lance
v0.20.0

Format data kolom modern untuk ML. Konversi dari Parket dalam 2 baris kode untuk akses acak 100x lebih cepat, indeks vektor, pembuatan versi data, dan banyak lagi.
Kompatibel dengan pandas, DuckDB, Polars, dan pyarrow dengan lebih banyak integrasi yang akan segera dilakukan.
Dokumentasi • Blog • Perselisihan • Twitter
Lance adalah format data kolom modern yang dioptimalkan untuk alur kerja dan kumpulan data ML. Lance sangat cocok untuk:
Fitur utama Lance meliputi:
Akses acak berkinerja tinggi: 100x lebih cepat dari Parket tanpa mengorbankan kinerja pemindaian.
Pencarian vektor: temukan tetangga terdekat dalam milidetik dan gabungkan kueri OLAP dengan pencarian vektor.
Pembuatan versi otomatis tanpa salinan: kelola versi data Anda tanpa memerlukan infrastruktur tambahan.
Integrasi ekosistem: Apache Arrow, Pandas, Polars, DuckDB, dan lainnya sedang dalam proses.
Tip
Lance sedang dalam pengembangan aktif dan kami menyambut baik kontribusinya. Silakan lihat panduan kontribusi kami untuk informasi lebih lanjut.
Instalasi
pip install pylanceUntuk menginstal rilis pratinjau:
pip install --pre --extra-index-url https://pypi.fury.io/lancedb/ pylanceTip
Rilis pratinjau lebih sering dirilis daripada rilis lengkap dan berisi fitur-fitur terbaru serta perbaikan bug. Mereka menerima tingkat pengujian yang sama dengan rilis penuh. Kami menjamin mereka akan tetap dipublikasikan dan tersedia untuk diunduh setidaknya selama 6 bulan. Jika Anda ingin menyematkan ke versi tertentu, pilih rilis stabil.
Mengonversi ke Lance
import lance
import pandas as pd
import pyarrow as pa
import pyarrow . dataset
df = pd . DataFrame ({ "a" : [ 5 ], "b" : [ 10 ]})
uri = "/tmp/test.parquet"
tbl = pa . Table . from_pandas ( df )
pa . dataset . write_dataset ( tbl , uri , format = 'parquet' )
parquet = pa . dataset . dataset ( uri , format = 'parquet' )
lance . write_dataset ( parquet , "/tmp/test.lance" )Membaca data Lance
dataset = lance . dataset ( "/tmp/test.lance" )
assert isinstance ( dataset , pa . dataset . Dataset )Panda
df = dataset . to_table (). to_pandas ()
dfBebekDB
import duckdb
# If this segfaults, make sure you have duckdb v0.7+ installed
duckdb . query ( "SELECT * FROM dataset LIMIT 10" ). to_df ()Pencarian vektor
Unduh subset sift1m
wget ftp://ftp.irisa.fr/local/texmex/corpus/sift.tar.gz
tar -xzf sift.tar.gzUbah menjadi Lance
import lance
from lance . vector import vec_to_table
import numpy as np
import struct
nvecs = 1000000
ndims = 128
with open ( "sift/sift_base.fvecs" , mode = "rb" ) as fobj :
buf = fobj . read ()
data = np . array ( struct . unpack ( "<128000000f" , buf [ 4 : 4 + 4 * nvecs * ndims ])). reshape (( nvecs , ndims ))
dd = dict ( zip ( range ( nvecs ), data ))
table = vec_to_table ( dd )
uri = "vec_data.lance"
sift1m = lance . write_dataset ( table , uri , max_rows_per_group = 8192 , max_rows_per_file = 1024 * 1024 )Bangun indeks
sift1m . create_index ( "vector" ,
index_type = "IVF_PQ" ,
num_partitions = 256 , # IVF
num_sub_vectors = 16 ) # PQCari kumpulan data
# Get top 10 similar vectors
import duckdb
dataset = lance . dataset ( uri )
# Sample 100 query vectors. If this segfaults, make sure you have duckdb v0.7+ installed
sample = duckdb . query ( "SELECT vector FROM dataset USING SAMPLE 100" ). to_df ()
query_vectors = np . array ([ np . array ( x ) for x in sample . vector ])
# Get nearest neighbors for all of them
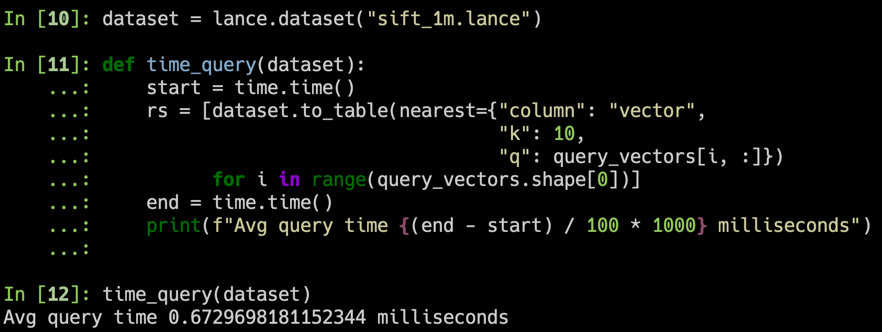
rs = [ dataset . to_table ( nearest = { "column" : "vector" , "k" : 10 , "q" : q })
for q in query_vectors ]| Direktori | Keterangan |
|---|---|
| karat | Implementasi Inti Karat |
| ular piton | Ikatan python (pyo3) |
| dokumen | Sumber dokumentasi |
Di sini kami akan menyoroti beberapa aspek desain Lance. Untuk lebih jelasnya, lihat dokumen desain Lance selengkapnya.
