toyCarIRL
1.0.0
Pembelajaran penguatan (RL) adalah bentuk pembelajaran coba-coba yang paling mendasar dan paling intuitif, yaitu cara belajar sebagian besar organisme hidup dengan beberapa bentuk kemampuan berpikir. Sering juga disebut dengan belajar melalui eksplorasi, yaitu cara bayi manusia yang baru lahir belajar mengambil langkah pertamanya, yaitu dengan melakukan tindakan secara acak pada awalnya kemudian perlahan-lahan memikirkan tindakan yang mengarah pada gerak berjalan ke depan.
Catatan, postingan ini mengasumsikan pemahaman yang baik tentang kerangka pembelajaran Penguatan, harap biasakan diri Anda dengan RL melalui minggu ke 5 dan 6 dari kursus online AI_Berkeley yang mengagumkan ini.
Sekarang pertanyaan yang terus saya tanyakan pada diri saya adalah, apa yang mendorong pembelajaran semacam ini, apa yang memaksa agen mempelajari perilaku tertentu dalam cara yang dilakukannya. Setelah mempelajari lebih lanjut tentang RL, saya menemukan gagasan tentang imbalan , pada dasarnya agen mencoba memilih tindakannya sedemikian rupa sehingga imbalan yang didapat dari perilaku tertentu tersebut dimaksimalkan. Sekarang untuk membuat agen melakukan perilaku yang berbeda, struktur penghargaanlah yang harus dimodifikasi/dieksploitasi. Namun asumsikan kita hanya memiliki pengetahuan tentang perilaku pakar yang ada pada kita, lalu bagaimana kita memperkirakan struktur penghargaan berdasarkan perilaku tertentu di lingkungan? Nah, inilah permasalahan utama dari Inverse Reinforcement Learning (IRL) , di mana dengan adanya kebijakan pakar yang optimal (sebenarnya diasumsikan optimal), kami ingin menentukan struktur penghargaan yang mendasarinya.
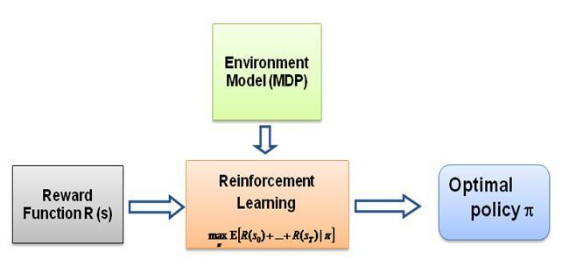
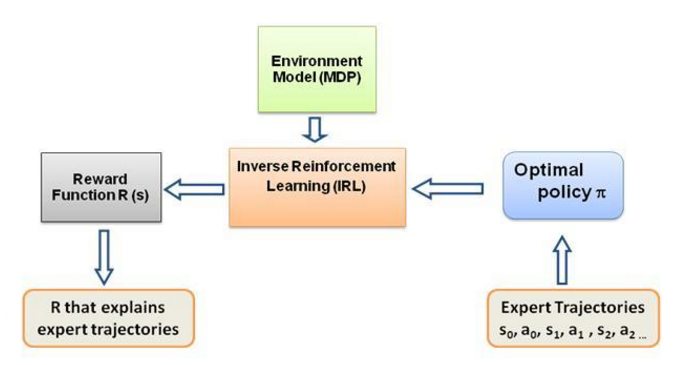
Sekali lagi, ini bukan postingan Pengantar Pembelajaran Penguatan Invers, melainkan tutorial tentang cara menggunakan/mengkode kerangka pembelajaran penguatan Invers untuk masalah Anda sendiri, tetapi IRL terletak pada intinya, dan sangat penting untuk diketahui tentangnya. itu dulu. IRL telah dipelajari secara ekstensif di masa lalu dan algoritma telah dikembangkan untuk itu, silakan baca makalah Ng dan Russell, 2000, dan Abbeel dan Ng, 2004 untuk informasi lebih lanjut.
Postingan ini mengadaptasi algoritma dari Abbeel dan Ng, 2004 untuk menyelesaikan masalah IRL.
