L'équipe Alibaba Tongyi Qianwen a publié la série Qwen2 de modèles open source. Cette série comprend 5 tailles de modèles de pré-formation et de réglage fin des instructions. Le nombre de paramètres et les performances ont été considérablement améliorés par rapport à la génération précédente Qwen1.5. La série Qwen2 a également réalisé une percée majeure dans les capacités multilingues, prenant en charge 27 langues autres que l'anglais et le chinois. En termes de compréhension du langage naturel, de codage, de capacités mathématiques, etc., le grand modèle (70B+ paramètres) fonctionne bien, en particulier le modèle Qwen2-72B, qui surpasse la génération précédente en termes de performances et de nombre de paramètres. Cette version marque un nouveau sommet dans la technologie de l’intelligence artificielle, offrant des possibilités plus larges pour l’application et la commercialisation de l’IA à l’échelle mondiale.
Tôt ce matin, l'équipe Alibaba Tongyi Qianwen a publié la série Qwen2 de modèles open source. Cette série de modèles comprend 5 tailles de modèles pré-entraînés et peaufinés : Qwen2-0.5B, Qwen2-1.5B, Qwen2-7B, Qwen2-57B-A14B et Qwen2-72B. Les informations clés montrent que le nombre de paramètres et les performances de ces modèles ont été considérablement améliorés par rapport à la génération précédente Qwen1.5.
Pour les capacités multilingues du modèle, la série Qwen2 a investi beaucoup d'efforts pour augmenter la quantité et la qualité de l'ensemble de données, couvrant 27 autres languessauf l'anglais et le chinois. Après des tests comparatifs, le grand modèle (70B + paramètres) a obtenu de bons résultats en termes de compréhension du langage naturel, de codage, de capacités mathématiques, etc. Le modèle Qwen2-72B a surpassé la génération précédente en termes de performances et de nombre de paramètres.
Le modèle Qwen2 démontre non seulement de solides capacités en matière d'évaluation de modèles de langage de base, mais obtient également des résultats impressionnants en matière d'évaluation de modèles de réglage des instructions. Ses capacités multilingues fonctionnent bien dans les tests de référence tels que M-MMLU et MGSM, démontrant le puissant potentiel du modèle de réglage des instructions Qwen2.
Les modèles de la série Qwen2 lancés cette fois marquent un nouveau sommet dans la technologie de l'intelligence artificielle, offrant des possibilités plus larges pour les applications et la commercialisation mondiales de l'IA. En regardant vers l’avenir, Qwen2 étendra encore l’échelle du modèle et les capacités multimodales pour accélérer le développement du domaine de l’IA open source.