Indeks vektor : Indeks vektor untuk pencarian kesamaan pada ruang penyematan. Mendukung CPU ( x86_64 dan arm ) dan GPU ( Nvidia (cuda) dan Apple Silicon (mps) ).
Pengkodean : Untuk mencapai pemindaian kolom cepat dan kueri titik sub-linier, Lance menggunakan pengkodean dan tata letak khusus.
Bidang bersarang : Lance menyimpan setiap subbidang sebagai kolom terpisah untuk mendukung filter efisien seperti "temukan gambar di mana objek yang terdeteksi termasuk kucing".
Pembuatan Versi : Manifes dapat digunakan untuk merekam snapshot. Saat ini kami mendukung pembuatan versi baru secara otomatis melalui penambahan, penimpaan, dan pembuatan indeks.
Pembaruan cepat (ROADMAP): Pembaruan akan didukung melalui log write-ahead.
Indeks sekunder kaya (ROADMAP):
Kami menggunakan kumpulan data SIFT untuk membandingkan hasil kami dengan 1 juta vektor 128D
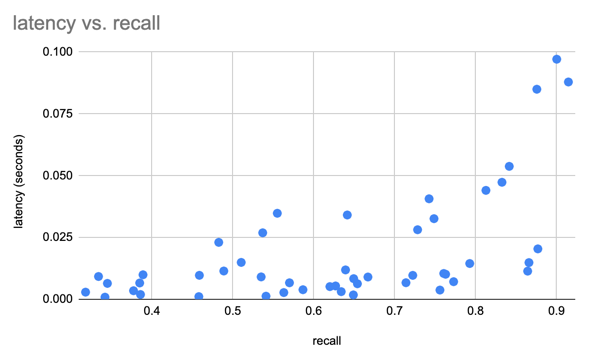
Kami membuat kumpulan data Lance menggunakan kumpulan data Oxford Pet untuk melakukan beberapa pengujian kinerja awal Lance dibandingkan dengan Parket dan gambar mentah/XML. Untuk kueri analitik, Lance 50-100x lebih baik daripada membaca metadata mentah. Untuk akses acak batch, Lance 100x lebih baik daripada file parket dan mentah.

Siklus pengembangan pembelajaran mesin melibatkan langkah-langkah:
grafik LR
A[Koleksi] --> B[Eksplorasi];
B --> C[Analitik];
C --> D[Insinyur Fitur];
D --> E[Pelatihan];
E --> F[Evaluasi];
F --> C;
E --> G[Penerapan];
G --> H[Pemantauan];
H --> SEBUAH;
Orang-orang menggunakan representasi data yang berbeda pada tahapan kinerja yang berbeda-beda atau dibatasi oleh alat yang tersedia. Akademia terutama menggunakan XML / JSON untuk anotasi dan data gambar/sensor yang di-zip untuk pembelajaran mendalam, yang sulit diintegrasikan ke dalam infrastruktur data dan lambat untuk dilatih melalui penyimpanan cloud. Meskipun industri menggunakan data lake (teknik berbasis Parket, misalnya Delta Lake, Iceberg) atau gudang data (AWS Redshift atau Google BigQuery) untuk mengumpulkan dan menganalisis data, mereka harus mengonversi data tersebut ke dalam format yang ramah pelatihan, seperti Rikai/ Petastorm atau TFRecord. Beberapa transformasi data dengan tujuan tunggal, serta sinkronisasi salinan antara penyimpanan cloud ke instance pelatihan lokal telah menjadi praktik umum.
Meskipun masing-masing format data yang ada unggul dalam beban kerja yang awalnya dirancang, kami memerlukan format data baru yang disesuaikan untuk siklus pengembangan ML multitahap guna mengurangi dan silo data.
Perbandingan format data yang berbeda di setiap tahap siklus pengembangan ML.
| Tombak | Parket & ORC | JSON & XML | Catatan TF | Basis data | Gudang | |
|---|---|---|---|---|---|---|
| Analisis | Cepat | Cepat | Lambat | Lambat | Baik | Cepat |
| Rekayasa Fitur | Cepat | Cepat | Baik | Lambat | Baik | Bagus |
| Pelatihan | Cepat | Baik | Lambat | Cepat | T/A | T/A |
| Eksplorasi | Cepat | Lambat | Cepat | Lambat | Cepat | Baik |
| Dukungan Infra | Kaya | Kaya | Baik | Terbatas | Kaya | Kaya |
Lance saat ini digunakan dalam produksi oleh:


