metal flash attention
v1.0.1
Repositori ini mem-porting implementasi resmi FlashAttention ke silikon Apple. Ini adalah kumpulan file sumber minimal dan dapat dipelihara yang mereproduksi algoritma FlashAttention.
Hanya perhatian berkepala tunggal, untuk fokus pada hambatan inti dari algoritma perhatian yang berbeda (mencatat tekanan, paralelisme). Dengan algoritme dasar yang dilakukan dengan benar, menambahkan penyesuaian seperti ketersebaran blok akan relatif mudah.
Semuanya dikompilasi JIT saat runtime. Hal ini berbeda dengan implementasi sebelumnya, yang mengandalkan executable yang tertanam di Xcode 14.2.
Pass mundur menggunakan lebih sedikit memori dibandingkan Dao-AILab/flash-attention. Implementasi resmi mengalokasikan ruang awal untuk atom dan jumlah parsial. Perangkat keras Apple tidak memiliki atom FP32 asli ( metal::atomic<float> ditiru). Saat mencoba untuk menghindari kurangnya dukungan perangkat keras, hambatan bandwidth dan paralelisasi di kernel mundur FlashAttention-2 terungkap. Jalur mundur alternatif dirancang dengan biaya komputasi yang lebih tinggi (7 GEMM, bukan 5 GEMM). Ini mencapai efisiensi paralelisasi 100% di dimensi baris dan kolom matriks perhatian. Yang terpenting, lebih mudah untuk membuat kode dan memeliharanya.
Banyak hal gila yang dilakukan untuk mengatasi hambatan tekanan register. Pada dimensi head yang besar (misalnya 256), tidak ada satupun blok matriks yang dapat masuk ke dalam register. Bahkan akumulator pun tidak bisa. Oleh karena itu, penumpahan register yang disengaja dilakukan, namun dengan cara yang lebih optimal. Dimensi blok ketiga ditambahkan ke algoritma perhatian, yang memblokir sepanjang D . Rasio aspek blok matriks perhatian diubah secara drastis, untuk meminimalkan biaya bandwidth akibat tumpahnya register. Misalnya 16-32 sepanjang dimensi paralelisasi dan 80-128 sepanjang dimensi traversal. Ada file parameter besar yang mengambil dimensi D , dan menentukan operan mana yang dapat dimasukkan ke dalam register. Ini kemudian menetapkan ukuran blok yang menyeimbangkan banyak hambatan yang bersaing.
Hasil akhirnya adalah 4400 gigainstruksi per detik yang konsisten pada M1 Max (83% pemanfaatan ALU), dengan panjang urutan tak terbatas dan dimensi head tak terbatas. Emulasi BF16 yang disediakan digunakan untuk presisi campuran ( bfloat Metal memiliki pembulatan yang sesuai dengan IEEE, overhead yang besar pada chip lama tanpa perangkat keras BF16).
