ai toolkit
1.0.0
Ini adalah repo penelitian saya. Saya melakukan banyak eksperimen di dalamnya dan ada kemungkinan saya akan merusak banyak hal. Jika ada yang rusak, periksa komit sebelumnya. Repo ini dapat melatih banyak hal, dan sulit untuk mengikuti semuanya.
Pekerjaan saya pada proyek ini tidak akan mungkin terwujud tanpa dukungan luar biasa dari Glif dan semua orang di tim. Jika Anda ingin mendukung saya, dukung Glif. Bergabunglah dengan situs ini, Bergabunglah dengan kami di Discord, ikuti kami di Twitter dan buatlah beberapa hal keren bersama kami
Persyaratan:
Linux:
git clone https://github.com/ostris/ai-toolkit.git
cd ai-toolkit
git submodule update --init --recursive
python3 -m venv venv
source venv/bin/activate
# .venvScriptsactivate on windows
# install torch first
pip3 install torch
pip3 install -r requirements.txtjendela:
git clone https://github.com/ostris/ai-toolkit.git
cd ai-toolkit
git submodule update --init --recursive
python -m venv venv
. v env S cripts a ctivate
pip install torch torchvision --index-url https://download.pytorch.org/whl/cu121
pip install -r requirements.txtUntuk memulai dengan cepat, lihat tutorial @araminta_k tentang Menyempurnakan Flux Dev pada 3090 dengan VRAM 24 GB.
Saat ini Anda memerlukan GPU dengan VRAM minimal 24 GB untuk melatih FLUX.1. Jika Anda menggunakannya sebagai GPU untuk mengontrol monitor, Anda mungkin perlu menyetel tanda low_vram: true di file konfigurasi di bawah model: . Ini akan mengkuantisasi model pada CPU dan memungkinkannya dilatih dengan monitor terpasang. Pengguna telah membuatnya berfungsi di Windows dengan WSL, tetapi ada beberapa laporan bug saat dijalankan di windows secara asli. Saya hanya menguji di linux untuk saat ini. Ini masih sangat eksperimental dan banyak kuantisasi dan trik yang harus dilakukan agar dapat muat pada 24GB.
FLUX.1-dev memiliki lisensi non-komersial. Artinya, apa pun yang Anda latih akan mewarisi lisensi non-komersial. Ini juga merupakan model yang terjaga keamanannya, jadi Anda harus menerima lisensi HF sebelum menggunakannya. Kalau tidak, ini akan gagal. Berikut adalah langkah-langkah yang diperlukan untuk menyiapkan lisensi.
.env di root pada folder ini.env seperti HF_TOKEN=your_key_hereFLUX.1-schnell adalah Apache 2.0. Apa pun yang dilatih tentangnya dapat dilisensikan sesuai keinginan Anda dan tidak memerlukan HF_TOKEN untuk melatihnya. Namun, hal ini memerlukan adaptor khusus untuk berlatih dengannya, ostris/FLUX.1-schnell-training-adapter. Ini juga sangat eksperimental. Untuk kualitas keseluruhan terbaik, pelatihan tentang FLUX.1-dev direkomendasikan.
Untuk menggunakannya, Anda hanya perlu menambahkan asisten ke bagian model file konfigurasi Anda seperti:
model :
name_or_path : " black-forest-labs/FLUX.1-schnell "
assistant_lora_path : " ostris/FLUX.1-schnell-training-adapter "
is_flux : true
quantize : trueAnda juga perlu menyesuaikan langkah sampel karena schnell tidak memerlukan banyak langkah
sample :
guidance_scale : 1 # schnell does not do guidance
sample_steps : 4 # 1 - 4 works wellconfig/examples/train_lora_flux_24gb.yaml ( config/examples/train_lora_flux_schnell_24gb.yaml untuk schnell) ke folder config dan ganti namanya menjadi whatever_you_want.ymlpython run.py config/whatever_you_want.ymlFolder dengan nama dan folder pelatihan dari file konfigurasi akan dibuat saat Anda memulai. Itu akan memiliki semua pos pemeriksaan dan gambar di dalamnya. Anda dapat menghentikan pelatihan kapan saja menggunakan ctrl+c dan ketika Anda melanjutkan, pelatihan akan diambil kembali dari pos pemeriksaan terakhir.