Informations sur le modèleLa série Qwen2 comprend 5 tailles de modèles de base et réglés sur commande, notamment Qwen2-0.5B, Qwen2-1.5B, Qwen2-7B, Qwen2-57B-A14B et Qwen2-72B. Nous expliquons les informations clés de chaque modèle dans le tableau ci-dessous :
Modèle Qwen2-0.5BQwen2-1.5BQwen2-7BQwen2-57B-A14BQwen2-72B# Paramètre 049 millions 154 millions 707B57.41B72.71B# Paramètre non-Emb 035 millions 131B598 millions 5632 millions 7021B L'assurance qualité est vraiment vraiment vraiment de vrai vrai lien intégré vrai vrai faux faux faux faux longueur du contexte 32 mille 32 mille 128 mille 64 mille 128 millePlus précisément, dans Qwen1.5, seuls Qwen1.5-32B et Qwen1.5-110B utilisaient Group Query Attention (GQA). Cette fois, nous avons appliqué GQA à toutes les tailles de modèles afin qu'ils bénéficient des avantages de vitesses plus rapides et d'une empreinte mémoire réduite dans l'inférence de modèle. Pour les petits modèles, nous préférons appliquer des plongements liés, car les grands plongements clairsemés représentent une grande partie des paramètres totaux du modèle.
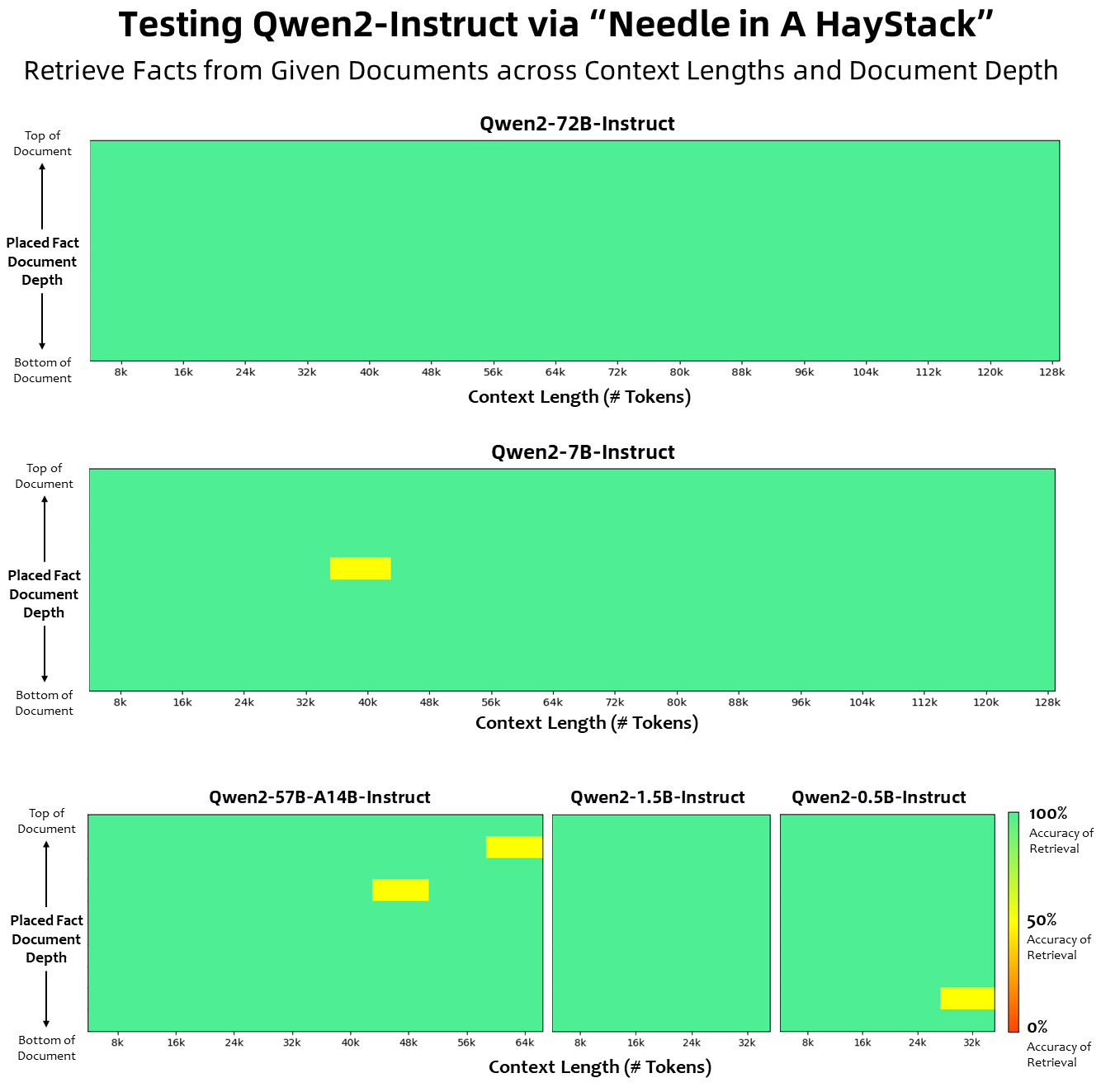
En termes de longueur de contexte, tous les modèles de langage de base ont été pré-entraînés sur des données de longueur de contexte de 32 000 jetons, et nous avons observé des capacités d'extrapolation satisfaisantes jusqu'à 128 000 dans l'évaluation PPL. Cependant, pour les modèles adaptés aux instructions, nous ne nous contentons pas d'une simple évaluation PPL ; nous avons besoin que le modèle soit capable de comprendre correctement le contexte long et d'accomplir la tâche. Dans le tableau, nous répertorions les capacités de longueur de contexte du modèle de réglage des instructions, telles qu'évaluées par l'évaluation de la tâche Needlein a Haystack. Il convient de noter que lorsqu'ils sont améliorés avec YARN, les modèles Qwen2-7B-Instruct et Qwen2-72B-Instruct affichent des capacités impressionnantes et peuvent gérer des longueurs de contexte allant jusqu'à 128 000 jetons.
Nous avons déployé des efforts importants pour augmenter la quantité et la qualité des ensembles de données de pré-formation et d'instruction couvrant plusieurs langues au-delà de l'anglais et du chinois afin d'améliorer ses capacités multilingues. Bien que les grands modèles linguistiques aient la capacité inhérente de se généraliser à d’autres langages, nous soulignons explicitement l’inclusion de 27 autres langages dans notre formation :
Langues régionales Allemagne de l'Ouest, français, espagnol, portugais, italien, néerlandais Europe de l'Est et centrale russe, tchèque, polonais Arabe du Moyen-Orient, persan, hébreu, turc Asiatique de l'Est Japonais, coréen Asie du Sud-Est Vietnamien, thaï, indonésien, malais, Laotien, birman, cebuano, khmer, tagalog, hindi d'Asie du Sud, bengali, ourdouDe plus, nous déployons des efforts considérables pour résoudre les problèmes de transcodage qui surviennent souvent dans les évaluations multilingues. La capacité de notre modèle à gérer ce phénomène est donc considérablement améliorée. Les évaluations utilisant des indices qui provoquent généralement un changement de code entre langues ont confirmé une réduction significative des problèmes associés.
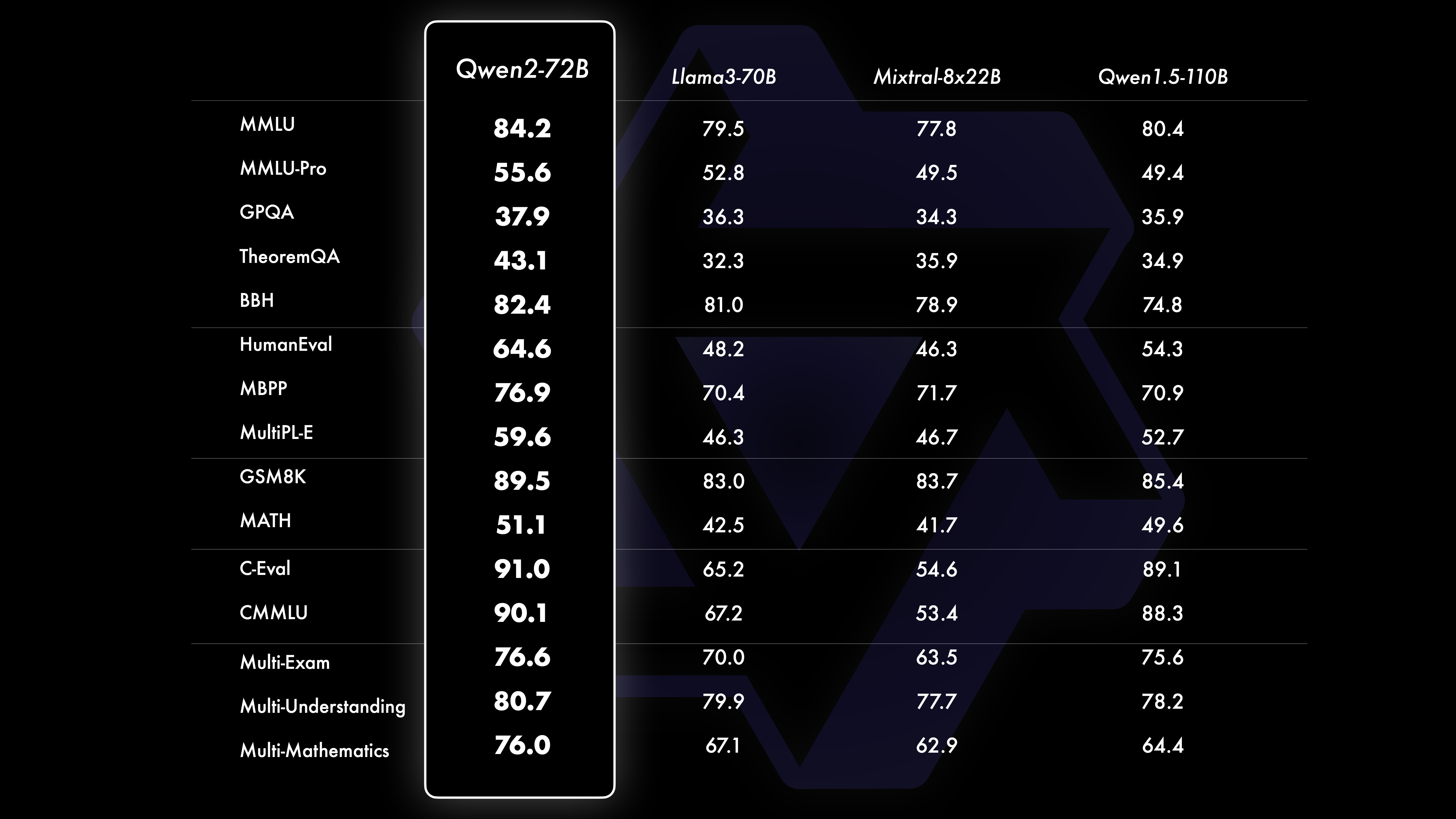
PerformanceLes résultats des tests comparatifs montrent que les performances du modèle à grande échelle (paramètres 70B+) ont été considérablement améliorées par rapport à Qwen1.5. Ce test était centré sur le modèle à grande échelle Qwen2-72B. En termes de modèles de langage de base, nous avons comparé les performances de Qwen2-72B et les meilleurs modèles ouverts actuels en termes de compréhension du langage naturel, d'acquisition de connaissances, de capacités de programmation, de capacités mathématiques, de capacités multilingues et d'autres capacités. Grâce à des ensembles de données soigneusement sélectionnés et à des méthodes de formation optimisées, le Qwen2-72B surpasse les principaux modèles tels que le Llama-3-70B, et surpasse même la génération précédente Qwen1.5- avec un plus petit nombre de paramètres.
Après une pré-formation approfondie à grande échelle, nous effectuons une post-formation pour améliorer encore l'intelligence de Qwen et la rapprocher des humains. Ce processus améliore encore les capacités du modèle dans des domaines tels que le codage, les mathématiques, le raisonnement, le suivi des instructions et la compréhension multilingue. De plus, il aligne les résultats du modèle sur les valeurs humaines, garantissant qu’ils sont utiles, honnêtes et inoffensifs. Notre phase post-formation est conçue selon les principes d'une formation évolutive et d'une annotation humaine minimale. Plus précisément, nous étudions comment obtenir des données de présentation et des données de préférence de haute qualité, fiables, diversifiées et créatives grâce à diverses stratégies d'alignement automatique, telles que l'échantillonnage de rejet pour les mathématiques, le retour d'information sur l'exécution pour le codage et le suivi des instructions, et la rétro-traduction pour l'écriture créative. , une supervision évolutive des jeux de rôle, et bien plus encore. En ce qui concerne la formation, nous utilisons une combinaison de mise au point supervisée, de formation sur le modèle de récompense et de formation DPO en ligne. Nous utilisons également un nouvel optimiseur de fusion en ligne pour minimiser les taxes d'alignement. Ces efforts combinés améliorent considérablement les capacités et l’intelligence de nos modèles, comme le montre le tableau ci-dessous.
