WilmerAI
1.0.0
これは現在鋭意開発中の個人プロジェクトです。バグ、不完全なコード、またはその他の意図しない問題が含まれる可能性があり、実際に含まれる可能性があります。したがって、ソフトウェアは現状のまま提供され、いかなる種類の保証もありません。
WilmerAI は、1 人の開発者の仕事と個人的な時間とリソースの努力を反映しています。そこにある見解、方法論などは彼自身のものであり、彼の雇用主を反映すべきではありません。
WilmerAI は、受信プロンプトを受け取り、LLM API に送信する前にプロンプトに対してさまざまなタスクを実行するように設計された洗練されたミドルウェア システムです。この作業には、大規模言語モデル (LLM) を利用してプロンプトを分類し、適切なワークフローにルーティングすることや、大規模なコンテキスト (200,000 以上のトークン) を処理して、ほとんどのローカル モデルに適した、より小さく管理しやすいプロンプトを生成することが含まれます。
WilmerAI は、「言語モデルがすべての推論を専門的にルーティングしたらどうなるでしょうか?」の略です。
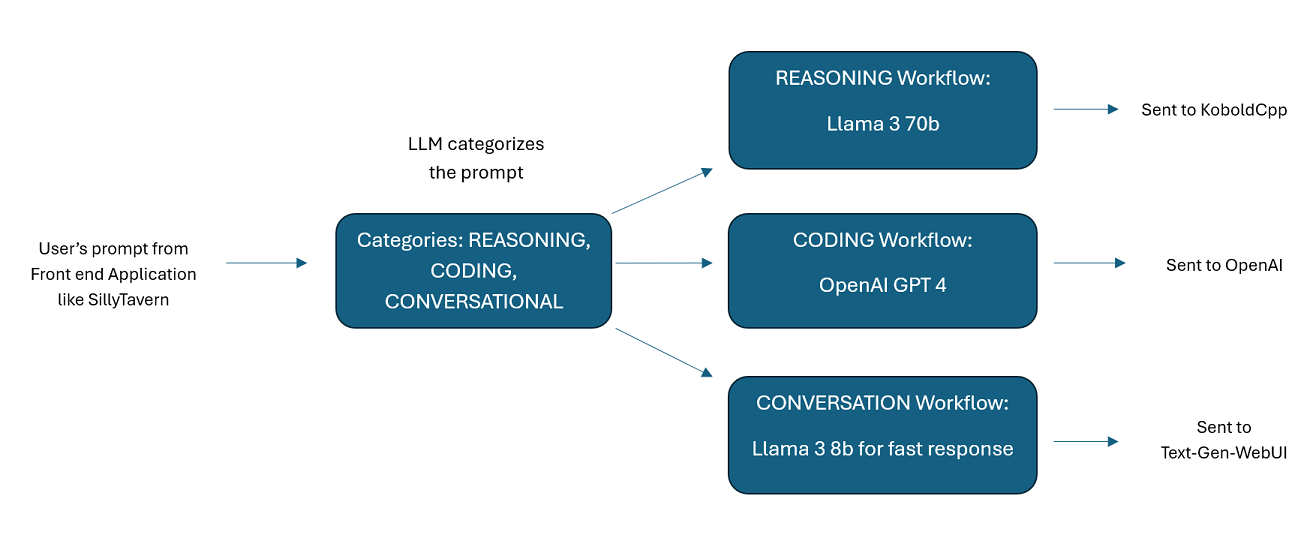
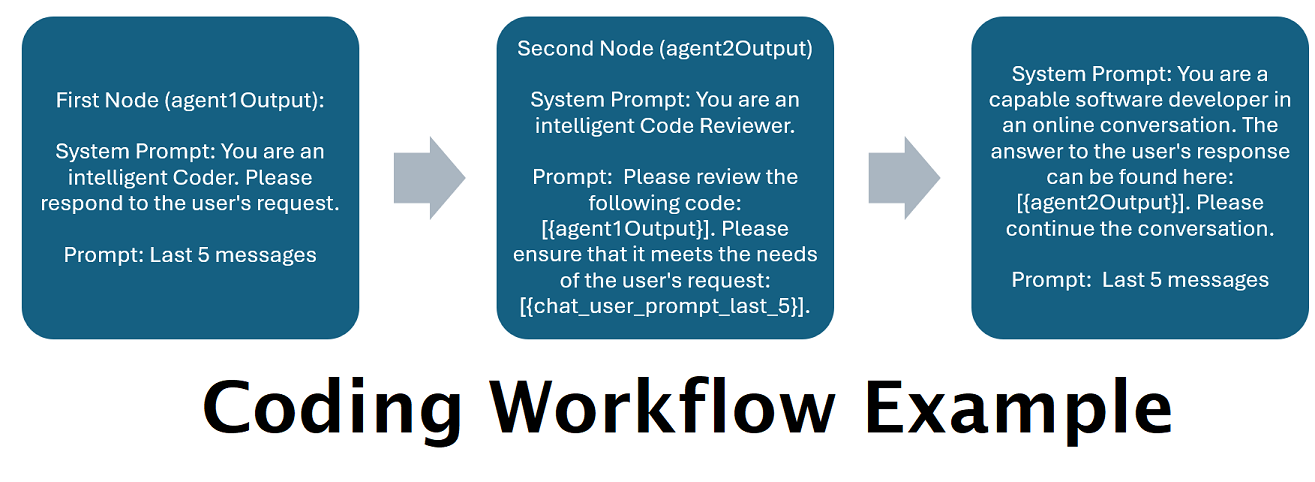
タンデムで複数の LLM を利用したアシスタント: 受信プロンプトを「カテゴリ」にルーティングでき、各カテゴリはワークフローによって強化されます。各ワークフローには必要な数のノードを含めることができ、各ノードは異なる LLM を使用します。たとえば、アシスタントに「Python でスネーク ゲームを書いてもらえますか?」と尋ねると、それはコーディングとして分類され、コーディング ワークフローに送られる可能性があります。そのワークフローの最初のノードは、Codestral-22b (または必要に応じて ChatGPT 4o) に質問への回答を求める可能性があります。 2 番目のノードは、Deepseek V2 または Claude Sonnet にコード レビューを依頼する場合があります。次のノードは、Codestral にもう一度最終結果を提示してから応答するように要求する可能性があります。ワークフローが最高のコーダーであるために応答する単一のモデルだけであるか、異なる LLM の多数のノードが連携して応答を生成しているかどうかは、選択次第です。
オフライン Wikipedia API のサポート: WilmerAI には、OfflineWikipediaTextApi を呼び出すことができるノードがあります。これは、受信メッセージを調べ、そのメッセージからクエリを生成し、Wikipedia API に関連記事をクエリし、その記事を RAG コンテキスト インジェクションとして使用して応答するカテゴリ (たとえば「FACTUAL」) を持つことができることを意味します。
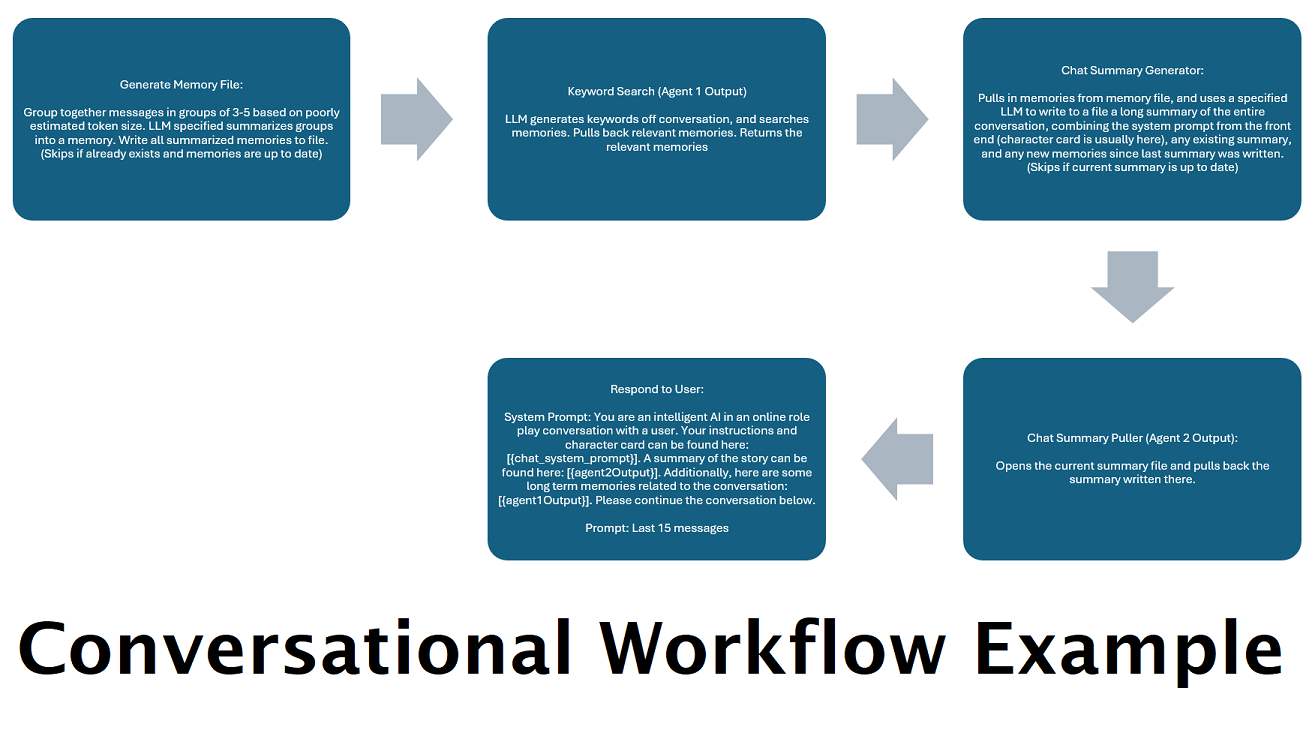
「メモリ」をシミュレートするために継続的に生成されるチャット概要: チャット概要ノードは、メッセージをチャンク化して要約し、ファイルに保存することによって「メモリ」を生成します。次に、それらの要約されたチャンクを取得して、会話全体の継続的で常に更新される要約を生成します。これは、LLM へのプロンプト内で取得して使用できます。その結果、LLM へのプロンプトを 5,000 コンテキスト以下に制限している場合でも、200,000 以上のコンテキスト会話を取得し、発言された内容を相対的に追跡することができます。