Idenya di sini adalah untuk memprogram agen sederhana di dunia 2D yang penuh rintangan untuk menyalin/mengkloning berbagai perilaku di lingkungan, perilaku tersebut dimasukkan dengan bantuan lintasan ahli yang diberikan secara manual oleh manusia/ahli komputer. Bentuk pembelajaran dari demonstrasi ahli ini disebut Pembelajaran Magang dalam literatur ilmiah, yang intinya terletak pada Pembelajaran Penguatan terbalik, dan kami hanya mencoba mencari tahu fungsi penghargaan yang berbeda untuk perilaku yang berbeda ini.
Secara umum ya, sama saja, yaitu belajar dari demonstrasi (LfD). Kedua metode tersebut belajar dari demonstrasi, namun mempelajari hal yang berbeda:
Pembelajaran magang melalui pembelajaran penguatan terbalik akan mencoba menyimpulkan tujuan guru . Dengan kata lain, ia akan mempelajari fungsi penghargaan dari observasi, yang kemudian dapat digunakan dalam pembelajaran penguatan. Jika ia mengetahui bahwa tujuannya adalah memukul paku dengan palu, ia akan mengabaikan kedipan dan goresan dari gurunya, karena tidak relevan dengan tujuannya.
Pembelajaran imitasi (alias kloning perilaku) akan mencoba meniru langsung gurunya . Hal ini dapat dicapai dengan pembelajaran yang diawasi saja. AI akan mencoba meniru setiap tindakan, bahkan tindakan yang tidak relevan seperti berkedip, menggaruk, misalnya, atau bahkan kesalahan. Anda juga dapat menggunakan RL di sini, tetapi hanya jika Anda memiliki fungsi hadiah.
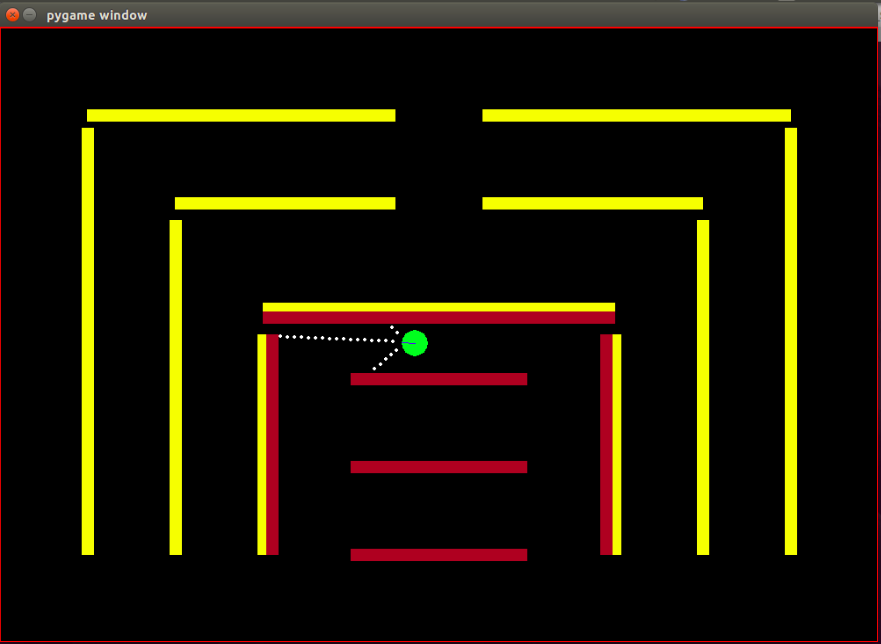
Agen: agen berbentuk lingkaran kecil berwarna hijau dengan arah arahnya ditandai dengan garis biru.
Sensor: agen dilengkapi dengan 3 sensor jarak dan warna, dan ini adalah satu-satunya informasi yang dimiliki agen tentang lingkungan.
State Space: keadaan agen terdiri dari 8 fitur yang dapat diamati-
Catatan, normalisasi dilakukan untuk memastikan bahwa setiap nilai fitur yang dapat diamati berada dalam kisaran [0,1] yang merupakan kondisi yang diperlukan agar algoritma IRL dapat konvergen.
