérablement la vitesse tout en garantissant la précision.
Récemment, l'équipe de recherche d'Apple et les chercheurs de Meta AI ont lancé conjointement une nouvelle technologie appelée LazyLLM, qui améliore l'efficacité des grands modèles de langage (LLM) dans le raisonnement de textes longs.
Comme nous le savons tous, le LLM actuel est souvent confronté à des problèmes de vitesse lente lors du traitement de longues invites, en particulier pendant la phase de précharge. Cela est principalement dû au fait que la complexité informatique des architectures de transformateurs modernes lors du calcul de l'attention augmente quadratiquement avec le nombre de jetons dans l'indice. Par conséquent, lors de l'utilisation du modèle Llama2, le temps de calcul du premier jeton est souvent 21 fois supérieur à celui des étapes de décodage suivantes, ce qui représente 23 % du temps de génération.
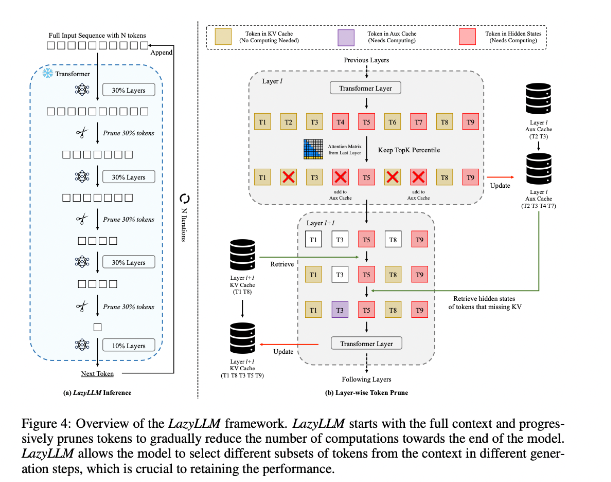
Afin d'améliorer cette situation, les chercheurs ont proposé LazyLLM, une nouvelle méthode permettant d'accélérer l'inférence LLM en sélectionnant dynamiquement la méthode de calcul des jetons importants. Le cœur de LazyLLM est qu'il évalue l'importance de chaque jeton en fonction du score d'attention de la couche précédente, réduisant ainsi progressivement la quantité de calcul. Contrairement à la compression permanente, LazyLLM peut restaurer les jetons élagués lorsque cela est nécessaire pour garantir la précision du modèle. De plus, LazyLLM introduit un mécanisme appelé Aux Cache, qui peut stocker l'état implicite des jetons élagués pour restaurer efficacement ces jetons et empêcher la dégradation des performances.
LazyLLM excelle en vitesse d'inférence, notamment dans les étapes de pré-remplissage et de décodage. Les trois principaux avantages de cette technique sont qu'elle est compatible avec n'importe quel LLM basé sur un transformateur, qu'elle ne nécessite pas de recyclage du modèle pendant la mise en œuvre et qu'elle fonctionne très efficacement sur une variété de tâches linguistiques. La stratégie d'élagage dynamique de LazyLLM lui permet de réduire considérablement la quantité de calcul tout en conservant les jetons les plus importants, augmentant ainsi la vitesse de génération.
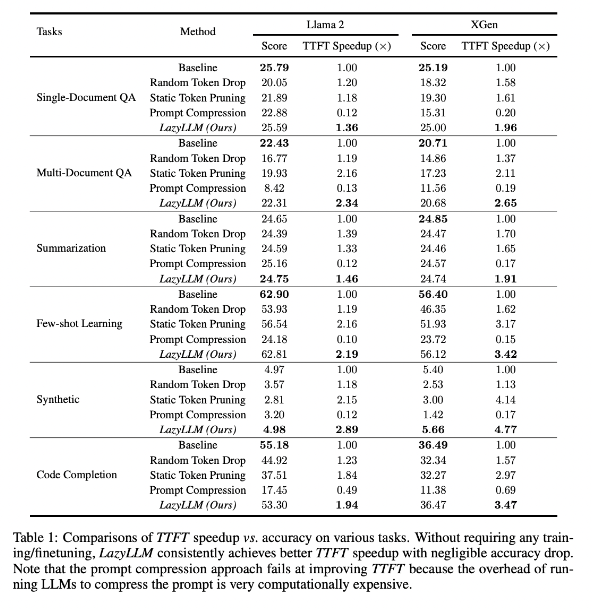
Les résultats de la recherche montrent que LazyLLM fonctionne bien sur plusieurs tâches linguistiques, avec une vitesse TTFT augmentée de 2,89 fois (pour Llama2) et de 4,77 fois (pour XGen), tandis que la précision est presque la même que la ligne de base. Qu'il s'agisse de tâches de réponse à des questions, de génération de résumés ou de complétion de code, LazyLLM peut atteindre une vitesse de génération plus rapide et atteindre un bon équilibre entre performances et vitesse. Sa stratégie de taille progressive couplée à une analyse couche par couche pose les bases du succès de LazyLLM.
Adresse papier : https://arxiv.org/abs/2407.14057
Points forts:
LazyLLM accélère le processus de raisonnement LLM en sélectionnant dynamiquement les jetons importants, en particulier dans les scénarios de texte long.
Cette technologie peut améliorer considérablement la vitesse d'inférence et la vitesse TTFT peut être augmentée jusqu'à 4,77 fois, tout en conservant une grande précision.
LazyLLM ne nécessite aucune modification des modèles existants, est compatible avec tout LLM basé sur un convertisseur et est facile à mettre en œuvre.
Dans l’ensemble, l’émergence de LazyLLM fournit de nouvelles idées et des solutions efficaces pour résoudre le problème de l’efficacité du raisonnement de textes longs LLM. Ses excellentes performances en termes de vitesse et de précision indiquent qu’il jouera un rôle important dans les futures applications de grands modèles. Cette technologie a de larges perspectives d’application et mérite d’attendre avec impatience son développement et ses applications ultérieurs.