複数のコンピュータを使用してメモリと応答を並列処理する: LLM を実行できるコンピュータが 2 台ある場合、1 台を「レスポンダ」として指定し、もう 1 台をメモリ/要約の生成担当に指定できます。この種のワークフローでは、既存のメモリを使用しながら、メモリ/概要が更新されている間も LLM と対話し続けることができます。これは、大規模で強力なモデルにタスクの処理を依頼した場合でも、サマリーが更新されるのを待つ必要がないことを意味し、より高品質の記憶を得ることができます。 (ユーザー例convo-role-dual-modelを参照してください)
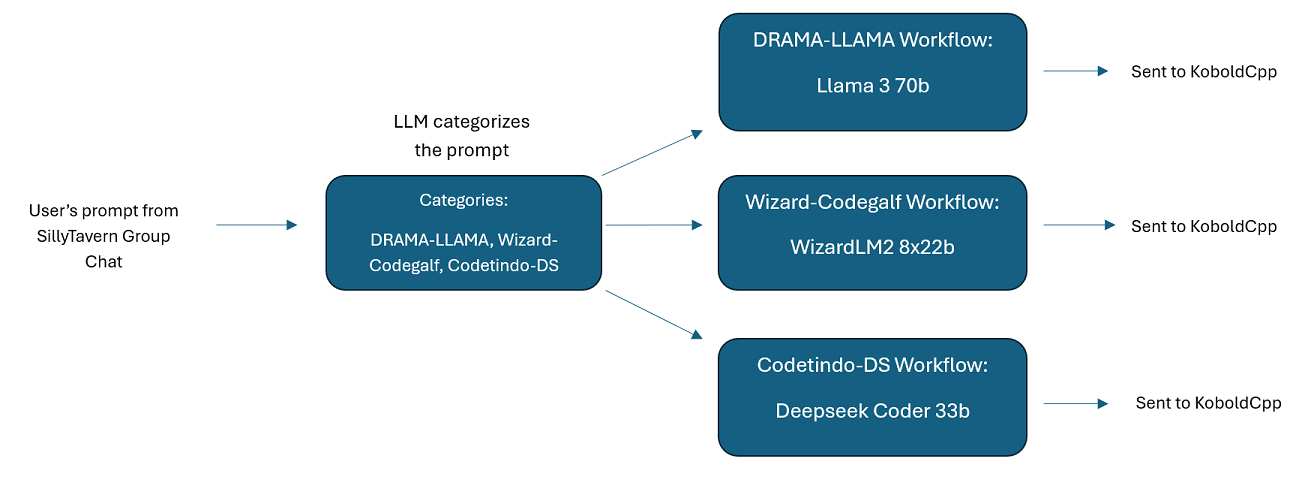
SillyTavern での複数 LLM グループ チャット: Wilmer を使用して、希望に応じて、すべての文字が異なる LLM である ST でグループ チャットを行うことができます (著者は個人的にこれを行っています)。 DocsSillyTavernで利用可能な文字例があります。 2つのグループに分かれます。これらのサンプルの文字/グループは、作成者が使用する大きなグループのサブセットです。
ミドルウェア機能: WilmerAI は、LLM (SillyTavern、OpenWebUI、または Python プログラムのターミナルなど) との通信に使用するインターフェイスと、LLM にサービスを提供するバックエンド API の間に位置します。複数のバックエンド LLM を同時に処理できます。
複数の LLM を同時に使用する:セットアップ例: SillyTavern -> WilmerAI -> KoboldCpp の複数のインスタンス。たとえば、Wilmer を Command-R 35b、Codestral 22b、Gemma-2-27b に接続し、ユーザーへの応答でそれらすべてを使用することができます。選択した LLM が v1/Completion エンドポイント、chat/Completion エンドポイント、または KoboldCpp の Generate エンドポイント経由で公開されている限り、それを使用できます。
カスタマイズ可能なプリセット: プリセットは、すぐにカスタマイズできる json ファイルに保存されます。パラメータ名を含め、ほぼすべてのプリセットを json 経由で管理できます。これは、新しいものを利用するために Wilmer のアップデートを待つ必要がないことを意味します。たとえば、DRY は最近 KoboldCpp で登場しました。それが Wilmer のプリセット json に含まれていない場合は、単純に追加して使用を開始できるはずです。
API エンドポイント:フロントエンド経由で接続できる OpenAI API 互換のchat/Completionsおよびv1/Completionsエンドポイントを提供し、バックエンドのどちらのタイプにも接続できます。これにより、v1/Completion API として Wilmer に接続し、その後 Wilmer をチャット/Completion、v1/Completion KoboldCpp Generate エンドポイントにすべて同時に接続するなど、複雑な構成が可能になります。
プロンプト テンプレート: v1/Completions API エンドポイントのプロンプト テンプレートをサポートします。 WilmerAI には、 v1/Completionsを介したフロントエンドからの接続用の独自のプロンプト テンプレートもあります。テンプレートは「Docs」フォルダーにあり、SillyTavern にアップロードする準備ができています。

ワークフローはその性質上、設定方法に応じて API エンドポイントに対して多数の呼び出しを行う可能性があることに注意してください。 WilmerAI はトークンの使用状況を追跡せず、API を介して正確なトークンの使用状況を報告せず、トークンの使用状況を監視する実行可能な方法も提供しません。したがって、コスト上の理由からトークンの使用状況の追跡が重要である場合は、特にこのソフトウェアに慣れてきた初期の段階で、LLM API によって提供されるダッシュボードを介して、使用しているトークンの数を必ず追跡してください。
LLM は、WilmerAI の品質に直接影響します。これは LLM 主導のプロジェクトであり、フローと出力はほぼ完全に接続された LLM とその応答に依存します。低品質の出力を生成するモデルに Wilmer を接続した場合、またはプリセットまたはプロンプト テンプレートに欠陥がある場合、Wilmer の全体的な品質も大幅に低下します。この点では、エージェント ワークフローとあまり変わりません。
著者は有用で高品質なものを作成するために最善を尽くしていますが、これは野心的な個人プロジェクトであり、必ず問題があるでしょう (特に著者は生来 Python 開発者ではなく、これを実現するために AI に大きく依存しているため)遠い)。しかし、彼は徐々にそれを理解し始めています。
Wilmer は、OpenAI v1/Completions エンドポイントと chat/Completions エンドポイントの両方を公開し、ほとんどのフロントエンドと互換性を持たせています。私はこれを主に SillyTavern で使用しましたが、Open-WebUI でも動作する可能性があります。
SillyTavern でテキスト補完として接続するには、次の手順に従います (以下のスクリーンショットは SillyTavern からのものです)。
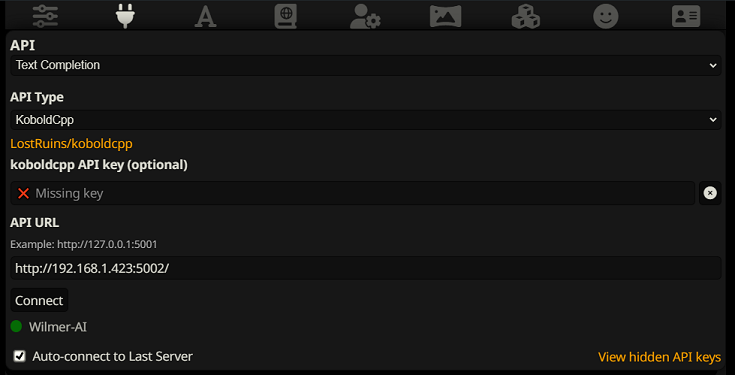
テキスト補完を使用する場合は、WilmerAI 固有のプロンプト テンプレート形式を使用する必要があります。インポート可能な ST ファイルはDocs/SillyTavern/InstructTemplate内にあります。同様に使用したい場合は、コンテキスト テンプレートも含まれています。
指示テンプレートは次のようになります。
[Beg_Sys]You are an intelligent AI Assistant.[Beg_User]SomeOddCodeGuy: Hey there![Beg_Assistant]Wilmer: Hello![Beg_User]SomeOddCodeGuy: This is a test[Beg_Assistant]Wilmer: Nice.
SillyTavern より:
"input_sequence": "[Beg_User]",