Imbalan: imbalan setelah setiap bingkai dihitung sebagai kombinasi linier tertimbang dari nilai fitur yang diamati dalam masing-masing bingkai. Di sini reward r_t pada frame ke-t dihitung dengan perkalian titik dari vektor bobot w dengan vektor nilai fitur pada frame ke-t, yaitu vektor status phi_t. Sehingga r_t = w^T x phi_t.
Tindakan yang Tersedia: dengan setiap frame baru, agen secara otomatis mengambil langkah maju , tindakan yang tersedia dapat memutar agen ke kiri , ke kanan atau tidak melakukan apa pun yang merupakan langkah maju yang sederhana, perhatikan bahwa tindakan memutar mencakup gerakan maju juga, itu bukan merupakan rotasi di tempat.
Kendala: lingkungan terdiri dari tembok kaku, sengaja diwarnai dengan warna berbeda. Agen tersebut memiliki kemampuan penginderaan warna yang membantunya membedakan jenis penghalang. Lingkungan dirancang sedemikian rupa untuk memudahkan pengujian algoritma IRL.
Posisi awal (keadaan) bot ditetapkan, karena menurut algoritma IRL, keadaan awal harus sama untuk semua iterasi.
Perhatikan, bahwa algoritme RL sepenuhnya diadopsi dari postingan ini oleh Matt Harvey dengan sedikit perubahan, jadi sangat masuk akal untuk membicarakan perubahan yang telah saya buat, juga meskipun pembaca merasa nyaman dengan RL, saya sangat menyarankan untuk melihat sekilas ke atas. postingan tersebut untuk mendapatkan pemahaman tentang bagaimana pembelajaran penguatan berlangsung.
Lingkungan berubah secara signifikan, dengan agen mendapatkan kemampuan untuk tidak hanya merasakan jarak dari 3 sensor tetapi juga merasakan warna rintangan, memungkinkannya membedakan rintangan. Selain itu, ukuran agen kini lebih kecil dan titik penginderaannya kini lebih dekat untuk mendapatkan resolusi lebih besar dan kinerja lebih baik. Kendala harus dibuat statis untuk saat ini, untuk menyederhanakan proses pengujian algoritma IRL, hal ini mungkin menyebabkan overfitting data, tapi saya tidak mengkhawatirkan hal itu saat ini. Seperti yang dibahas di atas, kumpulan pengamatan atau status agen telah ditingkatkan dari 3 menjadi 8, dengan dimasukkannya fitur kerusakan pada status agen. Struktur hadiah telah diubah sepenuhnya, hadiah sekarang merupakan kombinasi linier tertimbang dari 8 fitur ini, agen tidak lagi menerima hadiah -500 jika menabrak rintangan, melainkan nilai fitur untuk menabrak adalah +1 dan tidak menabrak adalah 0 dan algoritmalah yang memutuskan bobot apa yang harus diberikan pada fitur ini berdasarkan perilaku pakar.
Seperti yang dinyatakan dalam blog Matt, tujuannya di sini adalah untuk tidak hanya mengajarkan agen RL untuk menghindari rintangan, maksud saya mengapa berasumsi apa pun tentang struktur imbalan, biarkan struktur imbalan sepenuhnya ditentukan oleh algoritma dari demonstrasi ahli dan lihat perilaku apa pengaturan imbalan tertentu tercapai!
Fitur atau fungsi dasar phi_i yang pada dasarnya dapat diamati di negara bagian. Fitur-fitur dalam permasalahan saat ini dibahas di atas pada bagian ruang keadaan. Kami mendefinisikan phi(s_t) sebagai jumlah dari semua ekspektasi fitur phi_i sehingga:
Hadiah r_t - kombinasi linier dari nilai fitur yang diamati di setiap negara bagian s_t.
Ekspektasi fitur mu(pi) dari suatu kebijakan pi adalah jumlah nilai fitur yang didiskon phi(s_t).
