MambaTransformer
1.0.0

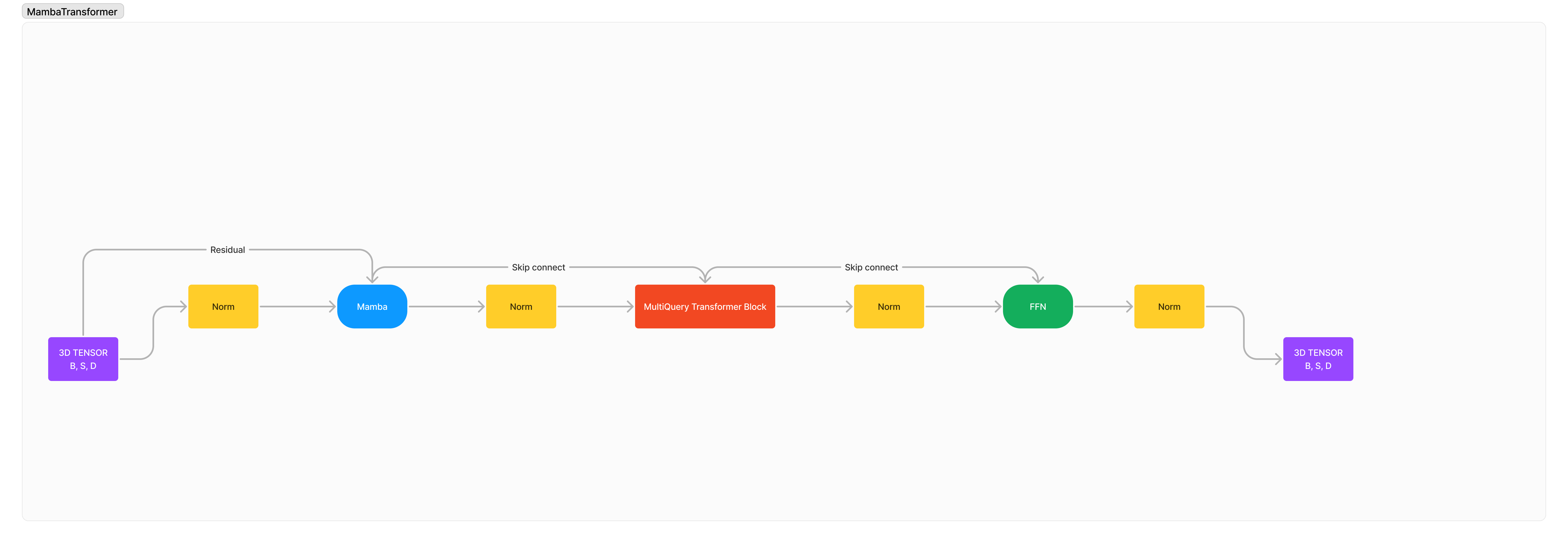
Mengintegrasikan Mamba/SSM dengan Transformer untuk Peningkatan Konteks Panjang dan Pemodelan Urutan Berkualitas Tinggi.
Ini adalah 100% arsitektur baru yang saya rancang untuk menggabungkan kekuatan dan kelemahan SSM dan Attention untuk arsitektur canggih yang sepenuhnya baru dengan tujuan melampaui batas lama kami. Kecepatan pemrosesan yang lebih cepat, konteks yang lebih panjang, kebingungan yang lebih rendah pada rangkaian yang panjang, penalaran yang ditingkatkan dan unggul namun tetap kecil dan kompak.
Arsitekturnya pada dasarnya adalah: x -> norm -> mamba -> norm -> transformer -> norm -> ffn -> norm -> out .
Saya menambahkan banyak normalisasi karena saya yakin secara default stabilitas pelatihan akan sangat menurun karena 2 arsitektur asing berintegrasi satu sama lain.
pip3 install mambatransformer
import torch
from mamba_transformer import MambaTransformer
# Generate a random tensor of shape (1, 10) with values between 0 and 99
x = torch . randint ( 0 , 100 , ( 1 , 10 ))
# Create an instance of the MambaTransformer model
model = MambaTransformer (
num_tokens = 100 , # Number of tokens in the input sequence
dim = 512 , # Dimension of the model
heads = 8 , # Number of attention heads
depth = 4 , # Number of transformer layers
dim_head = 64 , # Dimension of each attention head
d_state = 512 , # Dimension of the state
dropout = 0.1 , # Dropout rate
ff_mult = 4 , # Multiplier for the feed-forward layer dimension
return_embeddings = False , # Whether to return the embeddings,
transformer_depth = 2 , # Number of transformer blocks
mamba_depth = 10 , # Number of Mamba blocks,
use_linear_attn = True , # Whether to use linear attention
)
# Pass the input tensor through the model and print the output shape
out = model ( x )
print ( out . shape )
# After many training
model . eval ()
# Would you like to train this model? Zeta Corporation offers unmatchable GPU clusters at unbeatable prices, let's partner!
# Tokenizer
model . generate ( text )
MIT


