RoboFlamingo
1.0.0
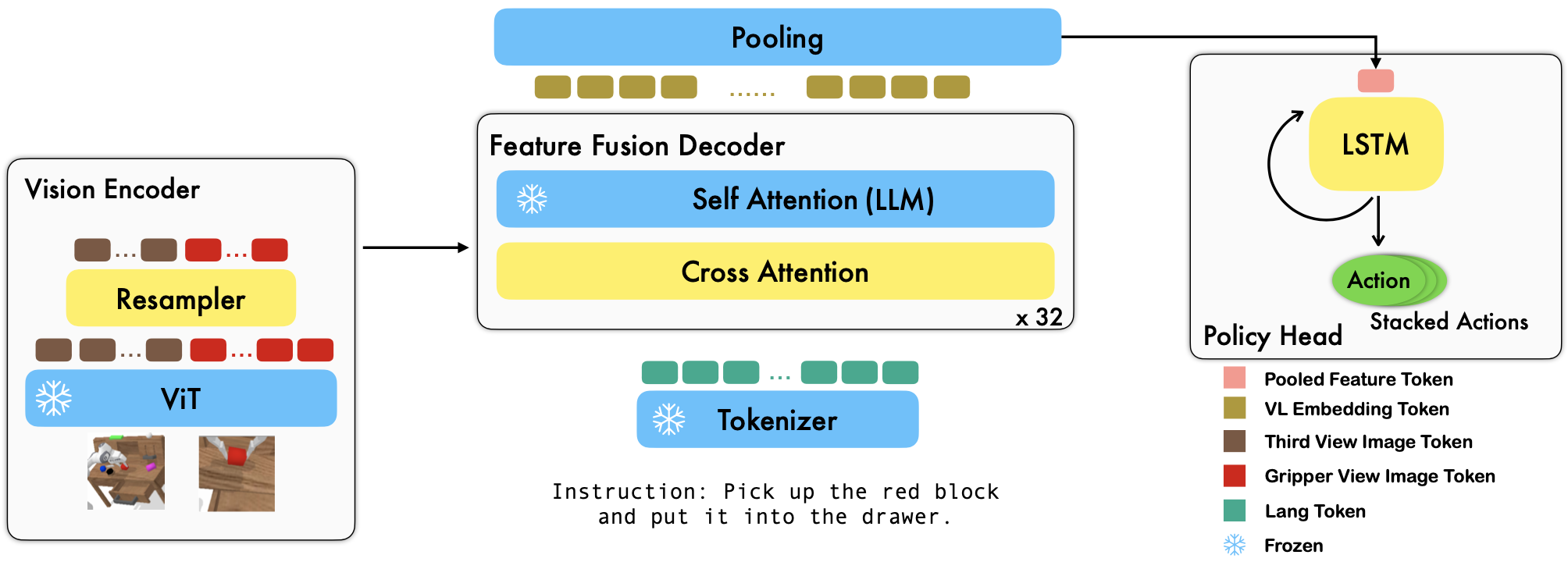
RoboFlamingo adalah kerangka pembelajaran robotika berbasis VLM yang telah dilatih sebelumnya yang mempelajari beragam keterampilan robot yang dikondisikan bahasa dengan menyempurnakan kumpulan data imitasi bentuk bebas offline. Dengan melampaui performa canggih dengan margin besar pada benchmark CALVIN, kami menunjukkan bahwa RoboFlamingo dapat menjadi alternatif yang efektif dan kompetitif untuk mengadaptasi VLM ke kontrol robot. Hasil eksperimen ekstensif kami juga mengungkapkan beberapa kesimpulan menarik mengenai perilaku berbagai VLM terlatih dalam tugas manipulasi. RoboFlamingo dapat dilatih atau dievaluasi pada satu server GPU (persyaratan mem GPU bergantung pada ukuran model), dan kami yakin RoboFlamingo berpotensi menjadi solusi yang hemat biaya dan mudah digunakan untuk manipulasi robotika, memberdayakan semua orang dengan kemampuan untuk menyempurnakan kebijakan robotika mereka sendiri.
Ini juga merupakan repo kode resmi untuk makalah Model Landasan Bahasa Visi sebagai Peniru Robot yang Efektif.
Semua eksperimen kami dilakukan pada satu server GPU dengan 8 GPU Nvidia A100 (80G).
Model terlatih tersedia di Hugging Face.
Kami mendukung pembuat enkode visi terlatih dari paket OpenCLIP, yang mencakup model terlatih OpenAI. Kami juga mendukung model bahasa terlatih dari paket transformers , seperti model MPT, RedPajama, LLaMA, OPT, GPT-Neo, GPT-J, dan Pythia.
from robot_flamingo . factor import create_model_and_transforms
model , image_processor , tokenizer = create_model_and_transforms (
clip_vision_encoder_path = "ViT-L-14" ,
clip_vision_encoder_pretrained = "openai" ,
lang_encoder_path = "PATH/TO/LLM/DIR" ,
tokenizer_path = "PATH/TO/LLM/DIR" ,
cross_attn_every_n_layers = 1 ,
decoder_type = 'lstm' ,
) Argumen cross_attn_every_n_layers mengontrol seberapa sering lapisan perhatian silang diterapkan dan harus konsisten dengan VLM. Argumen decoder_type mengontrol jenis decoder, saat ini, kami mendukung lstm , fc , diffusion (ada bug untuk dataloader), dan GPT .