Ekspektasi fitur dari suatu kebijakan tidak bergantung pada bobotnya, mereka hanya bergantung pada negara bagian yang dikunjungi selama proses berjalan (menurut kebijakan) dan pada gamma faktor diskon berupa angka antara 0 dan 1 (misalnya 0,9 dalam kasus kami). Untuk mendapatkan ekspektasi fitur dari suatu kebijakan, kita harus menjalankan kebijakan secara real time dengan agen dan mencatat status yang dikunjungi serta nilai fitur yang diperoleh.
Ekspektasi fitur kebijakan pakar atau ekspektasi fitur pakar mu(pi_E) diperoleh dari tindakan yang diambil sesuai dengan perilaku pakar. Pada dasarnya kami menjalankan kebijakan ini dan mendapatkan fitur yang diharapkan seperti yang kami lakukan pada kebijakan lainnya. Ekspektasi fitur pakar diberikan kepada algoritme IRL untuk menemukan bobot sedemikian rupa sehingga fungsi imbalan yang sesuai dengan bobot tersebut menyerupai fungsi imbalan mendasar yang coba dimaksimalkan oleh pakar (dalam bahasa RL biasa).
Ekspektasi fitur kebijakan acak - jalankan kebijakan acak dan gunakan ekspektasi fitur yang diperoleh untuk menginisialisasi IRL.
Pertahankan daftar ekspektasi fitur kebijakan yang kami peroleh setelah setiap iterasi.
Pada awalnya kami hanya memiliki pi^1 -> ekspektasi fitur kebijakan acak.
Temukan kumpulan bobot pertama w^1 dengan optimasi cembung, masalahnya mirip dengan pengklasifikasi SVM yang mencoba memberikan label +1 pada fitur ahli yang diharapkan. dan -1 label untuk semua spesifikasi fitur kebijakan lainnya.-
seperti yang,
Kondisi penghentian:
Sekarang, setelah kita mendapatkan bobot setelah satu iterasi pengoptimalan, yaitu saat kita mendapatkan fungsi reward baru, kita harus mempelajari kebijakan yang memunculkan fungsi reward ini. Hal ini sama dengan mengatakan, temukan kebijakan yang mencoba memaksimalkan fungsi imbalan yang diperoleh ini. Untuk menemukan kebijakan baru ini, kita harus melatih algoritme Reinforcement Learning dengan fungsi penghargaan baru ini, dan melatihnya hingga nilai Q bertemu, untuk mendapatkan perkiraan kebijakan yang tepat.
Setelah kami mempelajari kebijakan baru, kami harus menguji kebijakan ini secara online, untuk mendapatkan ekspektasi fitur yang sesuai dengan kebijakan baru ini. Kemudian kami menambahkan ekspektasi fitur baru ini ke daftar ekspektasi fitur kami dan melanjutkan tanpa iterasi berikutnya dari algoritme IRL hingga konvergensi.
Sekarang mari kita mencoba memahami kodenya. Silakan Temukan kode lengkapnya di git repo ini. Terutama ada 3 file yang perlu Anda khawatirkan -
manualControl.py - untuk mendapatkan fitur yang diharapkan pakar dengan memindahkan agen secara manual. Jalankan "python3 manualControl.py", tunggu hingga gui dimuat, lalu gunakan tombol panah untuk mulai bergerak. Berikan perilaku yang ingin Anda salin (Perhatikan bahwa perilaku yang Anda harapkan akan disalin harus masuk akal dengan ruang status yang diberikan). Trik yang bagus adalah dengan menganggap diri Anda sebagai agen dan memikirkan apakah Anda dapat membedakan perilaku tertentu dengan mempertimbangkan ruang keadaan saat ini saja. Lihat file sumber untuk lebih jelasnya.
toy_car_IRL.py - file utama, di sinilah letak kode IRL. Mari kita lihat kode langkah demi langkah-
{% inti 51542f27e97eac1559a00f06b757df1a %}
Impor dependensi dan tentukan parameter penting, ubah PERILAKU sesuai kebutuhan. FRAMES adalah jumlah frame yang Anda inginkan agar algoritma RL dijalankan. 100K oke dan memakan waktu sekitar 2 jam.