PENTING. Jika Anda menekan crtl+c saat sedang menyimpan, kemungkinan besar pos pemeriksaan tersebut akan rusak. Jadi tunggu sampai selesai menyimpan
Harap jangan membuka laporan bug kecuali itu adalah bug dalam kode. Anda dipersilakan untuk Bergabung dengan Perselisihan saya dan meminta bantuan di sana. Namun, harap jangan mengirimi saya pesan langsung dengan pertanyaan umum atau dukungan. Tanyakan di perselisihan dan saya akan menjawab ketika saya bisa.
Untuk memulai pelatihan secara lokal dengan UI khusus, setelah Anda mengikuti langkah-langkah di atas dan ai-toolkit diinstal:
cd ai-toolkit # in case you are not yet in the ai-toolkit folder
huggingface-cli login # provide a `write` token to publish your LoRA at the end
python flux_train_ui.py Anda akan membuat instance UI yang memungkinkan Anda mengunggah gambar, memberi teks, melatih, dan mempublikasikan LoRA Anda 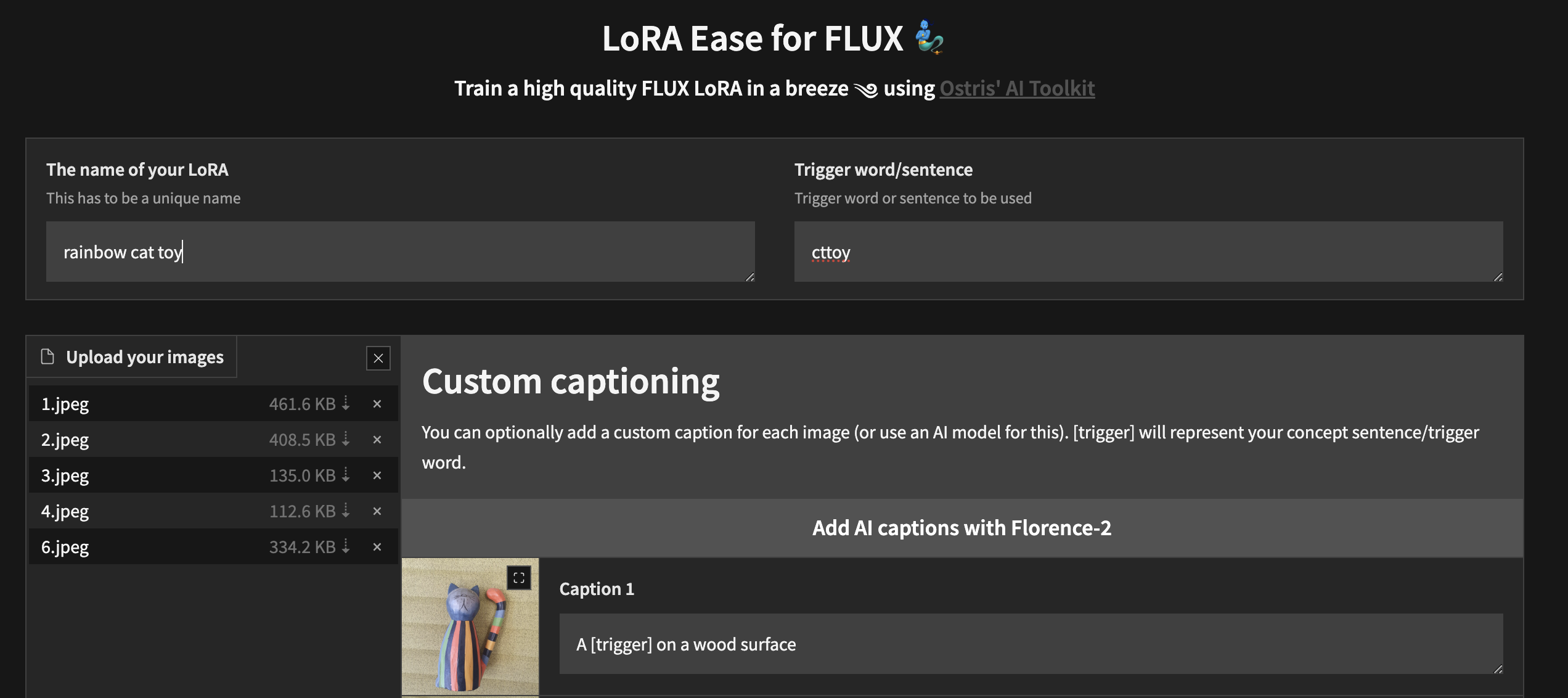
Contoh templat RunPod: runpod/pytorch:2.2.0-py3.10-cuda12.1.1-devel-ubuntu22.04
Anda memerlukan minimal VRAM 24GB, pilih GPU sesuai keinginan Anda.