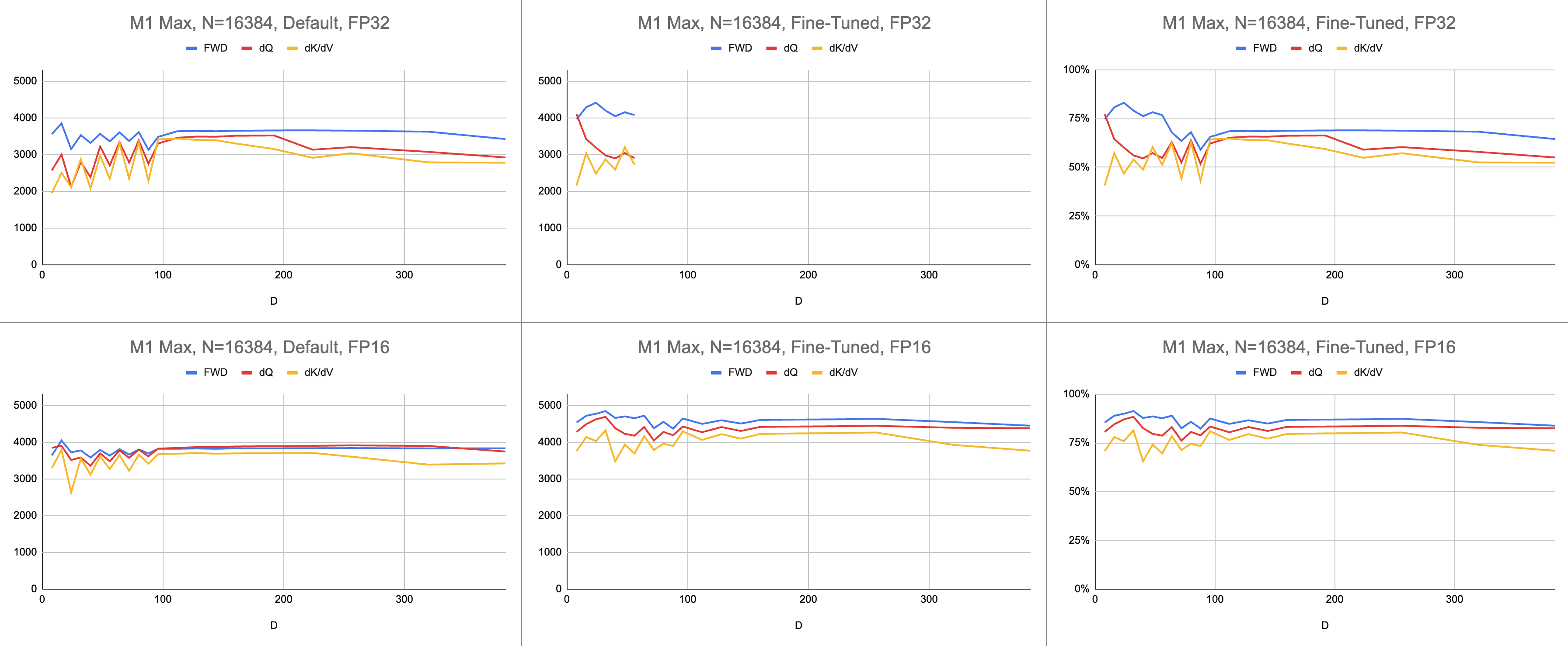
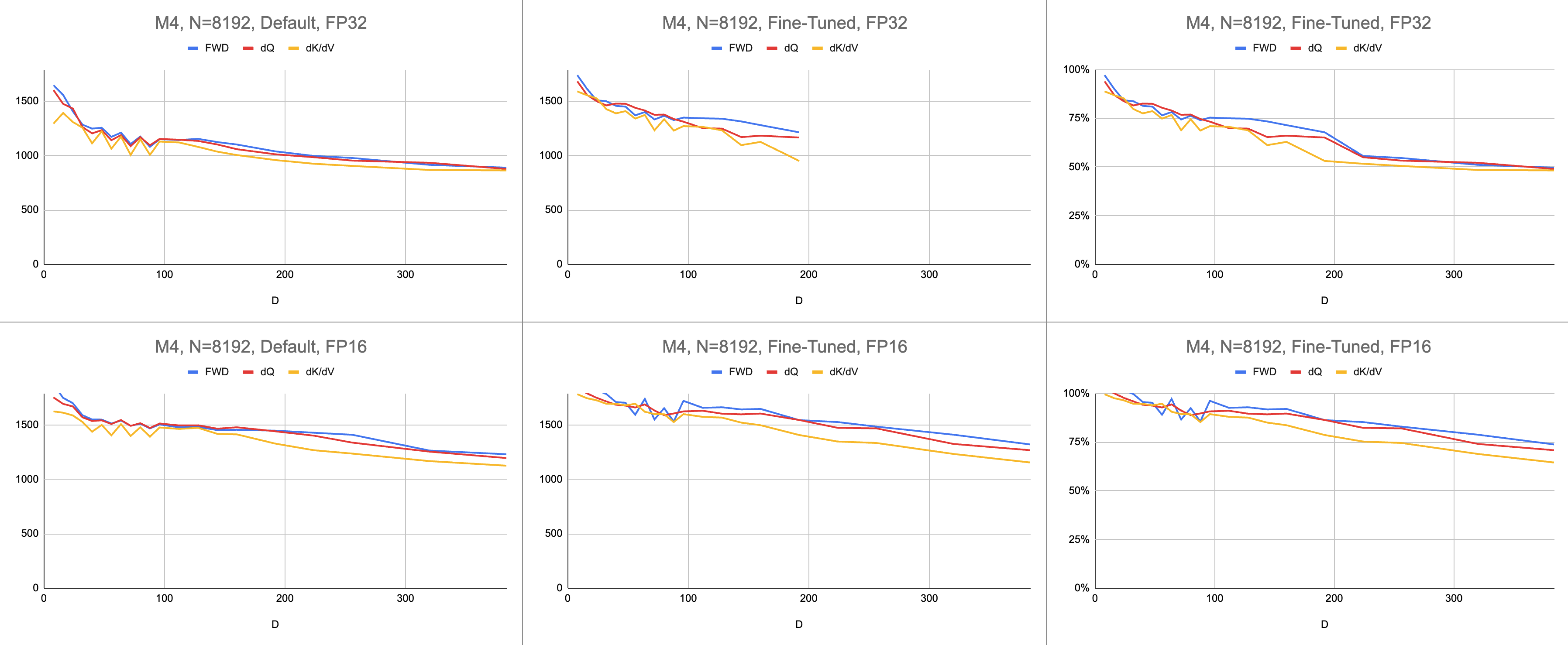
Data Mentah: https://docs.google.com/spreadsheets/d/1Xf4jrJ7e19I32J1IWIekGE9uMFTeZKoOpQ6hlUoh-xY/edit?usp=sharing
Di bidang AI, performa paling sering dilaporkan dalam operasi giga-floating point per detik (GFLOPS). Metrik ini mencerminkan model kinerja yang disederhanakan, bahwa setiap instruksi terjadi di GEMM. Seiring dengan kemajuan perangkat keras dari FPU awal hingga prosesor vektor modern, operasi floating-point yang paling umum digabungkan menjadi satu instruksi. Perkalian leburan-tambah (FMA). Ketika seseorang mengalikan dua matriks 100x100, 1 juta instruksi FMA dikeluarkan. Mengapa kita harus memperlakukan FMA ini sebagai dua instruksi terpisah?
Pertanyaan ini relevan untuk diperhatikan, karena tidak semua operasi floating point diciptakan sama. Eksponensial selama softmax terjadi dalam satu siklus clock, asalkan sebagian besar instruksi lainnya masuk ke unit FMA. Beberapa perkalian dan perkalian pada saat softmax, tidak dapat digabungkan dengan perkalian atau perkalian di dekatnya. Haruskah kita memperlakukan ini sama seperti FMA, dan menganggap perangkat keras hanya mengeksekusi FMA dua kali lebih lambat? Tidak jelas bagaimana model kinerja GEMM dapat menjelaskan apakah shader saya menggunakan perangkat keras ALU secara efektif.
Alih-alih gigaflop, saya menggunakan instruksi giga untuk memahami seberapa baik kinerja shader. Ini memetakan lebih langsung ke algoritma. Misalnya, satu instruksi GEMM adalah N^3 FMA. Perhatian ke depan melakukan dua perkalian matriks, atau instruksi FMA 2 * D * N^2 . Perhatian ke belakang (dengan implementasi Dao-AILab/flash-attention) adalah instruksi FMA 5 * D * N^2 . Coba bandingkan tabel ini dengan model garis atap di makalah Flash1, Flash2, atau Flash3.