"output_sequence": "[Beg_Assistant]",
"first_output_sequence": "[Beg_Assistant]",
"last_output_sequence": "",
"system_sequence_prefix": "[Beg_Sys]",
"system_sequence_suffix": "",
タグ間には改行や文字が含まれないことが予想されます。
コンテキスト テンプレートが「有効」であることを確認してください (ドロップダウンの上のチェックボックス)
SillyTavern でチャット完了として接続するには、次の手順に従います (以下のスクリーンショットは SillyTavern からのものです)。
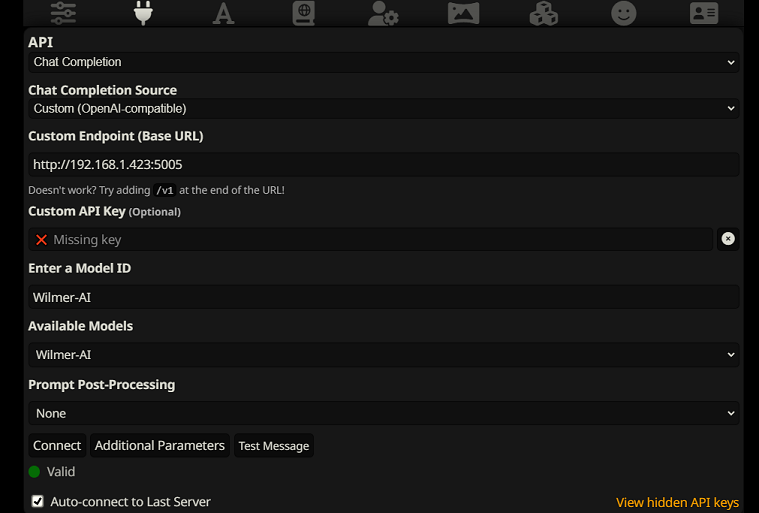
chatCompleteAddUserAssistant true に設定します。 (両方を同時に true に設定することはお勧めしません。SillyTavern からのキャラクター名、または Wilmer からのユーザー/アシスタントのいずれかを設定します。そうしないと AI が混乱する可能性があります。)どちらの接続タイプでも、SillyTavern の「A」アイコンに移動し、指示モードで「名前を含める」と「グループとペルソナを強制する」を選択し、次に左端のアイコン (サンプラーがある場所) に移動して「」にチェックを入れることをお勧めします。左上で「stream」をクリックし、右上でコンテキストの下で「ロック解除」をチェックし、200,000+ までドラッグします。文脈についてはウィルマーに任せましょう。
現在、Wilmer にはユーザー インターフェイスがありません。すべては「Public」フォルダーにある JSON 構成ファイルによって制御されます。このフォルダーには、重要な構成がすべて含まれています。 WilmerAI の新しいコピーを更新またはダウンロードする場合は、設定を保持するために「Public」フォルダーを新しいインストールにコピーするだけです。
このセクションでは、Wilmer のセットアップについて説明します。セクションをステップに分けました。各ステップを 1 つずつ LLM にコピーし、セクションの設定を手伝ってもらうことをお勧めします。これにより、作業がはるかに簡単になる可能性があります。
重要な注意事項
Wilmer セットアップに関して 3 つのことに注意することが重要です。
A) プリセット ファイルは 100% カスタマイズ可能です。そのファイルの内容は llm API に送られます。これは、クラウド API は、ローカル LLM API が処理するさまざまなプリセットの一部を処理しないためです。そのため、OpenAI API またはその他のクラウド サービスを使用する場合、通常のローカル AI プリセットのいずれかを使用すると、呼び出しはおそらく失敗します。 openAI が受け入れるものの例については、プリセット「OpenAI-API」を参照してください。
B) 最近、Wilmer のすべてのプロンプトを二人称から三人称に置き換えました。これは私にとってかなり良い結果をもたらしました、そしてあなたにとっても同様であることを願っています。
C) デフォルトでは、すべてのユーザー ファイルはストリーミング応答をオンにするように設定されています。 Wilmer を呼び出すフロントエンドでこれを有効にして両方が一致するようにするか、Users/username.json に移動して Stream を「false」に設定する必要があります。フロントエンドがストリーミングを期待している/していないが、ウィルマーがその逆を期待しているなど、不一致がある場合、フロントエンドには何も表示されない可能性があります。
Wilmer のインストールは簡単です。 Python がインストールされていることを確認してください。著者は Python 3.10 および 3.12 でプログラムを使用していますが、どちらも正常に動作します。
オプション 1: 提供されたスクリプトの使用
便宜上、Wilmer には Windows 用の BAT ファイルと macOS 用の .sh ファイルが含まれています。これらのスクリプトは仮想環境を作成し、 requirements.txtから必要なパッケージをインストールしてから、Wilmer を実行します。これらのスクリプトを使用して、Wilmer を毎回起動できます。
.batファイルを実行します。.shファイルを実行します。重要:危険を伴う可能性があるため、最初に検査せずに BAT または SH ファイルを実行しないでください。このようなファイルの安全性が不明な場合は、メモ帳またはテキストエディットでそのファイルを開き、内容をコピーしてから、潜在的な問題がないか LLM に確認してもらいます。
オプション 2: 手動インストール
あるいは、依存関係を手動でインストールし、次の手順で Wilmer を実行することもできます。
必要なパッケージをインストールします。
pip install -r requirements.txtプログラムを開始します。
python server.py提供されたスクリプトは、仮想環境をセットアップすることでプロセスを効率化するように設計されています。ただし、手動インストールを希望する場合は、無視しても問題ありません。
注: Bat ファイル、sh ファイル、または Python ファイルのいずれかを実行する場合、これら 3 つすべてが次のオプションの引数を受け入れるようになりました。
したがって、たとえば、次のような実行が考えられる場合を考えてみましょう。
bash run_macos.sh (_current-user.json で指定されたユーザー、「Public」の構成、「logs」のログを使用します)bash run_macos.sh --User "single-model-assistant" (構成の場合はデフォルトで public、ログの場合は "log" になります)bash run_macos.sh --ConfigDirectory "/users/socg/Public/configs" --User "single-model-assistant" ("logs" にはデフォルトのみを使用します)bash run_macos.sh --ConfigDirectory "/users/socg/Public/configs" --User "single-model-assistant" --LoggingDirectory "/users/socg/wilmerlogs"これらのオプションの引数を使用すると、ユーザーは WilmerAI の複数のインスタンスを起動でき、各インスタンスは異なるユーザー プロファイルを使用し、異なる場所にログインし、必要に応じて異なる場所の構成を指定できます。
Public/Configs 内には、json ファイルを含む一連のフォルダーがあります。最も関心のある 2 つは、 EndpointsフォルダーとUsersフォルダーです。
注: assistant-single-model 、 assistant-multi-model 、およびgroup-chat-exampleユーザーの Factual ワークフロー ノードは、OfflineWikipediaTextApi プロジェクトを利用して、Wikipedia 記事全体を RAG にプルしようとします。この API がない場合でも、ワークフローに問題はありませんが、私は個人的にこの API を使用して、得られる事実に基づく回答を改善しています。選択したユーザー json で API に IP アドレスを指定できます。
まず、使用するテンプレート ユーザーを選択します。
Assistant-single-model : このテンプレートは、すべてのノードで使用される単一の小さなモデル用です。これには、さまざまなカテゴリ タイプのルートもあり、各ノードに適切なプリセットが使用されます。モデルが 1 つしかないのに、なぜさまざまなカテゴリにルートがあるのか疑問に思っている場合は、各カテゴリに独自のプリセットを与えるため、また、それらのカスタム ワークフローを作成できるようにするためです。おそらく、プログラマーに自身をチェックするために複数の反復を実行させたり、複数のステップで物事を検討する推論を求めたりすることがあります。
Assistant-multi-model : このテンプレートは、多くのモデルを連携して使用するためのものです。このユーザーのエンドポイントを見ると、すべてのカテゴリに独自のエンドポイントがあることがわかります。複数のカテゴリに対して同じ API を再利用することを妨げるものはまったくありません。たとえば、コーディング、数学、推論には Llama 3.1 70b を使用し、分類、会話、事実には Command-R 35b 08-2024 を使用できます。 10 種類の異なるモデルが必要だとは思わないでください。これは単に、必要に応じてたくさん持ち込めるようにするためです。このユーザーは、ワークフロー内の各ノードに適切なプリセットを使用します。
convo-roleplay-single-model : このユーザーは、会話に適しており、ロールプレイにも適しているはずのカスタム ワークフローを持つ単一モデルを使用しています (必要に応じて調整するためのフィードバックを待っています)。これにより、すべてのルーティングがバイパスされます。
convo-roleplay-dual-model : このユーザーは、会話に適しており、ロールプレイにも適しているはずのカスタム ワークフローで 2 つのモデルを使用しています (必要に応じて調整するためのフィードバックを待っています)。これにより、すべてのルーティングがバイパスされます。注: このワークフローは、LLM を実行できるコンピュータが 2 台ある場合に最適に機能します。このユーザーの現在の設定では、Wilmer にメッセージを送信すると、レスポンダー モデル (コンピューター 1) が応答します。その後、ワークフローはその時点で「ワークフロー ロック」を適用します。