Kami melaporkan hasil pada benchmark CALVIN.
| Metode | Data Pelatihan | Perpecahan Tes | 1 | 2 | 3 | 4 | 5 | Rata-rata Len |
|---|---|---|---|---|---|---|---|---|
| MCIL | ABCD (Penuh) | D | 0,373 | 0,027 | 0,002 | 0,000 | 0,000 | 0,40 |
| HULC | ABCD (Penuh) | D | 0,889 | 0,733 | 0,587 | 0,475 | 0,383 | 3.06 |
| HULC (dilatih ulang) | ABCD (Bahasa) | D | 0,892 | 0,701 | 0,548 | 0,420 | 0,335 | 2.90 |
| RT-1 (dilatih ulang) | ABCD (Bahasa) | D | 0,844 | 0,617 | 0,438 | 0,323 | 0,227 | 2.45 |
| Milik kita | ABCD (Bahasa) | D | 0,964 | 0,896 | 0,824 | 0,740 | 0,66 | 4.09 |
| MCIL | ABC (Penuh) | D | 0,304 | 0,013 | 0,002 | 0,000 | 0,000 | 0,31 |
| HULC | ABC (Penuh) | D | 0,418 | 0,165 | 0,057 | 0,019 | 0,011 | 0,67 |
| RT-1 (dilatih ulang) | ABC (Bahasa) | D | 0,533 | 0,222 | 0,094 | 0,038 | 0,013 | 0,90 |
| Milik kita | ABC (Bahasa) | D | 0,824 | 0,619 | 0,466 | 0,331 | 0,235 | 2.48 |
| HULC | ABCD (Penuh) | D (Memperkaya) | 0,715 | 0,470 | 0,308 | 0,199 | 0,130 | 1.82 |
| RT-1 (dilatih ulang) | ABCD (Bahasa) | D (Memperkaya) | 0,494 | 0,222 | 0,086 | 0,036 | 0,017 | 0,86 |
| Milik kita | ABCD (Bahasa) | D (Memperkaya) | 0,720 | 0,480 | 0,299 | 0,211 | 0,144 | 1.85 |
| Milik kita (beku-emb) | ABCD (Bahasa) | D (Memperkaya) | 0,737 | 0,530 | 0,385 | 0,275 | 0,192 | 2.12 |
Ikuti instruksi di OpenFlamingo dan CALVIN untuk mengunduh kumpulan data yang diperlukan dan Model VLM yang telah dilatih sebelumnya.
Download dataset CALVIN, pilih pemisahan dengan:
cd $HULC_ROOT /dataset
sh download_data.sh D | ABC | ABCD | debugUnduh model OpenFlamingo yang dirilis:
| # param | Model bahasa | Pembuat enkode visi | Interval xattn* | COCO 4-shot CIDer | Akurasi 4 tembakan VQAv2 | Rata-rata Len | beban |
|---|---|---|---|---|---|---|---|
| 3B | anas-awadalla/mpt-1b-redpajama-200b | buka CLIP ViT-L/14 | 1 | 77.3 | 45.8 | 3.94 | Link |
| 3B | anas-awadalla/mpt-1b-redpajama-200b-dolly | buka CLIP ViT-L/14 | 1 | 82.7 | 45.7 | 4.09 | Link |
| 4B | bersamakomputer/RedPajama-INCITE-Base-3B-v1 | buka CLIP ViT-L/14 | 2 | 81.8 | 49.0 | 3.67 | Link |
| 4B | bersamakomputer/RedPajama-INCITE-Instruct-3B-v1 | buka CLIP ViT-L/14 | 2 | 85.8 | 49.0 | 3.79 | Link |
| 9B | anas-awadalla/mpt-7b | buka CLIP ViT-L/14 | 4 | 89.0 | 54.8 | 3.97 | Link |
Ganti ${lang_encoder_path} dan ${tokenizer_path} kamus jalur (misalnya mpt_dict ) di robot_flamingo/models/factory.py untuk setiap VLM yang telah dilatih sebelumnya dengan jalur Anda sendiri.
