datablations
1.0.0
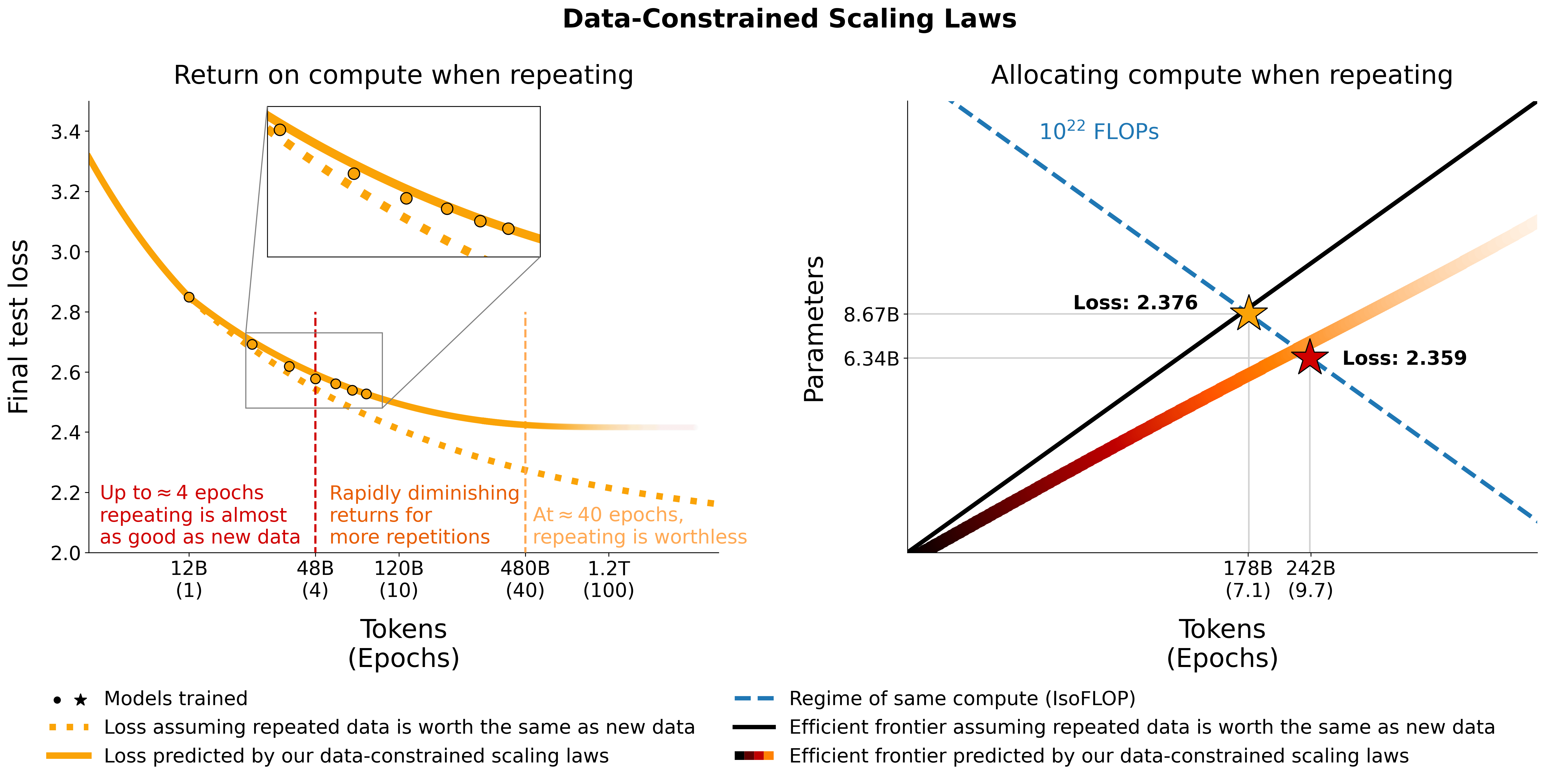
Repositori ini memberikan gambaran umum semua komponen dari makalah Scaling Data-Constrained Language Model. Pembicaraan di atas kertas:
Kami menyelidiki penskalaan model bahasa dalam rezim yang datanya terbatas. Kami menjalankan serangkaian eksperimen dalam jumlah besar yang bervariasi dalam tingkat pengulangan data dan anggaran komputasi, berkisar hingga 900 miliar token pelatihan dan 9 miliar model parameter. Berdasarkan proses yang kami lakukan, kami mengusulkan dan memvalidasi secara empiris hukum penskalaan untuk optimalitas komputasi yang memperhitungkan penurunan nilai token berulang dan parameter berlebih. Kami juga bereksperimen dengan pendekatan untuk memitigasi kelangkaan data, termasuk menambah kumpulan data pelatihan dengan data kode, pemfilteran kebingungan, dan deduplikasi. Model dan kumpulan data dari 400 pelatihan kami tersedia melalui repositori ini.