| Operasi | Bekerja |
|---|---|
| PERMATA persegi | N^3 |
| Perhatian ke Depan | (2D + 5) * N^2 |
| Perhatian Naif ke Belakang | 4D * N^2 |
| Flash MundurPerhatian | (5D + 5) * N^2 |
| Gabungan FWD + BWD | (7D + 10) * N^2 |
Karena kompleksitas atom FP32, MFA menggunakan pendekatan berbeda untuk backward pass. Yang ini memiliki biaya komputasi yang lebih tinggi. Ini membagi backward pass menjadi dua kernel terpisah: dQ dan dK/dV . Dropdown menunjukkan kodesemu. Bandingkan ini dengan salah satu algoritma di makalah Flash1, Flash2, atau Flash3.
| Operasi | Bekerja |
|---|---|
| Maju | (2D + 5) * N^2 |
| Mundur dQ | (3D + 5) * N^2 |
| Mundur dK/dV | (4D + 5) * N^2 |
| Gabungan FWD + BWD | (9D + 15) * N^2 |
// Forward
// for c in 0..<C {
// load K[c]
// S = Q * K^T
// (m, l, P) = softmax(m, l, S * scaleFactor)
//
// O *= correction
// load V[c]
// O += P * V
// }
// O /= l
//
// L = m + logBaseE(l)
//
// Backward Query
// D = dO * O
//
// for c in 0..<C {
// load K[c]
// S = Q * K^T
// P = exp(S - L)
//
// load V[c]
// dP = dO * V^T
// dS = P * (dP - D) * scaleFactor
//
// load K[c]
// dQ += dS * K
// }
//
// Backward Key-Value
// for r in 0..<R {
// load Q[r]
// load L[r]
// S^T = K * Q^T
// P^T = exp(S^T - L)
//
// load dO[r]
// dV += P^T * dO
//
// load dO[r]
// load D[r]
// dP^T = V * dO^T
// dS^T = P^T * (dP^T - D) * scaleFactor
//
// load Q[r]
// dK += dS^T * Q
// }Performa diukur dengan menghitung jumlah kerja komputasi, lalu membaginya dengan detik. Hasil akhirnya adalah "instruksi giga per detik". Selanjutnya kita membutuhkan model garis atap. Tabel di bawah menunjukkan garis atap untuk GINSTRS, dihitung sebagai setengah dari GFLOPS. Pemanfaatan ALU adalah (instruksi giga aktual per detik) / (instruksi giga yang diharapkan per detik). Misalnya, M1 Max biasanya mencapai pemanfaatan ALU 80% dengan presisi campuran.
Ada batasan pada model ini. Ini rusak dengan generasi M3 pada dimensi kepala yang kecil. Unit komputasi yang berbeda mungkin digunakan secara bersamaan, sehingga pemanfaatannya lebih dari 100%. Umumnya, benchmark memberikan model yang akurat mengenai seberapa besar kinerja yang tersisa.
var operations : Int
switch benchmarkedKernel {
case . forward :
operations = 2 * headDimension + 5
case . backwardQuery :
operations = 3 * headDimension + 5
case . backwardKeyValue :
operations = 4 * headDimension + 5
}
operations *= ( sequenceDimension * sequenceDimension )
operations *= dispatchCount
// Divide the work by the latency, resulting in throughput.
let instrs = Double ( operations ) / Double ( latencySeconds )
let ginstrs = Int ( instrs / 1e9 )| Perangkat keras | GLOPS | GINSTR |
|---|---|---|
| M1 Maks | 10616 | 5308 |
| M4 | 3580 | 1790 |
Seberapa baik port Metal dibandingkan dengan repositori resmi FlashAttention? Bayangkan saya menggunakan algoritma "atomic dQ" dan mencapai kinerja 100%. Kemudian, beralih ke repo MFA yang sebenarnya dan menemukan pelatihan model menjadi 4x lebih lambat. Itu akan menjadi 25% dari garis atap dari repositori resmi. Untuk mendapatkan persentase ini, kalikan rata-rata pemanfaatan ALU di ketiga kernel dengan 7 / 9 . Model yang lebih bernuansa digunakan untuk statistik perangkat keras Apple, tetapi inilah intinya.