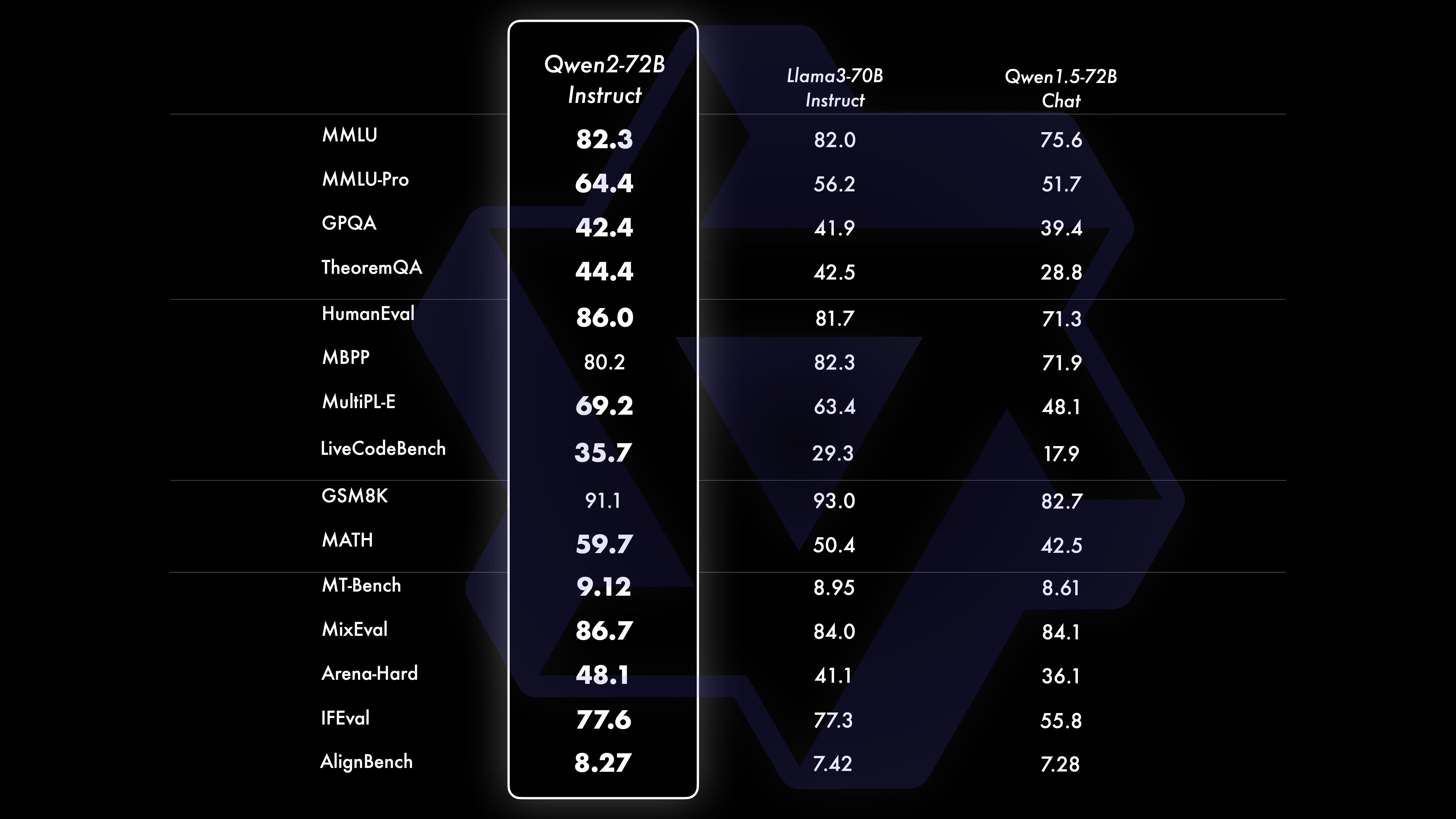
Nous avons mené une évaluation complète de Qwen2-72B-Instruct, couvrant 16 benchmarks dans divers domaines. Qwen2-72B-Instruct établit un équilibre entre l'acquisition de meilleures capacités et la cohérence avec les valeurs humaines. Plus précisément, Qwen2-72B-Instruct surpasse considérablement Qwen1.5-72B-Chat dans tous les benchmarks et atteint également des performances compétitives par rapport à Llama-3-70B-Instruct.
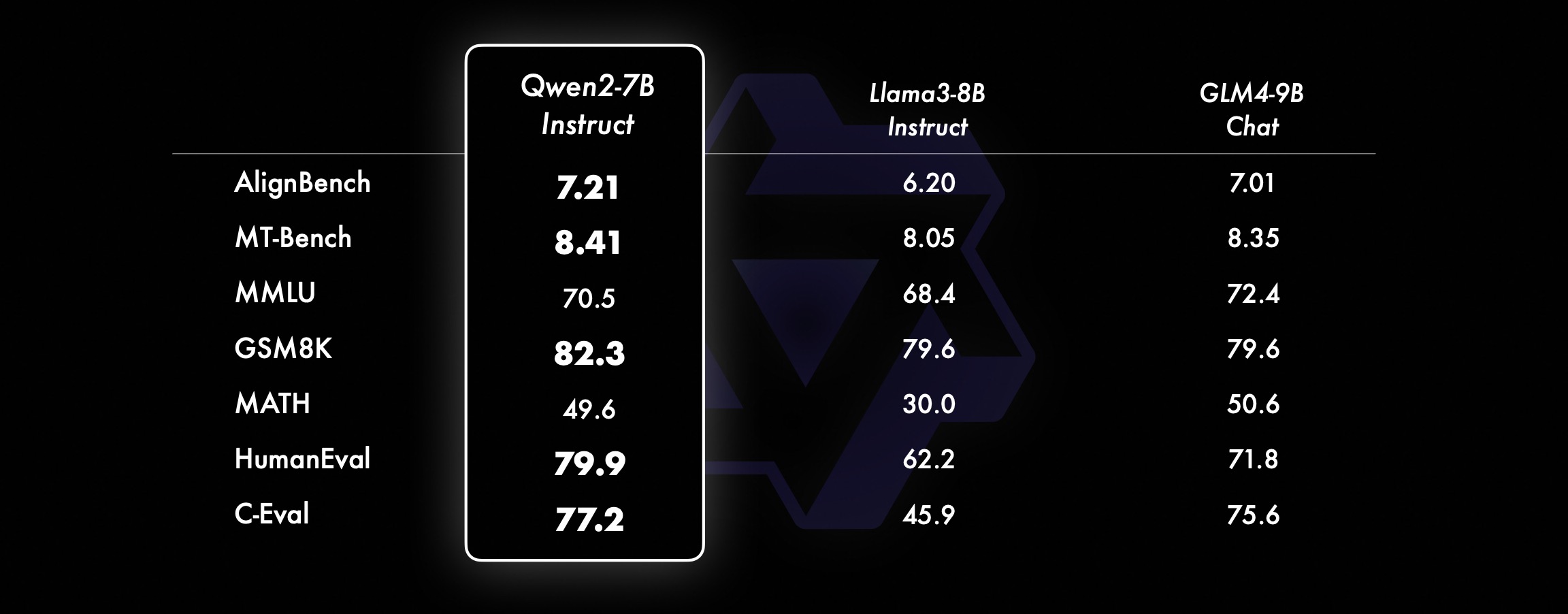
Sur les modèles plus petits, nos modèles Qwen2 surpassent également les modèles SOTA similaires et même de plus grande taille. Par rapport au modèle SOTA qui vient de sortir, Qwen2-7B-Instruct présente toujours des avantages dans divers tests de référence, notamment en termes d'encodage et d'indicateurs liés au chinois.