Kami bereksperimen dengan pengulangan data pada C4 dan pemisahan OSCAR bahasa Inggris yang tidak diduplikasi. Untuk setiap kumpulan data, kami mengunduh data dan mengubahnya menjadi satu file jsonl, masing-masing c4.jsonl dan oscar_en.jsonl .
Kemudian kami memutuskan jumlah token unik dan jumlah sampel yang kami perlukan dari kumpulan data. Perhatikan bahwa C4 memiliki 478.625834583 token per sampel dan OSCAR memiliki 1312.0951072 dengan GPT2Tokenizer. Ini dihitung dengan memberi token pada seluruh kumpulan data dan membagi jumlah token dengan jumlah sampel. Kami menggunakan angka-angka ini untuk menghitung sampel yang dibutuhkan.
Misalnya, untuk token unik 1,9B, kita memerlukan 1.9B / 478.625834583 = 3969697.96178 sampel untuk C4 dan 1.9B / 1312.0951072 = 1448065.76107 sampel untuk OSCAR. Untuk memberi token pada data, pertama-tama kita perlu mengkloning repositori Megatron-DeepSpeed dan mengikuti panduan pengaturannya. Kami kemudian memilih sampel ini dan memberi tokenisasi sebagai berikut:
C4:
head -n 3969698 c4.jsonl > c4_1b9.jsonl
python Megatron-DeepSpeed/tools/preprocess_data_many_cores.py
--input c4_1b9.jsonl
--output-prefix gpt2tok_c4_en_1B9
--dataset-impl mmap
--tokenizer-type PretrainedFromHF
--tokenizer-name-or-path gpt2
--append-eod
--workers 64OSCAR:
head -n 1448066 oscar_en.jsonl > oscar_1b9.jsonl
python Megatron-DeepSpeed/tools/preprocess_data_many_cores.py
--input oscar_1b9.jsonl
--output-prefix gpt2tok_oscar_en_1B9
--dataset-impl mmap
--tokenizer-type PretrainedFromHF
--tokenizer-name-or-path gpt2
--append-eod
--workers 64 di mana gpt2 menunjuk ke folder yang berisi semua file dari https://huggingface.co/gpt2/tree/main. Dengan menggunakan head kami memastikan bahwa subset yang berbeda akan memiliki sampel yang tumpang tindih untuk mengurangi keacakan.
Untuk evaluasi selama pelatihan dan evaluasi akhir, kami menggunakan set validasi untuk C4:
from datasets import load_dataset
load_dataset ( "c4" , "en" , split = "validation" ). to_json ( "c4-en-validation.json" )python Megatron-DeepSpeed/tools/preprocess_data_many_cores.py
--input c4-en-validation.jsonl
--output-prefix gpt2tok_c4validation_rerun
--dataset-impl mmap
--tokenizer-type PretrainedFromHF
--tokenizer-name-or-path gpt2
--append-eod
--workers 2 Untuk OSCAR yang tidak memiliki set validasi resmi, kami mengambil bagian dari set pelatihan dengan melakukan tail -364608 oscar_en.jsonl > oscarvalidation.jsonl dan kemudian melakukan tokenisasi sebagai berikut:
python Megatron-DeepSpeed/tools/preprocess_data_many_cores.py --input oscarvalidation.jsonl --output-prefix gpt2tok_oscarvalidation --dataset-impl mmap --tokenizer-type PretrainedFromHF --tokenizer-name-or-path gpt2 --append-eod --workers 2Kami telah mengunggah beberapa subset yang telah diproses sebelumnya untuk digunakan dengan megatron:
Beberapa file bin terlalu besar untuk git dan karenanya dipecah menggunakan misalnya split --number=l/40 gpt2tok_c4_en_1B9.bin gpt2tok_c4_en_1B9.bin. dan split --number=l/40 gpt2tok_oscar_en_1B9.bin gpt2tok_oscar_en_1B9.bin. . Untuk menggunakannya dalam pelatihan, Anda perlu menyatukannya kembali menggunakan cat gpt2tok_c4_en_1B9.bin.* > gpt2tok_c4_en_1B9.bin dan cat gpt2tok_oscar_en_1B9.bin.* > gpt2tok_oscar_en_1B9.bin .