git clone https://github.com/ostris/ai-toolkit.git
cd ai-toolkit
git submodule update --init --recursive
python -m venv venv
source venv/bin/activate
pip install torch
pip install -r requirements.txt
pip install --upgrade accelerate transformers diffusers huggingface_hub #Optional, run it if you run into issues
dataset atau apa pun yang Anda suka.huggingface-cli login dan tempelkan token Anda.config/examples ke folder config dan ganti namanya menjadi whatever_you_want.yml .folder_path: "/path/to/images/folder" ke jalur kumpulan data Anda seperti folder_path: "/workspace/ai-toolkit/your-dataset" .python run.py config/whatever_you_want.yml .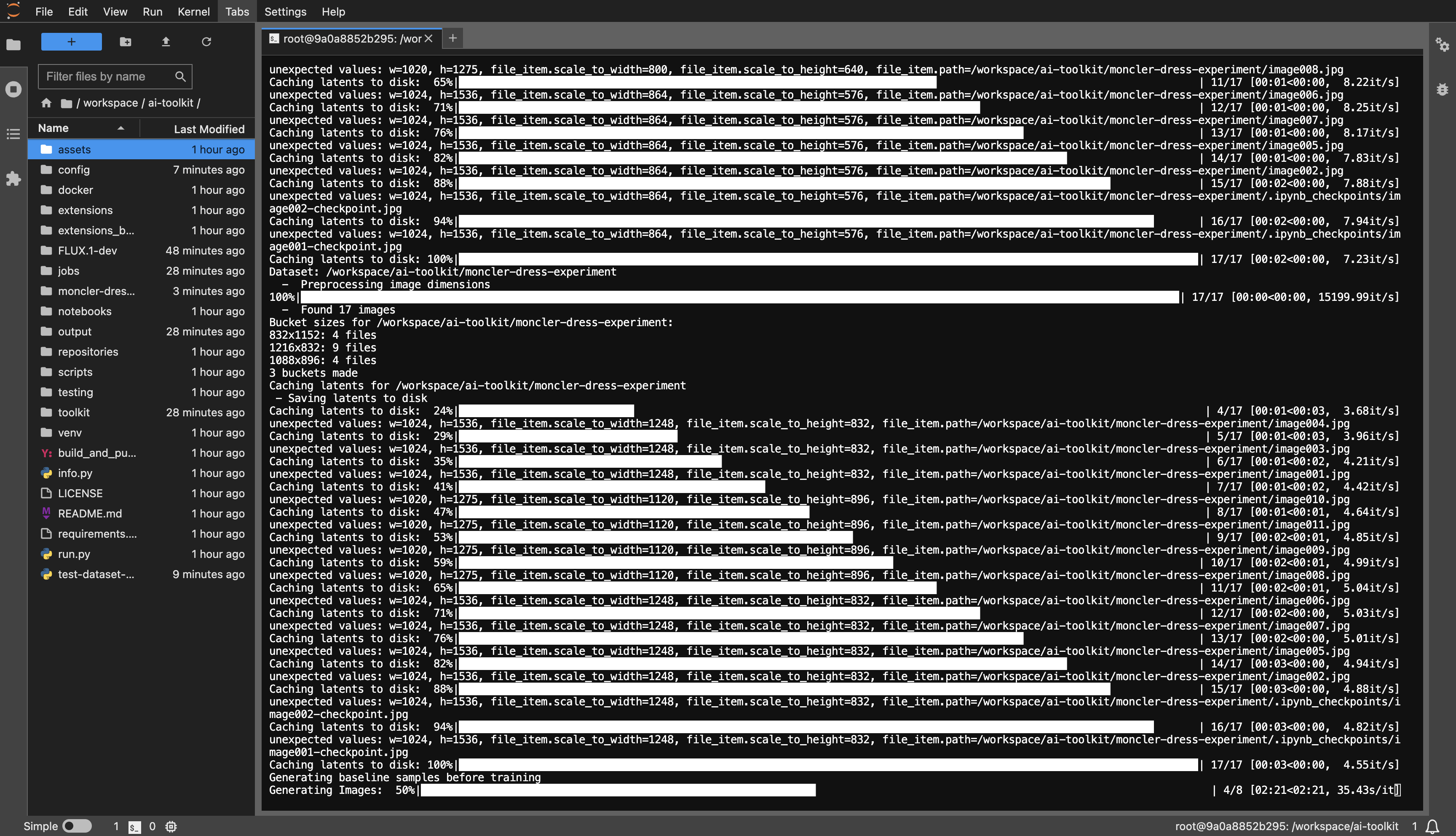
git clone https://github.com/ostris/ai-toolkit.git
cd ai-toolkit
git submodule update --init --recursive
python -m venv venv
source venv/bin/activate
pip install torch
pip install -r requirements.txt
pip install --upgrade accelerate transformers diffusers huggingface_hub #Optional, run it if you run into issues
pip install modal untuk menginstal paket modal Python.modal setup untuk mengautentikasi (jika tidak berhasil, coba python -m modal setup ). huggingface-cli login dan tempelkan token Anda.ai-toolkit .config/examples/modal ke folder config dan ganti namanya menjadi whatever_you_want.yml ./root/ai-toolkit . Tetapkan seluruh jalur ai-toolkit lokal Anda di code_mount = modal.Mount.from_local_dir seperti:
code_mount = modal.Mount.from_local_dir("/Users/username/ai-toolkit", remote_path="/root/ai-toolkit")
Pilih GPU dan Timeout di @app.function (defaultnya adalah A100 40GB dan timeout 2 jam) .
modal run run_modal.py --config-file-list-str=/root/ai-toolkit/config/whatever_you_want.yml .Storage > flux-lora-models .modal volume ls flux-lora-models .modal volume get flux-lora-models your-model-name .modal volume get flux-lora-models my_first_flux_lora_v1 .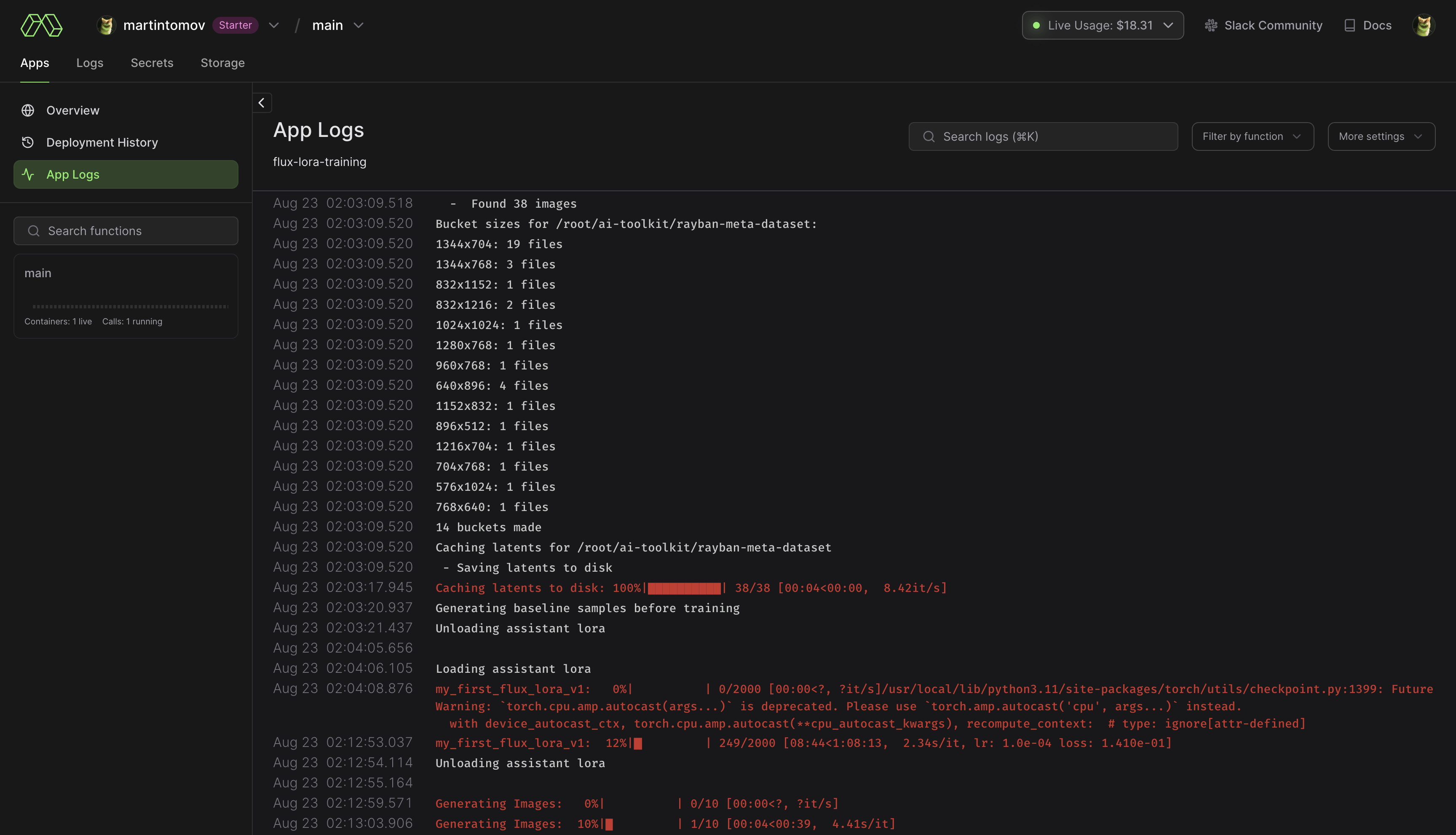
Kumpulan data umumnya harus berupa folder yang berisi gambar dan file teks terkait. Saat ini, satu-satunya format yang didukung adalah jpg, jpeg, dan png. Webp saat ini mengalami masalah. File teks harus diberi nama yang sama dengan gambar tetapi dengan ekstensi .txt . Misalnya image2.jpg dan image2.txt . File teks hanya boleh berisi keterangan. Anda dapat menambahkan kata [trigger] di file caption dan jika Anda memiliki trigger_word di konfigurasi Anda, maka secara otomatis akan diganti.
Gambar tidak pernah ditingkatkan skalanya tetapi diperkecil dan ditempatkan dalam wadah untuk dikelompokkan. Anda tidak perlu memotong/mengubah ukuran gambar Anda . Pemuat akan secara otomatis mengubah ukurannya dan dapat menangani berbagai rasio aspek.
Untuk melatih lapisan tertentu dengan LoRA, Anda dapat menggunakan kwarg jaringan only_if_contains . Misalnya, jika Anda ingin melatih hanya 2 lapisan yang digunakan oleh The Last Ben, yang disebutkan dalam postingan ini, Anda dapat menyesuaikan kwarg jaringan Anda seperti:
network :
type : " lora "
linear : 128
linear_alpha : 128
network_kwargs :
only_if_contains :
- " transformer.single_transformer_blocks.7.proj_out "
- " transformer.single_transformer_blocks.20.proj_out " Konvensi penamaan lapisan berada dalam format diffuser, jadi memeriksa dikt status model akan menampilkan akhiran nama lapisan yang ingin Anda latih. Anda juga dapat menggunakan metode ini untuk hanya melatih kelompok beban tertentu. Misalnya untuk hanya melatih single_transformer untuk FLUX.1, Anda dapat menggunakan yang berikut ini:
network :
type : " lora "
linear : 128
linear_alpha : 128
network_kwargs :
only_if_contains :
- " transformer.single_transformer_blocks. " Anda juga dapat mengecualikan lapisan berdasarkan namanya dengan menggunakan kwarg jaringan ignore_if_contains . Jadi untuk mengecualikan semua blok trafo tunggal,
network :
type : " lora "
linear : 128
linear_alpha : 128
network_kwargs :
ignore_if_contains :
- " transformer.single_transformer_blocks. " ignore_if_contains lebih diprioritaskan daripada only_if_contains . Jadi jika suatu beban ditanggung oleh keduanya, maka akan diabaikan.
Ini mungkin masih berfungsi seperti itu, tetapi saya sudah lama tidak mengujinya.