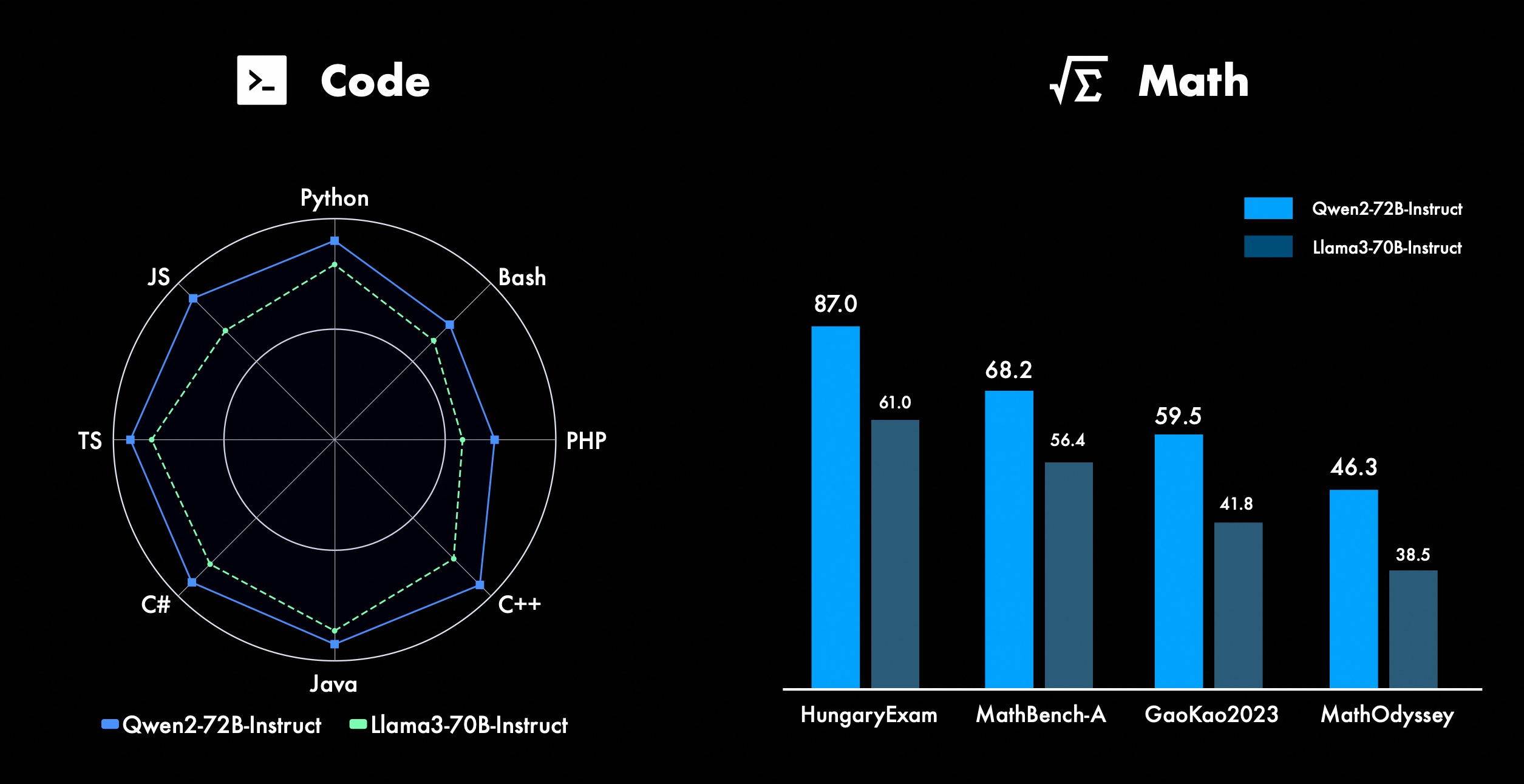
Nous travaillons constamment à l'amélioration des fonctionnalités avancées de Qwen, notamment en matière de codage et de mathématiques. En termes de codage, nous avons intégré avec succès l'expérience de formation au code et les données de CodeQwen1.5, ce qui a permis à Qwen2-72B-Instruct d'obtenir des améliorations significatives dans divers langages de programmation. En mathématiques, Qwen2-72B-Instruct démontre des capacités améliorées de résolution de problèmes mathématiques en exploitant un ensemble de données étendu et de haute qualité.
Dans Qwen2, tous les modèles de réglage des instructions sont formés sur des contextes d'une longueur de 32 000 et extrapolés à des longueurs de contexte plus longues à l'aide de techniques telles que YARN ou Dual Chunk Attention.
L'image ci-dessous montre nos résultats de tests sur Needle in a Haystack. Il convient de noter que Qwen2-72B-Instruct peut parfaitement gérer la tâche d'extraction d'informations dans le contexte 128k. Associé à ses performances puissantes inhérentes, il peut être utilisé lorsque les ressources sont suffisantes. . Dans ce cas, il devient le premier choix pour le traitement de tâches de texte longues.
Par ailleurs, il convient de noter les capacités impressionnantes des autres modèles de la série : le Qwen2-7B-Instruct gère presque parfaitement les contextes jusqu'à 128k, le Qwen2-57B-A14B-Instruct gère les contextes jusqu'à 64k, et la série Les deux les modèles plus petits prennent en charge les contextes 32 000.
En plus du modèle de contexte long, nous avons open source une solution proxy pour un traitement efficace des documents contenant jusqu'à 1 million de balises. Pour plus de détails, consultez notre article de blog dédié à ce sujet.
Le tableau ci-dessous montre la proportion de réponses préjudiciables générées par un grand modèle pour quatre catégories de requêtes multilingues dangereuses (activité illégale, fraude, pornographie, violence privée). Les données de test proviennent de Jailbreak et sont traduites en plusieurs langues pour évaluation. Nous avons constaté que Llama-3 ne gère pas efficacement les signaux multilingues et ne l'avons donc pas inclus dans la comparaison. Grâce au test de signification (P_value), nous avons constaté que les performances de sécurité du modèle Qwen2-72B-Instruct sont équivalentes à celles de GPT-4 et nettement meilleures que celles du modèle Mistral-8x22B.
Langue Activité illégale Fraude Pornographie Violence dans la vie privée GPT-4 Mistral-8x22BQwen2-72B-GuidanceGPT-4 Mistral-8x22BQwen2-72B-GuidanceGPT-4 Mistral-8x22BQwen2-72B-Guidance GPT-4 Mistral-8x22BQwen2-72B-Guide Chinois0%13%0 %0%17%0%43%47%53%0%10%0%Anglais0%7%0%0%23% 0%37%67%63%0%27%3%Créances clients0%13%0% 0%7%0%15%26%15%3%13%0%西文0%7%0%3 %0%0%48%64%50%3%7%3%France0%3%0% 3%3%7%3%19%7%0%27%0%Ke0%4%0%3 %8%4%17%29%10%0%26%4%point0%7%0%3% 7%3%47%57%47%4%26%4%日0%10%0%7 %23%3%13%17%10%13%7%7%六0%4%0%4% 11%0%22%26%22%0%0%0%moyenne0%8%0% 3%11%2%27%39%31%3%16%2% utilisent Qwen2 pour le développementActuellement, tous les modèles ont été publiés dans Hugging Face et ModelScope. Vous êtes invités à visiter la fiche modèle pour voir les méthodes d'utilisation détaillées et en savoir plus sur les caractéristiques, les performances et d'autres informations de chaque modèle.
Depuis longtemps, de nombreux amis ont soutenu le développement de Qwen, notamment la mise au point (Axolotl, Llama-Factory, Firefly, Swift, XTuner), la quantification (AutoGPTQ, AutoAWQ, Neural Compressor), le déploiement (vLLM, SGL, SkyPilot, TensorRT-LLM, OpenVino, TGI), plateforme API (ensemble, Fireworks, OpenRouter), exécution locale (MLX, Llama.cpp, Ollama, LM Studio), agent et framework RAG (LlamaIndex, CrewAI, OpenDevin), évaluation (LMSys, OpenCompass, Open LLM Leaderboard), formation de modèles (Dolphin, Openbuddy), etc. Pour savoir comment utiliser Qwen2 avec des frameworks tiers, veuillez vous référer à leur documentation respective ainsi qu'à notre documentation officielle.

Il existe de nombreuses équipes et individus qui ont contribué à Qwen que nous n’avons pas mentionnés. Nous apprécions sincèrement leur soutien et espérons que notre collaboration favorisera la recherche et le développement dans la communauté de l’IA open source.
licenceCette fois, nous modifions l'autorisation du modèle par une autre. Qwen2-72B et son modèle de réglage des instructions utilisent toujours la licence Qianwen d'origine, tandis que tous les autres modèles, y compris Qwen2-0.5B, Qwen2-1.5B, Qwen2-7B et Qwen2-57B-A14B, sont passés à Apache2.0 !Nous pensons que l'ouverture accrue de notre modèle à la communauté peut accélérer l'application et la commercialisation de Qwen2 dans le monde entier.
Quelle est la prochaine étape pour Qwen2 ?Nous formons un modèle Qwen2 plus grand pour explorer davantage les extensions de modèle ainsi que nos récentes extensions de données. De plus, nous étendons le modèle de langage Qwen2 pour qu'il soit multimodal, capable de comprendre des informations visuelles et audio. Dans un avenir proche, nous continuerons à ouvrir de nouveaux modèles pour accélérer l’IA open source. Restez à l'écoute!
CitationNous publierons bientôt un rapport technique sur Qwen2. Citations bienvenues !
@article{qwen2, Annexe Évaluation du modèle linguistique de baseL'évaluation des modèles de base se concentre principalement sur les performances des modèles telles que la compréhension du langage naturel, la réponse aux questions générales, le codage, les mathématiques, les connaissances scientifiques, le raisonnement et les capacités multilingues.