Kloning repo ini
git clone https://github.com/RoboFlamingo/RoboFlamingo.git
Instal paket yang diperlukan:
cd RoboFlamingo
conda create -n RoboFlamingo python=3.8
source activate RoboFlamingo
pip install -r requirements.txt
torchrun --nnodes=1 --nproc_per_node=8 --master_port=6042 robot_flamingo/train/train_calvin.py
--report_to_wandb
--llm_name mpt_dolly_3b
--traj_cons
--use_gripper
--fusion_mode post
--rgb_pad 10
--gripper_pad 4
--precision fp32
--num_epochs 5
--gradient_accumulation_steps 1
--batch_size_calvin 6
--run_name RobotFlamingoDBG
--calvin_dataset ${calvin_dataset_path}
--lm_path ${lm_path}
--tokenizer_path ${tokenizer_path}
--openflamingo_checkpoint ${openflamingo_checkpoint}
--cross_attn_every_n_layers 4
--dataset_resampled
--loss_multiplier_calvin 1.0
--workers 1
--lr_scheduler constant
--warmup_steps 5000
--learning_rate 1e-4
--save_every_iter 10000
--from_scratch
--window_size 12 > ${log_file} 2>&1
${calvin_dataset_path} adalah jalur ke kumpulan data CALVIN;
${lm_path} adalah jalur menuju LLM terlatih;
${tokenizer_path} adalah jalur menuju tokenizer VLM;
${openflamingo_checkpoint} adalah jalur menuju model terlatih OpenFlamingo;
${log_file} adalah jalur ke file log.
Kami juga menyediakan robot_flamingo/pt_run_gripper_post_ws_12_traj_aug_mpt_dolly_3b.bash untuk meluncurkan pelatihan. Bash ini menyempurnakan model OpenFlamingo versi MPT-3B-IFT , yang berisi hyperparameter default untuk melatih model, dan sesuai dengan hasil terbaik dalam makalah ini.
python eval_ckpts.py
Dengan menambahkan nama dan direktori pos pemeriksaan ke eval_ckpts.py , skrip akan secara otomatis memuat model dan mengevaluasinya. Misalnya, jika Anda ingin mengevaluasi pos pemeriksaan di jalur 'jalur-pos pemeriksaan Anda', Anda dapat memodifikasi variabel ckpt_dir dan ckpt_names di eval_ckpts.py, dan hasil evaluasi akan disimpan sebagai 'logs/awalan-pos pemeriksaan Anda. mencatat'.
Hasil yang ditunjukkan di bawah ini menunjukkan bahwa pelatihan bersama dapat mempertahankan sebagian besar kemampuan tulang punggung VLM pada tugas-tugas VL, sekaligus kehilangan sedikit performa pada tugas-tugas robot.
menggunakan
bash robot_flamingo/pt_run_gripper_post_ws_12_traj_aug_mpt_dolly_3b_co_train.bash
untuk meluncurkan co-train RoboFlamingo dengan CoCO, VQAV2 dan CALVIN. Anda harus memperbarui jalur CoCO dan VQA di get_coco_dataset dan get_vqa_dataset di robot_flamingo/data/data.py .
| Membelah | SR 1 | SR 2 | SR 3 | SR 4 | SR 5 | Rata-rata Len |
|---|---|---|---|---|---|---|
| Kereta Bersama | ABC->D | 82,9% | 63,6% | 45,3% | 32,1% | 23,4% |
| Sempurnakan | ABC->D | 82,4% | 61,9% | 46,6% | 33,1% | 23,5% |
| Kereta Bersama | ABCD->D | 95,7% | 85,8% | 73,7% | 64,5% | 56,1% |
| Sempurnakan | ABCD->D | 96,4% | 89,6% | 82,4% | 74,0% | 66,2% |
| Kereta Bersama | ABCD->D (Memperkaya) | 67,8% | 45,2% | 29,4% | 18,9% | 11,7% |
| Sempurnakan | ABCD->D (Memperkaya) | 72,0% | 48,0% | 29,9% | 21,1% | 14,4% |
| kelapa | VQA | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| BIRU-1 | BIRU-2 | BIRU-3 | BIRU-4 | METEOR | PEMERAH_L | Sider | MEMBUMBUI | Acc | |
| Penyempurnaan (3B, bidikan nol) | 0,156 | 0,051 | 0,018 | 0,007 | 0,038 | 0,148 | 0,004 | 0,006 | 4.09 |
| Penyempurnaan (3B, 4 bidikan) | 0,166 | 0,056 | 0,020 | 0,008 | 0,042 | 0,158 | 0,004 | 0,008 | 3.87 |
| Co-Train (3B, tembakan nol) | 0,225 | 0,158 | 0,107 | 0,072 | 0,124 | 0,334 | 0,345 | 0,085 | 36.37 |
| Flamingo Asli (80B, disempurnakan) | - | - | - | - | - | - | 1.381 | - | 82.0 |
Logo dibuat menggunakan MidJourney
Pekerjaan ini menggunakan kode dari proyek dan kumpulan data sumber terbuka berikut:
Asli: https://github.com/mees/calvin Lisensi: MIT
Asli: https://github.com/openai/CLIP Lisensi: MIT
Asli: https://github.com/mlfoundations/open_flamingo Lisensi: MIT
@article{li2023vision,
title = {Vision-Language Foundation Models as Effective Robot Imitators},
author = {Li, Xinghang and Liu, Minghuan and Zhang, Hanbo and Yu, Cunjun and Xu, Jie and Wu, Hongtao and Cheang, Chilam and Jing, Ya and Zhang, Weinan and Liu, Huaping and Li, Hang and Kong, Tao},
journal={arXiv preprint arXiv:2311.01378},
year={2023}