記憶/チャット要約モデル (コンピューター 2) は、これまでの会話の記憶と要約の更新を開始し、内容を思い出すのを助けるために応答者に渡されます。メモリの書き込み中に別のプロンプトを送信すると、応答側 (コンピュータ 1) は存在するサマリーを取得して、先に進み、応答します。ワークフロー ロックにより、新しい思い出セクションに再度入ることができなくなります。これが意味するのは、新しい記憶が書き込まれている間もレスポンダー モデルとの会話を続けることができるということです。これはパフォーマンスを大幅に向上させます。試してみましたが、応答時間は驚くべきものでした。これがないと、30秒以内に3〜5回応答があり、その後、思い出を生成するために突然2分間待機します。これにより、私の Mac Studio の Llama 3.1 70b では、すべてのメッセージが毎回 30 秒になります。
group-chat-example : このユーザーは私自身の個人的なグループ チャットの例です。掲載されているキャラクターやグループは私が実際に使用しているキャラクターやグループです。サンプル文字はDocs/SillyTavernフォルダーにあります。これらは SillyTavern と互換性のある文字であり、そのプログラムまたは .png 文字インポート タイプをサポートするプログラムに直接インポートできます。開発チームのキャラクターはワークフローごとに 1 つのノードのみを持ち、単にユーザーに応答します。諮問グループのキャラクターにはワークフローごとに 2 つのノードがあります。最初のノードは応答を生成し、2 番目のノードはキャラクターの「ペルソナ」を強制します (これを担当するエンドポイントはbusinessgroup-speakerエンドポイントです)。グループ チャットのペルソナは、たとえ 1 つのモデルしか使用していない場合でも、得られる応答を変えるのに非常に役立ちます。ただし、すべてのキャラクターに異なるモデルを使用することを目指しています (ただし、グループ間でモデルを再利用します。そのため、たとえば、各グループに Llama 3.1 70b モデルのキャラクターを配置します)。
使用するユーザーを選択したら、いくつかの手順を実行します。
Public/Configs/Endpoints でユーザーのエンドポイントを更新します。サンプルキャラクターはそれぞれのフォルダーに分類されています。ユーザーのエンドポイント フォルダーは、user.json ファイルの下部で指定されます。使用している LLM に合わせて、すべてのエンドポイントを適切に入力する必要があります。 _example-endpointsフォルダーの下にいくつかのエンドポイントの例があります。
現在のユーザーを設定する必要があります。これは、bat/sh/py ファイルの実行時に --User 引数を使用して行うことも、Public/Configs/Users/_current-user.json で行うこともできます。ユーザーの名前を現在のユーザーとして入力して保存するだけです。
ユーザーの JSON ファイルを開いて、オプションを確認してみるとよいでしょう。ここでは、ストリーミングするかどうかを設定したり、オフライン Wiki API (使用している場合) に IP アドレスを設定したり、DiscussionId フロー中に思い出や概要ファイルを送信する場所を指定したり、保存先を指定したりできます。ワークフロー ロックを使用する場合は、sqllite データベースを移動させたい。