Untuk menghitung pemanfaatan perangkat keras Nvidia, saya menggunakan GFLOPS untuk ALU FP16/BF16. Saya membagi GFLOPS tertinggi dari setiap grafik di makalah dengan 312000 (A100 SXM), 989000 (H100 SXM). Perhatikan bahwa, untuk dimensi head yang lebih besar dan register kernel intensif (backward pass), tidak ada tolok ukur yang dilaporkan. Saya mengonfirmasi bahwa mereka tidak menyelesaikan masalah tekanan register pada dimensi head tak terbatas. Misalnya, akumulator selalu disimpan di register. Pada saat penulisan, saya belum melihat bukti nyata bahwa gradien mundur D=256 dijalankan dengan hasil yang benar.
| A100, Flash2, FP16 | D = 64 | D = 128 | D = 256 |
|---|---|---|---|
| Maju | 192000 | 223000 | 0 |
| Ke belakang | 170000 | 196000 | 0 |
| Maju + Mundur | 176000 | 203000 | 0 |
| H100, Flash3, FP16 | D = 64 | D = 128 | D = 256 |
|---|---|---|---|
| Maju | 497000 | 648000 | 756000 |
| Ke belakang | 474000 | 561000 | 0 |
| Maju + Mundur | 480000 | 585000 | 0 |
| H100, Flash3, FP8 | D = 64 | D = 128 | D = 256 |
|---|---|---|---|
| Maju | 613000 | 1008000 | 1171000 |
| Ke belakang | 0 | 0 | 0 |
| Maju + Mundur | 0 | 0 | 0 |
| A100, Flash2, FP16 | D = 64 | D = 128 | D = 256 |
|---|---|---|---|
| Maju | 62% | 71% | 0% |
| Maju + Mundur | 56% | 65% | 0% |
| H100, Flash3, FP16 | D = 64 | D = 128 | D = 256 |
|---|---|---|---|
| Maju | 50% | 66% | 76% |
| Maju + Mundur | 48% | 59% | 0% |
| Arsitektur M1, FP16 | D = 64 | D = 128 | D = 256 |
|---|---|---|---|
| Maju | 86% | 85% | 86% |
| Maju + Mundur | 62% | 63% | 64% |
| Arsitektur M3, FP16 | D = 64 | D = 128 | D = 256 |
|---|---|---|---|
| Maju | 94% | 91% | 82% |
| Maju + Mundur | 71% | 69% | 61% |
| Perangkat Keras Diproduksi pada tahun 2020 | D = 64 | D = 128 | D = 256 |
|---|---|---|---|
| A100 | 56% | 65% | 0% |
| Arsitektur M1—M2 | 62% | 63% | 64% |
| Perangkat Keras Diproduksi pada tahun 2023 | D = 64 | D = 128 | D = 256 |
|---|---|---|---|
| H100 (menggunakan FP8 GFLOPS) | 24% | 30% | 0% |
| H100 (menggunakan FP16 GFLOPS) | 48% | 59% | 0% |
| M3—Arsitektur M4 | 71% | 69% | 61% |
Meskipun mengeluarkan lebih banyak komputasi, perangkat keras Apple melatih transformator lebih cepat daripada perangkat keras Nvidia yang melakukan pekerjaan yang sama . Menormalkan perbedaan ukuran antara GPU yang berbeda. Hanya berfokus pada seberapa efisien penggunaan GPU.
Mungkin repositori utama harus mencoba algoritme yang menghindari atom FP32 dan dengan sengaja menumpahkan register ketika tidak dapat masuk ke dalam inti GPU. Hal ini tampaknya tidak mungkin terjadi, karena mereka memiliki dukungan hardcode untuk sebagian kecil dari kemungkinan ukuran masalah. Motivasi tersebut tampaknya mendukung model yang paling umum, di mana D adalah pangkat 2, dan kurang dari 128. Untuk hal lain, pengguna harus mengandalkan implementasi fallback alternatif (misalnya repositori MFA), yang mungkin menggunakan dasar yang sama sekali berbeda. algoritma.
Di macOS, unduh paket Swift dan kompilasi dengan -Xswiftc -Ounchecked . Opsi kompiler ini diperlukan untuk kode CPU yang sensitif terhadap kinerja. Mode rilis tidak dapat digunakan karena memaksa seluruh basis kode dikompilasi ulang dari awal, setiap kali ada satu perubahan pun. Navigasikan ke repo Git di Finder dan klik dua kali Package.swift . Jendela Xcode akan muncul. Di sebelah kiri, harus ada hierarki file. Jika Anda tidak dapat mengungkap hierarkinya, ada yang tidak beres.
git clone https://github.com/philipturner/metal-flash-attention
swift build -Xswiftc -Ounchecked # Does it even compile?
swift test -Xswiftc -Ounchecked # Does the test suite finish in ~10 seconds?
Alternatifnya, buat proyek Xcode baru dengan templat SwiftUI. Ganti kalimat "Hello, world!" string dengan panggilan ke fungsi yang mengembalikan String . Fungsi ini akan menjalankan skrip pilihan Anda, lalu memanggil exit(0) , sehingga aplikasi mogok sebelum menampilkan apa pun ke layar. Anda akan menggunakan output di konsol Xcode sebagai umpan balik tentang kode Anda. Alur kerja ini kompatibel dengan macOS dan iOS.
Tambahkan opsi -Xswiftc -Ounchecked melalui Project > your project's name > Build Settings > Swift Compiler - Code Generation > Optimization Level . Kolom kedua tabel mencantumkan nama proyek Anda. Klik Lainnya di dropdown dan ketik -Ounchecked di panel yang muncul. Selanjutnya, tambahkan repositori ini sebagai ketergantungan paket Swift. Lihat beberapa tes di bawah Tests/FlashAttention . Salin kode sumber mentah untuk salah satu pengujian ini ke dalam proyek Anda. Panggil tes dari fungsi di paragraf sebelumnya. Periksa apa yang ditampilkan di konsol.
Untuk memodifikasi pembuatan kode Logam (misalnya menambahkan dukungan multi-head atau mask), salin kode Swift mentah ke proyek Xcode Anda. Gunakan git clone di folder terpisah, atau unduh file mentah di GitHub sebagai ZIP. Ada juga cara untuk menautkan ke fork metal-flash-attention dan menyimpan perubahan Anda secara otomatis ke cloud, tetapi ini lebih sulit untuk disiapkan. Hapus ketergantungan paket Swift dari paragraf sebelumnya. Jalankan kembali pengujian yang Anda pilih. Apakah itu mengkompilasi dan menampilkan sesuatu di konsol?
Temukan salah satu literal string multi-baris di salah satu folder berikut:
Sources/FlashAttention/Attention/AttentionKernel
Sources/FlashAttention/GEMM/GEMMKernel
Tambahkan teks acak ke salah satunya. Kompilasi dan jalankan proyek lagi. Pasti ada yang tidak beres. Misalnya, kompiler Metal mungkin menimbulkan kesalahan. Jika ini tidak terjadi, coba ubah baris kode lain di tempat lain. Jika pengujian masih lolos, Xcode tidak mendaftarkan perubahan Anda.
Lanjutkan dengan mengkode ketersebaran blok atau semacamnya. Dapatkan umpan balik tentang apakah kode berfungsi, apakah berfungsi cepat, apakah berfungsi cepat pada setiap ukuran masalah. Integrasikan kode sumber mentah ke dalam aplikasi Anda, atau terjemahkan ke bahasa pemrograman lain.