Generator gambar yang dapat mengambil dari file konfigurasi atau membentuk file txt dan menghasilkannya ke folder. Saya terutama membutuhkan ini untuk tes SDXL yang saya lakukan tetapi menambahkan beberapa penyempurnaan sehingga dapat digunakan untuk menghasilkan gambar batch. Semuanya menjalankan file konfigurasi, yang dapat Anda temukan contohnya di config/examples/generate.example.yaml . Info selengkapnya ada di kolom komentar pada contoh
Ini didasarkan pada ekstraktor di alat LyCORIS, tetapi menambahkan beberapa fitur QOL dan dukungan LoRA (lierla). Itu dapat melakukan beberapa jenis ekstraksi dalam satu kali proses. Semuanya menjalankan file konfigurasi, yang dapat Anda temukan contohnya di config/examples/extract.example.yml . Cukup salin file itu, ke folder config , dan ganti namanya menjadi whatever_you_want.yml . Kemudian Anda dapat mengedit file tersebut sesuai keinginan Anda. dan menyebutnya seperti ini:
python3 run.py config/whatever_you_want.ymlAnda juga dapat meletakkan path lengkap ke file konfigurasi, jika Anda ingin menyimpannya di tempat lain.
python3 run.py " /home/user/whatever_you_want.yml "Catatan lebih lanjut tentang cara kerjanya tersedia di contoh file konfigurasi itu sendiri. LoRA dan LoCON keduanya mendukung ekstraksi 'tetap', 'ambang batas', 'rasio', 'kuantil'. Saya akan memperbarui apa fungsi dan maksudnya nanti. Kebanyakan orang menggunakan metode tetap, yang merupakan ekstraksi dimensi tetap tradisional.
process adalah serangkaian proses berbeda untuk dijalankan. Anda dapat menambahkan beberapa dan mencampur dan mencocokkan. Satu LoRA, satu LyCON, dll.
Ubah <lora:my_lora:4.6> menjadi <lora:my_lora:1.0> atau apa pun yang Anda inginkan dengan efek yang sama. Alat untuk mengubah skala bobot LoRA. Seharusnya bisa dengan LoCON juga, tapi saya belum mengujinya. Semuanya menjalankan file konfigurasi, yang dapat Anda temukan contohnya di config/examples/mod_lora_scale.yml . Cukup salin file itu, ke folder config , dan ganti namanya menjadi whatever_you_want.yml . Kemudian Anda dapat mengedit file tersebut sesuai keinginan Anda. dan menyebutnya seperti ini:
python3 run.py config/whatever_you_want.ymlAnda juga dapat meletakkan path lengkap ke file konfigurasi, jika Anda ingin menyimpannya di tempat lain.
python3 run.py " /home/user/whatever_you_want.yml "Catatan lebih lanjut tentang cara kerjanya tersedia di contoh file konfigurasi itu sendiri. Ini berguna saat membuat semua LoRA, karena berat ideal jarang sekali yang mencapai 1,0, namun sekarang Anda dapat memperbaikinya. Untuk penggeser, mereka dapat memiliki skala yang aneh dalam bentuk -2 hingga 2 atau bahkan -15 hingga 15. Ini akan memungkinkan Anda untuk membaginya sehingga semuanya memiliki skala yang Anda inginkan
Ini adalah cara saya melatih sebagian besar slider terbaru yang saya miliki di Civitai, Anda dapat memeriksanya di profil Civitai saya. Ini didasarkan pada karya p1atdev/LECO dan rohitgandikota/erasing Namun telah banyak dimodifikasi untuk membuat bilah geser daripada menghapus konsep. Saya punya lebih banyak rencana mengenai hal ini, tetapi ini sangat fungsional. Ini juga sangat mudah digunakan. Cukup salin contoh file konfigurasi di config/examples/train_slider.example.yml ke folder config dan ganti namanya menjadi whatever_you_want.yml . Kemudian Anda dapat mengedit file tersebut sesuai keinginan Anda. dan menyebutnya seperti ini:
python3 run.py config/whatever_you_want.ymlAda lebih banyak informasi dalam file contoh itu. Anda bahkan dapat menjalankan contoh apa adanya tanpa modifikasi apa pun untuk melihat cara kerjanya. Ini akan membuat penggeser yang mengubah semua hewan menjadi anjing (neg) atau kucing (pos). Jalankan saja seperti ini:
python3 run.py config/examples/train_slider.example.ymlDan Anda akan dapat melihat cara kerjanya tanpa mengonfigurasi apa pun. Tidak diperlukan kumpulan data untuk metode ini. Saya akan segera memposting tutorial yang lebih baik.