Kami bereksperimen dengan mencampurkan kode dengan data bahasa alami menggunakan pemisahan Python dari the-stack-dedup. Kami mengunduh data, mengubahnya menjadi satu file jsonl dan memprosesnya terlebih dahulu menggunakan pendekatan yang sama seperti diuraikan di atas.
Kami telah mengunggah versi praproses untuk digunakan dengan megatron di sini: https://huggingface.co/datasets/datablations/python-megatron. Kami telah membagi file bin menggunakan split --number=l/40 gpt2tok_python_content_document.bin gpt2tok_python_content_document.bin. , jadi Anda perlu menyatukannya kembali menggunakan cat gpt2tok_python_content_document.bin.* > gpt2tok_python_content_document.bin untuk pelatihan.
Kami membuat versi C4 dan OSCAR dengan metadata pemfilteran terkait kebingungan dan deduplikasi:
Untuk membuat ulang kumpulan data metadata ini, ada instruksi di filtering/README.md .
Kami menyediakan versi token yang dapat digunakan untuk pelatihan dengan Megatron di:
File .bin dipecah menggunakan sesuatu seperti split --number=l/10 gpt2tok_oscar_en_perplexity_25_text_document.bin gpt2tok_oscar_en_perplexity_25_text_document.bin. , jadi Anda perlu menggabungkannya kembali melalui cat gpt2tok_oscar_en_perplexity_25_text_document.bin. > gpt2tok_oscar_en_perplexity_25_text_document.bin .
Untuk membuat ulang versi token berdasarkan kumpulan data metadata,
filtering/deduplication/filter_oscar_jsonl.pyUntuk membuat persentil kebingungan, ikuti petunjuk di bawah ini.
C4:
from datasets import load_dataset
import numpy as np
ds = load_dataset ( "datablations/c4-filter" , streaming = False , num_proc = 128 )
p_25 = np . percentile ( ds [ "train" ][ "perplexity" ], 25 )
p_50 = np . percentile ( ds [ "train" ][ "perplexity" ], 50 )
p_75 = np . percentile ( ds [ "train" ][ "perplexity" ], 75 )
# 25 - 75th percentile
ds [ "train" ]. filter ( lambda x : p_25 < x [ "perplexity" ] < p_75 , num_proc = 128 ). to_json ( "c4_perplexty2575.jsonl" , num_proc = 128 , force_ascii = False )
# 25th percentile
ds [ "train" ]. filter ( lambda x : x [ "perplexity" ] < p_25 , num_proc = 128 ). to_json ( "c4_perplexty25.jsonl" , num_proc = 128 , force_ascii = False )
# 50th percentile
ds [ "train" ]. filter ( lambda x : x [ "perplexity" ] < p_50 , num_proc = 128 ). to_json ( "c4_perplexty50.jsonl" , num_proc = 128 , force_ascii = False )OSCAR:
from datasets import load_dataset
import numpy as np
ds = load_dataset ( "datablations/oscar-filter" , use_auth_token = True , streaming = False , num_proc = 128 )
p_25 = np . percentile ( ds [ "train" ][ "perplexity_score" ], 25 )
p_50 = np . percentile ( ds [ "train" ][ "perplexity_score" ], 50 )
# 25th percentile
ds [ "train" ]. filter ( lambda x : x [ "perplexity_score" ] < p_25 , num_proc = 128 ). remove_columns ([ 'meta' , 'perplexity_score' , 'text_length' , 'url' , 'domain' , 'dup_ratio' , 'pairs' , 'repetitions' , 'included_in_dedup' , 'cluster' , 'id' ]). to_json ( "oscar_perplexity25.jsonl" , num_proc = 128 , force_ascii = False )
# 50th percentile
ds [ "train" ]. filter ( lambda x : x [ "perplexity_score" ] < p_50 , num_proc = 128 ). remove_columns ([ 'meta' , 'perplexity_score' , 'text_length' , 'url' , 'domain' , 'dup_ratio' , 'pairs' , 'repetitions' , 'included_in_dedup' , 'cluster' , 'id' ]). to_json ( "oscar_perplexity50.jsonl" , num_proc = 128 , force_ascii = False )Anda kemudian dapat memberi token pada file jsonl yang dihasilkan untuk pelatihan dengan Megatron seperti yang dijelaskan di bagian Pengulangan.
C4: Untuk C4 Anda hanya perlu menghapus semua sampel di mana bidang repetitions diisi, melalui misalnya
from datasets import load_dataset
import numpy as np
ds = load_dataset ( "datablations/c4-dedup" , use_auth_token = True , streaming = False , num_proc = 128 )
ds . filter ( lambda x : not ( x [ "repetitions" ]). to_json ( 'c4_dedup.jsonl' , num_proc = 128 , force_ascii = False ) OSCAR: Untuk OSCAR kami menyediakan skrip di filtering/filter_oscar_jsonl.py untuk membuat kumpulan data yang dihapus duplikatnya dengan mempertimbangkan kumpulan data dengan metadata pemfilteran.
Anda kemudian dapat memberi token pada file jsonl yang dihasilkan untuk pelatihan dengan Megatron seperti yang dijelaskan di bagian Pengulangan.
Semua model dapat diunduh di https://huggingface.co/datablations.
Model umumnya diberi nama sebagai berikut: lm1-{parameters}-{tokens}-{unique_tokens} , khususnya masing-masing model dalam folder diberi nama sebagai: {parameters}{tokens}{unique_tokens}{optional specifier} , misalnya 1b12b8100m adalah 1,1 miliar param, 2,8 miliar token, 100 juta token unik. Konvensi xby ( 1b1 , 2b8 dll.) menimbulkan beberapa ambiguitas apakah angka termasuk dalam parameter atau token, tetapi Anda selalu dapat memeriksa skrip sbatch di folder masing-masing untuk melihat parameter / token / token unik yang tepat. Jika Anda ingin mengonversi model yang belum dikonversi menjadi huggingface/transformers , Anda dapat mengikuti petunjuk di Pelatihan.
Cara termudah untuk mengunduh satu model misalnya:
GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/datablations/lm1-misc
cd lm1-misc ; git lfs pull --include 146m14b400m/global_step21553 Jika ini memakan waktu terlalu lama, Anda juga dapat menggunakan wget untuk langsung mengunduh file satu per satu dari folder tersebut, misalnya:
wget https://huggingface.co/datablations/lm1-misc/resolve/main/146m14b400m/global_step21553/bf16_zero_pp_rank_0_mp_rank_00_optim_states.ptUntuk model yang sesuai dengan eksperimen di makalah, lihat repositori berikut:
lm1-misc/*dedup* untuk perbandingan deduplikasi pada 100 juta token unik di lampiranModel lain yang tidak dianalisis dalam makalah ini:
Kami melatih model dengan cabang Megatron-DeepSpeed yang bekerja dengan GPU AMD (melalui ROCm): https://github.com/TurkuNLP/Megatron-DeepSpeed Jika Anda ingin menggunakan GPU NVIDIA (melalui cuda), Anda dapat menggunakan perpustakaan asli: https://github.com/bigscience-workshop/Megatron-DeepSpeed
Anda harus mengikuti instruksi pengaturan dari salah satu repositori untuk menciptakan lingkungan Anda (Pengaturan kami yang khusus untuk LUMI dirinci dalam training/megdssetup.md ).
Setiap folder model berisi skrip sbatch yang digunakan untuk melatih model. Anda dapat menggunakan ini sebagai referensi untuk melatih model Anda sendiri dalam mengadaptasi variabel lingkungan yang diperlukan. Skrip sbatch mereferensikan beberapa file tambahan:
*txt yang menentukan jalur data. Anda dapat menemukannya di utils/datapaths/* , namun, Anda mungkin perlu menyesuaikan jalur untuk menunjuk ke kumpulan data Anda.model_params.sh , yang ada di utils/model_params.sh dan berisi preset arsitektur.launch.sh yang dapat Anda temukan di training/launch.sh . Ini berisi perintah khusus untuk pengaturan kami, yang mungkin ingin Anda hapus. Setelah pelatihan, Anda dapat mengonversi model Anda menjadi transformator dengan misalnya python Megatron-DeepSpeed/tools/convert_checkpoint/deepspeed_to_transformers.py --input_folder global_step52452 --output_folder transformers --target_tp 1 --target_pp 1 .
Untuk model berulang, kami juga mengunggah tensorboardnya setelah pelatihan menggunakan misalnya tensorboard dev upload --logdir tensorboard_8b7178b88boscar --name "tensorboard_8b7178b88boscar" , yang membuatnya mudah digunakan untuk visualisasi di kertas.
Untuk ablasi muP di Lampiran kami menggunakan skrip di training_scripts/mup.py . Ini berisi instruksi pengaturan.
Anda dapat menggunakan rumus kami untuk menghitung perkiraan kerugian berdasarkan parameter, data, dan token unik sebagai berikut:
import numpy as np
func = r"$L(N,D,R_N,R_D)=E + frac{A}{(U_N + U_N * R_N^* * (1 - e^{(-1*R_N/(R_N^*))}))^alpha} + frac{B}{(U_D + U_D * R_D^* * (1 - e^{(-1*R_D/(R_D^*))}))^beta}$"
a , b , e , alpha , beta , rd_star , rn_star = [ 6.255414 , 7.3049974 , 0.6254804 , 0.3526596 , 0.3526596 , 15.387756 , 5.309743 ]
A = np . exp ( a )
B = np . exp ( b )
E = np . exp ( e )
G = (( alpha * A ) / ( beta * B )) ** ( 1 / ( alpha + beta ))
def D_to_N ( D ):
return ( D * G ) ** ( beta / alpha ) * G
def scaling_law ( N , D , U ):
"""
N: number of parameters
D: number of total training tokens
U: number of unique training tokens
"""
assert U <= D , "Cannot have more unique tokens than total tokens"
RD = np . maximum (( D / U ) - 1 , 0 )
UN = np . minimum ( N , D_to_N ( U ))
RN = np . maximum (( N / UN ) - 1 , 0 )
L = E + A / ( UN + UN * rn_star * ( 1 - np . exp ( - 1 * RN / rn_star ))) ** alpha + B / ( U + U * rd_star * ( 1 - np . exp ( - 1 * RD / ( rd_star )))) ** beta
return L
# Models in Figure 1 (right):
print ( scaling_law ( 6.34e9 , 242e9 , 25e9 )) # 2.2256440889984477 # <- This one is better
print ( scaling_law ( 8.67e9 , 178e9 , 25e9 )) # 2.2269634075087867Perhatikan bahwa nilai kerugian sebenarnya kemungkinan tidak berguna, melainkan tren kerugian misalnya jumlah parameter bertambah atau membandingkan dua model seperti pada contoh di atas. Untuk menghitung alokasi optimal, Anda dapat menggunakan pencarian grid sederhana:
def chinchilla_optimal_N ( C ):
a = ( beta ) / ( alpha + beta )
N_opt = G * ( C / 6 ) ** a
return N_opt
def chinchilla_optimal_D ( C ):
b = ( alpha ) / ( alpha + beta )
D_opt = ( 1 / G ) * ( C / 6 ) ** b
return D_opt
def optimal_allocation ( C , U_BASE ):
"""Compute optimal number of parameters and tokens to train for given a compute & unique data budget"""
N_BASE = chinchilla_optimal_N ( C )
D_BASE = chinchilla_optimal_D ( C )
min_l = float ( "inf" )
for i in np . linspace ( 1.0001 , 3 , 500 ):
D = D_BASE * i
U = min ( U_BASE , D )
N = N_BASE / i
new_l = scaling_law ( N , D , U )
if new_l < min_l :
min_l , min_t , min_s = new_l , D , N
D = D_BASE / i
U = min ( U_BASE , D )
N = N_BASE * i
new_l = scaling_law ( N , D , U )
if new_l < min_l :
min_l , min_t , min_s = new_l , D , N
return min_l , min_t , min_s
_ , min_t , min_s = optimal_allocation ( 10 ** 22 , 25e9 )
print ( f"Optimal configuration: { min_t } tokens, { min_t / 25e9 } epochs, { min_s } parameters" )
# -> 237336955477.55075 tokens, 9.49347821910203 epochs, 7022364735.879969 parameters
# We went more extreme in Figure 1 to really put our prediction of "many epochs, fewer params" to the test Jika Anda mendapatkan ekspresi bentuk tertutup untuk alokasi optimal dan bukan penelusuran kisi di atas, harap beri tahu kami :) Kami menyesuaikan hukum penskalaan dengan batasan data & koefisien penskalaan C4 menggunakan kode di utils/parametric_fit.ipynb yang setara dengan colab ini .