{% inti 49b602b9a3090773d492310175bb2e3f %}
Buat kelas irlAgent yang mudah digunakan, yang mengambil perilaku acak dan ahli, serta parameter penting lainnya seperti yang ditunjukkan.
{% inti bc17c06a07ea3b915827e89f3c13a2ae %}
Fungsi getRLAgentFE menggunakan IRL_helper dari pembelajar penguatan untuk melatih model baru dan mendapatkan ekspektasi fitur dengan memainkan model tersebut untuk 2000 iterasi. Ini pada dasarnya mengembalikan ekspektasi fitur untuk setiap rangkaian bobot (W) yang didapat.
{% inti ce0ef99adc652c7469f1bc4303a3af41 %}
Untuk memperbarui kamus tempat kami menyimpan kebijakan yang diperoleh dan nilai tnya masing-masing. Dimana t = (bobot.tanspose)x(expert-newPolicy).
{% inti be55a5d44e5b1ff13dfa68cc96f6b1b1 %}
Implementasi algoritma IRL utama yang dibahas di atas. {% inti 9faee18596467ee33ac5d91fd0cb675f %}
Pengoptimalan cembung untuk memperbarui bobot setelah menerima kebijakan baru, pada dasarnya menetapkan label +1 untuk kebijakan pakar dan label -1 untuk semua kebijakan lainnya dan mengoptimalkan bobot di bawah batasan yang disebutkan. Untuk mengetahui lebih banyak tentang situs kunjungan optimasi ini
{% inti 30cf6c59b9915054f3cf6d278f8f8a11 %}
Buat irlAgent dan teruskan parameter yang diinginkan, pilih di antara jenis perilaku pakar yang bobotnya ingin Anda pelajari, lalu jalankan fungsi optimalWeightFinder(). Perhatikan bahwa saya telah memperoleh ekspektasi fitur untuk perilaku merah, kuning, dan coklat. Setelah algoritme berakhir, Anda akan mendapatkan daftar bobot di 'bobot-merah/kuning/coklat.txt', dengan PERILAKU yang dipilih masing-masing. Sekarang, untuk memilih perilaku terbaik dari semua bobot yang diperoleh, putar model yang disimpan di direktori saving-models_BEHAVIOR/evaluatedPolicies/, model disimpan dalam format berikut 'saved-models_'+ BEHAVIOR +'/evaluatedPolicies/'+ nomor iterasi+ '-164-150-100-50000-100000' + '.h5' . Pada dasarnya Anda akan mendapatkan bobot yang berbeda untuk iterasi yang berbeda, mainkan dulu modelnya untuk mengetahui model yang berkinerja terbaik, lalu catat nomor iterasi model tersebut, bobot yang diperoleh sesuai dengan nomor iterasi ini adalah bobot yang membuat Anda paling dekat dengan ahlinya. perilaku.
Dan kemudian ada file yang mungkin tidak perlu Anda perbarui/modifikasi, setidaknya untuk konten di postingan ini -
Setelah sekitar 10-15 iterasi, algoritme menyatu dalam 4 perilaku berbeda yang dipilih, saya memperoleh hasil berikut:
| beban | Saya suka kuning | Saya suka coklat | Saya suka Merah | Saya suka Menabrak |
|---|---|---|---|---|
| w1 (Distrik sensor kiri.) | -0,0880 | -0,2627 | 0,2816 | -0,5892 |
| w2 (jarak sensor tengah.) | -0,0624 | 0,0363 | -0,5547 | -0,3672 |
| w3 (jarak sensor kanan.) | 0,0914 | 0,0931 | -0,2297 | -0,4660 |
| w4 (Warna hitam) | -0,0114 | 0,0046 | 0,6824 | -0,0299 |
| w5 (warna kuning) | 0,6690 | -0,1829 | -0,3025 | -0,1528 |
| w6 (warna coklat) | -0,0771 | 0,6987 | 0,0004 | -0,0368 |
| w7 (warna merah) | -0,6650 | -0,5922 | 0,0525 | -0,5239 |
| w8 (kerusakan) | -0,2897 | -0,2201 | -0,0075 | 0,0256 |
Nilai negatif yang tinggi diberikan pada bobot yang termasuk dalam fitur bumping pada tiga perilaku pertama, karena 3 perilaku ahli ini tidak ingin agen menemui hambatan. Sedangkan bobot untuk fitur yang sama pada perilaku terakhir, yaitu bot Nasty, adalah positif, karena pakar perilaku menganjurkan bumping.