Anda sekarang dapat membuat dan berbagi ekstensi khusus. Itu berjalan dalam kerangka ini dan memiliki semua alat bawaan yang tersedia untuk mereka. Saya mungkin akan menggunakan ini sebagai metode pengembangan utama di masa mendatang, jadi saya tidak terus-menerus menambahkan dan menambahkan lebih banyak fitur ke repo dasar ini. Saya mungkin juga akan memigrasikan banyak fungsi yang ada untuk menjadikan semuanya modular. Ada contoh ekstensi di folder extensions yang menunjukkan cara membuat ekstensi penggabungan model. Semua kode didokumentasikan dengan baik dan semoga cukup untuk membantu Anda memulai. Untuk membuat ekstensi, cukup salin contoh itu dan ganti semua yang Anda perlukan.
Itu terletak di folder extensions . Ini adalah penggabungan model yang sepenuhnya final yang dapat menggabungkan model sebanyak yang Anda inginkan. Ini adalah contoh bagus tentang cara membuat ekstensi, namun juga merupakan fitur yang cukup berguna karena sebagian besar merger hanya dapat melakukan satu model pada satu waktu dan yang satu ini akan memerlukan sebanyak yang Anda inginkan untuk memasukkannya. Ada contoh file konfigurasi di sana, cukup salin ke folder config Anda dan ganti namanya menjadi whatever_you_want.yml . dan menggunakannya seperti file konfigurasi lainnya.
Ini berfungsi, tetapi belum siap untuk digunakan orang lain dan oleh karena itu tidak memiliki contoh konfigurasi. Saya masih mengerjakannya. Saya akan memperbarui ini jika sudah siap. Saya menambahkan banyak fitur untuk kriteria yang saya gunakan dalam pekerjaan pembesaran gambar saya. Kritikus (diskriminator), kehilangan konten, kehilangan gaya, dan masih banyak lagi. Jika Anda tidak tahu, VAE untuk difusi stabil (ya bahkan yang MSE, dan SDXL), sangat buruk pada permukaan yang lebih kecil dan menahan SD. Saya akan memperbaikinya. Saya akan memposting lebih banyak tentang ini nanti dengan contoh yang lebih baik nanti, tetapi berikut ini adalah tes cepat yang dijalankan dengan berbagai VAE. Baru saja masuk dan keluar. Ini jauh lebih buruk pada wajah yang lebih kecil daripada yang ditunjukkan di sini.
extensions . Baca lebih lanjut tentang itu di atas.Refactor besar lainnya untuk membuat SD lebih modular.
Membuat skrip pembuatan gambar batch
Perubahan dan pembaruan besar. Alat penskalaan ulang LoRA baru, lihat di atas untuk detailnya. Menambahkan metadata yang lebih baik sehingga Automatic1111 mengetahui model dasarnya. Menambahkan beberapa eksperimen dan banyak pembaruan. Hal ini masih belum stabil saat ini, jadi mudah-mudahan tidak ada perubahan yang mengganggu.
Sayangnya, saya terlalu malas untuk menulis changelog yang tepat dengan semua perubahannya.
Saya menambahkan pelatihan SDXL ke slider... tapi.. itu tidak berfungsi dengan baik. Pelatihan penggeser bergantung pada kemampuan model untuk memahami bahwa perintah tanpa syarat (perintah negatif) berarti Anda tidak ingin konsep tersebut ada dalam keluaran. SDXL tidak memahami hal ini karena alasan apa pun, sehingga sulit memisahkan konsep dalam model. Saya yakin komunitas akan menemukan cara untuk memperbaikinya seiring berjalannya waktu, namun untuk saat ini, hal tersebut tidak akan berfungsi dengan baik. Dan jika ada di antara Anda yang berpikir, "Bisakah kami memperbaikinya dengan menambahkan 1 atau 2 pembuat enkode teks lagi ke model serta beberapa jaringan difusi yang sepenuhnya terpisah?" Tidak. Tuhan tidak. Ini hanya membutuhkan sedikit pelatihan tanpa menambahkan setiap makalah eksperimental baru ke dalamnya. Kepala sekolah KISS.
Menambahkan "jangkar" ke pelatih penggeser. Ini memungkinkan Anda untuk mengatur prompt yang akan digunakan sebagai pengatur. Anda dapat mengatur pengganda jaringan untuk memaksakan konsistensi penyebaran pada bobot yang tinggi