Training > Regular models untuk menyiapkan lingkungan pelatihan.pip install git+https://github.com/EleutherAI/lm-evaluation-harness.git . Kami menggunakan versi 0.2.0, tetapi versi yang lebih baru juga bisa digunakan.sbatch utils/eval_rank.sh dengan memodifikasi variabel yang diperlukan dalam skrip terlebih dahulupython Megatron-DeepSpeed/tasks/eval_harness/report-to-csv.py outfile.jsonaddtasks dari harness evaluasi: git clone -b addtasks https://github.com/Muennighoff/lm-evaluation-harness.gitcd lm-evaluation-harness; pip install -e ".[dev]"; pip uninstall -y promptsource; pip install git+https://github.com/Muennighoff/promptsource.git@tr13 yaitu semua persyaratan kecuali promptsource, yang diinstal dari fork dengan prompt yang benarsbatch utils/eval_generative.sh dengan memodifikasi variabel yang diperlukan dalam skrip terlebih dahulupython utils/merge_generative.py lalu mengonversinya menjadi csv dengan python utils/csv_generative.py merged.jsonbabi dari harness evaluasi: git clone -b babi https://github.com/Muennighoff/lm-evaluation-harness.git (Perhatikan bahwa cabang ini tidak kompatibel dengan cabang addtasks untuk tugas generatif karena berasal dari EleutherAI/lm-evaluation-harness , sedangkan addtasks didasarkan pada bigscience/lm-evaluation-harness )cd lm-evaluation-harness; pip install -e ".[dev]"sbatch utils/eval_babi.sh dengan memodifikasi variabel yang diperlukan dalam skrip terlebih dahulu plotstables/return_alloc.pdf , plotstables/return_alloc.ipynb , colabplotstables/dataset_setup.pdf , plotstables/dataset_setup.ipynb , colabplotstables/contours.pdf , plotstables/contours.ipynb , colabplotstables/isoflops_training.pdf , plotstables/isoflops_training.ipynb , colabplotstables/return.pdf , plotstables/return.ipynb , colabplotstables/strategies.pdf , plotstables/strategies.drawioplotstables/beyond.pdf , plotstables/beyond.ipynb , colabplotstables/cartoon.pdf , plotstables/cartoon.pptxplotstables/isoloss_400m1b5.pdf & colab yang sama seperti Gambar 3plotstables/mup.pdf , plotstables/dd.pdf , plotstables/dedup.pdf , plotstables/mup_dd_dd.ipynb , colabplotstables/isoloss_alphabeta_100m.pdf & colab yang sama seperti Gambar 3plotstables/galactica.pdf , plotstables/galactica.ipynb , colabtraining_c4.pdf , validation_c4oscar.pdf , training_oscar.pdf , validation_epochs_c4oscar.pdf & colab yang sama seperti Gambar 4plotstables/perplexity_histogram.pdf , plotstables/perplexity_histogram.ipynbplotstabls/validation_c4py.pdf , plotstables/training_validation_filter.pdf , plotstables/beyond_losses.ipynb & colabutils/parametric_fit.ipynb yang setara dengan colab ini.plotstables/repetition.ipynb & colabplotstables/python.ipynb & colabplotstables/filtering.ipynb & colabSemua model & kode dilisensikan di bawah Apache 2.0. Kumpulan data yang difilter dirilis dengan lisensi yang sama dengan kumpulan data asalnya.
@article { muennighoff2023scaling ,
title = { Scaling Data-Constrained Language Models } ,
author = { Muennighoff, Niklas and Rush, Alexander M and Barak, Boaz and Scao, Teven Le and Piktus, Aleksandra and Tazi, Nouamane and Pyysalo, Sampo and Wolf, Thomas and Raffel, Colin } ,
journal = { arXiv preprint arXiv:2305.16264 } ,
year = { 2023 }
}