Rupanya bobot untuk fitur warna sesuai dengan perilaku ahli, tinggi bila warna tersebut diinginkan, sebaliknya nilai agak rendah/negatif untuk mendapatkan perilaku berbeda.
Bobot fitur jarak sangat ambigu (berlawanan dengan intuisi) dan sangat sulit untuk menemukan pola yang berarti dalam bobot. Satu-satunya hal yang ingin saya tunjukkan adalah bahwa perilaku searah jarum jam dan berlawanan arah jarum jam dapat dibedakan dalam pengaturan saat ini, fitur jarak akan membawa informasi ini.
Catatan, sangat penting untuk terlebih dahulu memikirkan apakah Anda sebagai manusia akan dapat membedakan antara perilaku tertentu dengan ketersediaan rangkaian keadaan saat ini (pengamatan) saat merancang struktur masalah. Jika tidak, Anda mungkin akan memaksa algoritme untuk menemukan bobot yang berbeda tanpa memberikan informasi yang diperlukan secara lengkap.
Jika Anda benar-benar ingin masuk ke IRL, saya sarankan Anda benar-benar mencoba mengajari agen perilaku baru (Anda mungkin harus mengubah lingkungan untuk itu, karena kemungkinan perilaku berbeda untuk kumpulan status saat ini telah dieksploitasi, yah setidaknya menurut saya).
Instal dependensi Pygame dengan:
sudo apt install mercurial libfreetype6-dev libsdl-dev libsdl-image1.2-dev libsdl-ttf2.0-dev libsmpeg-dev libportmidi-dev libavformat-dev libsdl-mixer1.2-dev libswscale-dev libjpeg-dev
Kemudian instal Pygame itu sendiri:
pip3 install hg+http://bitbucket.org/pygame/pygame
Ini adalah mesin fisika yang digunakan dalam simulasi. Itu baru saja melalui penulisan ulang yang cukup signifikan (v5) jadi Anda perlu menggunakan versi v4 yang lebih lama. v4 ditulis untuk Python 2 jadi ada beberapa langkah tambahan.
Kembali ke rumah Anda atau unduh dan dapatkan Pymunk 4:
wget https://github.com/viblo/pymunk/archive/pymunk-4.0.0.tar.gz
Buka kemasannya:
tar zxvf pymunk-4.0.0.tar.gz
Pembaruan dari Python 2 ke 3:
cd pymunk-pymukn-4.0.0/pymunk
2to3 -w *.py
Instal:
cd .. python3 setup.py install
Sekarang kembali ke tempat Anda mengkloning reinforcement-learning-car dan pastikan semuanya bekerja dengan python3 learning.py cepat. Jika Anda melihat layar muncul dengan titik kecil terbang di sekitar layar, Anda siap berangkat!
Pertama, Anda perlu melatih model. Ini akan menghemat bobot folder saved-models . Anda mungkin perlu membuat folder ini sebelum menjalankan . Anda dapat melatih model dengan menjalankan:
python3 learning.py
Diperlukan waktu mulai dari satu jam hingga 36 jam untuk melatih model, bergantung pada kompleksitas jaringan dan ukuran sampel Anda. Namun, ini akan mengeluarkan bobot setiap 25.000 frame, sehingga Anda dapat melanjutkan ke langkah berikutnya dalam waktu yang jauh lebih singkat.
Edit file playing.py untuk mengubah nama jalur model yang ingin Anda muat. Maaf tentang ini, saya tahu ini seharusnya menjadi argumen baris perintah.
Kemudian, saksikan mobil melaju melewati rintangan!
python3 playing.py
Hanya itu saja.


