Apple, en collaboration avec l'Université de Washington et d'autres institutions, a publié un modèle de langage puissant appelé DCLM en open source, avec une taille de paramètres de 700 millions et une quantité étonnante de données de formation atteignant 2,5 billions de jetons de données. DCLM n'est pas seulement un modèle de langage efficace, mais plus important encore, il fournit un outil appelé « Dataset Competition » (DataComp) pour optimiser l'ensemble de données du modèle de langage. Cette innovation améliore non seulement les performances du modèle, mais fournit également de nouvelles méthodes et normes pour la recherche sur les modèles de langage, qui méritent notre attention.
Récemment, l'équipe d'intelligence artificielle d'Apple a coopéré avec de nombreuses institutions telles que l'Université de Washington pour lancer un modèle de langage open source appelé DCLM. Ce modèle comporte 700 millions de paramètres et utilise jusqu'à 2,5 billions de jetons de données pendant la formation pour nous aider à mieux comprendre et générer du langage.
Alors, qu'est-ce qu'un modèle linguistique ? En termes simples, il s'agit d'un programme capable d'analyser et de générer du langage, nous aidant à accomplir diverses tâches telles que la traduction, la génération de texte et l'analyse des sentiments. Pour que ces modèles fonctionnent mieux, nous avons besoin d’ensembles de données de qualité. Cependant, obtenir et organiser ces données n’est pas une tâche facile car nous devons filtrer les contenus non pertinents ou nuisibles et supprimer les informations en double.
Pour relever ce défi, l’équipe de recherche d’Apple a lancé DataComp for Language Models (DCLM), un outil d’optimisation d’ensembles de données pour les modèles de langage. Ils ont récemment ouvert le modèle DCIM et l'ensemble de données sur la plateforme Hugging Face. Les versions open source incluent DCLM-7B, DCLM-1B, dclm-7b-it, DCLM-7B-8k, dclm-baseline-1.0 et dclm-baseline-1.0-parquet. Les chercheurs peuvent mener un grand nombre d'expériences via cette plateforme. et trouvez la meilleure solution.
https://huggingface.co/collections/mlfoundations/dclm-669938432ef5162d0d0bc14b
La principale force de DCLM réside dans son flux de travail structuré. Les chercheurs peuvent choisir des modèles de différentes tailles en fonction de leurs besoins, allant de 412 millions à 700 millions de paramètres, et peuvent également expérimenter différentes méthodes de conservation des données, telles que la déduplication et le filtrage. Grâce à ces expériences systématiques, les chercheurs peuvent clairement évaluer la qualité des différents ensembles de données. Cela jette non seulement les bases des recherches futures, mais nous aide également à comprendre comment améliorer les performances du modèle en améliorant l'ensemble de données.
Par exemple, en utilisant l'ensemble de données de référence établi par DCLM, l'équipe de recherche a formé un modèle de langage avec 700 millions de paramètres et a obtenu une précision en 5 coups de 64 % dans le test de référence MMLU. Il s'agit d'une amélioration de 6,6 par rapport au précédent ! niveau le plus élevé et utilise 40 % de ressources informatiques en moins. Les performances du modèle de base DCLM sont également comparables à celles de Mistral-7B-v0.3 et Llama38B, qui nécessitent beaucoup plus de ressources informatiques.
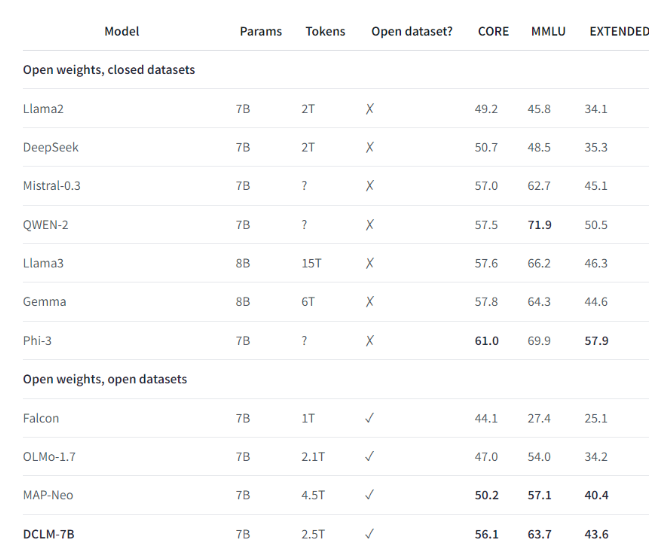
Le lancement de DCLM fournit une nouvelle référence pour la recherche sur les modèles de langage, aidant les scientifiques à améliorer systématiquement les performances du modèle tout en réduisant les ressources informatiques requises.
Points forts:
1️⃣ Apple AI a coopéré avec plusieurs institutions pour lancer DCLM, créant ainsi un puissant modèle de langage open source.
2️⃣ DCLM fournit des outils d'optimisation d'ensembles de données standardisés pour aider les chercheurs à mener des expériences efficaces.
3️⃣ Le nouveau modèle réalise des progrès significatifs dans des tests importants tout en réduisant les besoins en ressources de calcul.
Dans l'ensemble, l'open source de DCLM a insufflé une nouvelle vitalité au domaine de la recherche sur les modèles linguistiques, et ses outils efficaces d'optimisation des modèles et des ensembles de données devraient favoriser un développement plus rapide dans le domaine et favoriser la naissance de modèles linguistiques plus puissants et plus efficaces. À l’avenir, nous nous attendons à ce que le DCLM apporte des résultats de recherche plus surprenants.