Les ensembles de données évalués comprennent :
Tâches d'anglais : MMLU (5 fois), MMLU-Pro (5 fois), GPQA (5 fois), Theorem QA (5 fois), BBH (3 fois), HellaSwag (10 fois), Winogrande (5 fois), TruthfulQA ( 0 fois), ARC-C (25 fois)
Tâches de codage : EvalPlus (0-shot) (HumanEval, MBPP, HumanEval+, MBPP+), MultiPL-E (0-shot) (Python, C++, JAVA, PHP, TypeScript, C#, Bash, JavaScript)
Tâches de mathématiques : GSM8K (4 fois), MATH (4 fois)
Tâches chinoises : C-Eval (5 tirs), CMMLU (5 tirs)
Tâches multilingues : examens multiples (M3Exam 5 fois, IndoMMLU 3 fois, ruMMLU 5 fois, mmMLU 5 fois), compréhensions multiples (BELEBELE 5 fois, XCOPA 5 fois, XWinograd 5 fois, XStoryCloze 0 fois, PAWS-X 5 fois) , mathématiques multiples (MGSM 8 fois), traductions multiples (Flores-1015 fois)
Ensemble de données de performances Qwen2-72B DeepSeek-V2Mixtral-8x22BCamel-3-70BQwen1.5-72BQwen1.5-110BQwen2-72BArchitectureMinistère de l'ÉducationDenseDenseDenseDenseDense#Paramètres activés 21B39B70B72B110B72B#Paramètres 236B140B70B7 2B110B72B Anglais Mohrman ·Lu 78.577.879.577.580.484.2MMLU-Professional Edition-49.552. 087.587. .6 Grandes fenêtres 84.885.085.383.083.585.1ARC-C70.070.768.865.969. 668.9 Questions et réponses honnêtes 42.251.045.659.649.654.8 Évaluation du personnel de codage 45.746.348.246.354.364.6 Département de la fonction publique malaisienne 73 .971.770.466.970.976.9 Évaluation 55.054.154.852.957.765.4 Divers 44.446.746.341.852.759.6 Math GSM8K79. 283.783.079.585.489.5 Math 43.641.742.534.149.651.1 Chinois C-Assessment 81.754.665. 284.189.191.0 Université de Montréal, Canada 84.053 .467.283.588.390.1Plusieurs langues et plusieurs examens 67 .563.570.066.475.676.6Compréhensions multiples 77.077.779.978.278.280.7Mathématiques multiples 58.862.967.161.764.476.0Traductions multiples 36.023.338.035.636.2 37.8Qwen2-57B-A14B Ensemble de données Jabba Mixtral-8x7B Instrument-1.5-34BQwen1.5-32 BQwen2-57B-A14B Architecture MoE MoE Dense Dense MoE #Activated Parameters 12B12B34B32B14B #Parameters 52B47B34B32B57B Anglais Moleman Lu 67.471.877.174.376.5MMLU - Édition professionnelle - 41.048.344.043.0 Assurance qualité - 29.2 - 30.834.3 Théorème Q&A - 23. 2 - 28.833.5 Baibei Noir 45.450.376.466.867.0 Shiela Swag 87.186.585.985.085.2 Winogrand 82.581.984.981 .579.5ARC-C64.466.065.663.664.1 Questions et réponses honnêtes 46.451.153.957.457.7 Évaluation de la main-d'œuvre de codage 29.337.246.343.353. 0 Fonction publique Malaisie - 63.965.564.271.9 Évaluation - 46.451 .950.457.2 Divers - 39.03 9.538.549 .8 Mathématiques GSM8K59.962.582.776.880.7 Mathématiques-30.841.736.143.0 Chinois C-Assessment---83.587.7 Université de Montréal, Canada--84.882.388.5 Plusieurs langues et examens multiples-56.158.361.665.5 Compréhension multipartite -70.773.976.577.0Mathématiques multiples -45.049.356.162.3Traduction multiple -29.830.033.534.5Qwen2-7B Ensemble de données Mistral -7B Jemma -7B Camel -3-8BQwen1.5 -7BQwen2-7B# Paramètres 7,2B850 millions 8.0B7.7B7.6B# Paramètres non intégrés 7,0B780 millions 7,0B650 millions 650 millions Anglais Mohrman Lu 64.264.666.661.070.3MMLU-Pro 30.933.735.429.940.0 Assurance qualité 24.725 .725.826. 731.8 Théorème Questions et réponses 19.221.522.114.231.1 Baibei Black 56.155.157.740.262.6 Shiraswager 83.282.282.178.580.7 Winogrand 78.479.077.471.377.0ARC-C60.061.159 .3 54.260.6Questions et réponses honnêtes 42.244 .844.051.154.2 Codage de l'évaluation de la main-d'œuvre 29.337.233.536 .051.2 Fonction publique Malaisie 51.150.653.951.665.9 Évaluation 36.439.640.340.054.2 Multiple 29.429.722.628.146.3 Mathématiques GSM8K52.246.456.0 62.579.9 Mathématiques 13.124.320.520. 344.2 Chine Human C-Assessment 47.443.649.574.183.2 Université de Montréal , Canada -- 50.873.183.9 Examen multiple multilingue 47.142.752.347.759.2 Compréhension multiple 63.358.368.667.672.0 Mathématiques multivariées 26.339.136.337.357.5 Traduction multiple 23.331.231 .928.431.5Qwen2 - Ensemble de données 0,5B et Qwen2-1,5B Phi-2Gemma -2B CPM minimum Qwen1.5-1.8BQwen2-0.5BQwen2-1.5B# Paramètres non-Emb 250 millions 2.0B2.4B1.3B035 millions 1.3 B Mohrman Lu 52.742.353.546.845.456.5MMLU-Professional-15.9--14.721.8 Théorème Questions et réponses ---- 8.915.0 Évaluation des effectifs 47.622.050.020.122.031.1 Département de la fonction publique malaisienne 55.029.247.318.022.037 .4GSM8K57.217.753.838.436.558.5 Math 3.511.810.210.110.72 1.7 Baibi Noir 43.435.236.924.228.437. 2 Shiela Swag 73.171.468.361.449.366.6 Winogrand 74.466.8 -60.356.866.2ARC -C61.148.5-37.931.543.9 Questions et réponses honnêtes 44.533.1-39.439.745.9C - Évaluation 23.428.051.1 59.758.270.6 Université de Montréal, Canada 24.2 - 51.157.855.170.3 Évaluation du modèle de réglage des instructions Qwen2-72B - Ensemble de données guidé Camel - 3-70B - Guidage Qwen1.5-72B - Chat Qwen2-72B - Guidage Anglais Mohr Man Lu 82.075.682.3MMLU - Édition professionnelle 56.251. 764.4 Assurance qualité 41.939.442.4 Questions et réponses sur le théorème 42.528.844.4MT - Bench8.958.619.12 Arena - Difficile 41.136.148.1 IFEval (accès strict rapide) 77.355.877.6 Évaluation des effectifs de codage 81.771.386.0 Fonction publique Malaisie 82,37 1.980.2 Multiples 63.448.169.2 Cotisation 75.266.979.0 Test de code en direct 29.317.935.7 Mathématiques GSM 8K93.082.7 91. 1 Mathématiques 50.442.559.7 Chinois Évaluation C 61.676.183.8AlignBench7.427.288.27Qwen2-57B-A14B-Instruction DatasetMixt ral-8x7B-Instruct-v0.1Yi-1.5 -34B-ChatQwen1.5-32B-ChatQwen2- 57B-A14B - Architecture d'orientation Ministère de l'Éducation Dense Dense Ministère de l'Éducation #Paramètre activé 12B34B32B14B #Paramètre 47B34B32B57B Anglais Mohr Man Lu 71.476.874.875.4MMLU - Édition professionnelle 43.352.346.452 .8 Qualité Assurance -- 30.834.3 Théorème Questions et réponses - -30.933.1MT-Bench8.308.508.308.55 Évaluation des effectifs de codage 45.175.268.379.9 Fonction publique Malaisie 59.574.667.970.9 Divers --50.766.4 Évaluation 48.5-63.671.6 En direct Code Test 12.3-15.225.5 Mathématiques GSM8K65.790.283.679.6 Mathématiques 30.750.142.449.1 Chinois C-Evaluation--76.780.5AlignBench5.707.207.197.36Qwen2-7B-Guide Dataset Camel-3-8B-Guide Yi-1.5-9B -Chat GLM-4- 9B-Chat Qwen1.5-7B-Chat Qwen2-7B-Guide anglais Mohrman Lu 68.469.572.459.570.5MMLU-Pro 41.0--29.144.1 Assurance qualité 34.2--27.825.3 Théorème Q&A 23.0- -14.125 .3MT-Bench8.058.208.357.608.41 Codage humanitaire 62.266.571.846.379.9 Fonction publique Malaisie 67,9--48.967.2 Multiple 48,5--27.259.1 Évaluation 60,9--44.870.3 Test de code en direct 17,3-- 6,0 26. 6 Math GSM8K79.684.879.660.382.3 Math 30.047.750.623.249.6 Évaluation C chinoise 45.9-75.667.377.2 AlignBench6.206.907.016.207.21 Qwen2-0.5B-Instruct et Qwen2-1.5B-Instruct Ensemble de données Qwen 1. 5- 0.5B-Chat Qwen2-0.5B-Guide Qwen1.5-1.8B-Chat Qwen2-1.5B-Guide Morman Lu35.037.943.752.4 Évaluation de la main-d'œuvre 9.117.125.037.8GSM8K11.340.135.361.6C-Évaluation 37.245.255.363.8IF Évaluer ( invite pour un accès strict) La commande 14.620.016.829.0 ajuste les capacités multilingues du modèleNous comparons le modèle de réglage des instructions Qwen2 avec d'autres LLM récents sur plusieurs benchmarks ouverts multilingues ainsi que sur l'évaluation humaine. Pour la référence, nous présentons les résultats sur 2 ensembles de données d’évaluation :
M-MMLU d'Okapi : évaluation multilingue des connaissances générales (nous utilisons des sous-ensembles de ar, de, es, fr, it, nl, ru, uk, vi, zh pour l'évaluation) MGSM : pour l'allemand, l'anglais, l'espagnol, le français et les évaluations de mathématiques en Langues japonaise, russe, thaïlandaise, chinoise et brésilienneLes résultats sont moyennés entre les langues pour chaque benchmark et sont les suivants :
Exemplaire M-MMLU (5 plans) MGSM (0 plan, CoT) Propriétaire LLM GPT-4-061378.087.0GPT-4-Turbo-040979.390.5GPT-4o-051383.289.6 Claude-3-works- 2024022980.191.0 claude-3 -sonnet-2024022971.085.6 commande LL.M open source-r-plus-110b65.563.5Qwen1.5-7B-chat 50.037.0Qwen1.5-32B-chat 65.065.0Qwen1.5 -72B-Chat 68.471.7Qwen2-7B -Guide 60.057.0Qwen2-57B-A14B-Guide 68.074.0Qwen2-72B-Guide 78.086.6Pour une évaluation manuelle, nous comparons Qwen2-72B-Instruct avec GPT3.5, GPT4 et Claude-3-Opus à l'aide d'un ensemble d'évaluation interne, qui comprend 10 langues ar, es, fr, ko, th, vi, pt, id , ja et ru (plage de scores de 1 à 5) :
Modèle Comptes clients Espagnol Français Corri Six Points ID Jiaru Moyenne Claude-3-Works-202402294.154.314.234.234.013.984.094.403.854.254.15GPT-4o-05133.554.264.164.404.094.143.894.3 93.724 .324.09 GPT-4-Turbo- 04093.444.084.194.244.113.843.864.093.684.273.98Qwen2-72B-Guide 3.864.104.014.143.753.913.973.833.634.153.93GPT-4-06133.5 53.923. 943.873.833.953.553.773.063.633.71GPT-3.5-Turbo-11062.524. 073.472.373.382.903.373.562.753.243.16Regroupés par type de tâche, les résultats sont les suivants :
Connaissances du modèle Compréhension Création Mathématiques Claude-3-Works-202402293.644.454.423.81GPT-4o-05133.764.354.453.53GPT-4-Turbo-04093.424.294.353.58Qwen2-72B-Guide3.414.074.363.61GPT- 4 -06133.424.094.103. 32GPT-3.5-Turbo-11063.373.673.892.97Ces résultats démontrent les puissantes capacités multilingues du modèle de réglage des instructions Qwen2.
Les modèles open source de la série Qwen2 d'Alibaba ont considérablement amélioré leurs performances et leurs capacités multilingues, apportant ainsi une contribution importante à la communauté de l'IA open source. À l'avenir, Qwen2 continuera à développer et à étendre davantage l'échelle du modèle et les capacités multimodales, ce qui mérite d'être attendu.