それでおしまい! Wilmer を実行して接続すれば準備完了です。
まず、エンドポイントとモデルを設定します。 Public/Configs フォルダー内に次のサブフォルダーが表示されるはずです。必要なものを見ていきましょう。
これらの構成ファイルは、接続している LLM API エンドポイントを表します。たとえば、次の JSON ファイルSmallModelEndpoint.jsonエンドポイントを定義します。
{
"modelNameForDisplayOnly" : " Small model for all tasks " ,
"endpoint" : " http://127.0.0.1:5000 " ,
"apiTypeConfigFileName" : " KoboldCpp " ,
"maxContextTokenSize" : 8192 ,
"modelNameToSendToAPI" : " " ,
"promptTemplate" : " chatml " ,
"addGenerationPrompt" : true
}これらの構成ファイルは、Wilmer の使用時に発生する可能性のあるさまざまな API タイプを表します。
{
"nameForDisplayOnly" : " KoboldCpp Example " ,
"type" : " koboldCppGenerate " ,
"presetType" : " KoboldCpp " ,
"truncateLengthPropertyName" : " max_context_length " ,
"maxNewTokensPropertyName" : " max_length " ,
"streamPropertyName" : " stream "
}これらのファイルは、モデルのプロンプト テンプレートを指定します。次の例llama3.jsonを考えてみましょう。
{
"promptTemplateAssistantPrefix" : " <|start_header_id|>assistant<|end_header_id|> nn " ,
"promptTemplateAssistantSuffix" : " <|eot_id|> " ,
"promptTemplateEndToken" : " " ,
"promptTemplateSystemPrefix" : " <|start_header_id|>system<|end_header_id|> nn " ,
"promptTemplateSystemSuffix" : " <|eot_id|> " ,
"promptTemplateUserPrefix" : " <|start_header_id|>user<|end_header_id|> nn " ,
"promptTemplateUserSuffix" : " <|eot_id|> "
}これらのテンプレートは、すべての v1/Completion エンドポイント呼び出しに適用されます。テンプレートを使用したくない場合は、メッセージを改行のみで分割する_chatonly.jsonというファイルがあります。
ユーザーの作成とアクティブ化には、4 つの主要な手順が必要です。新しいユーザーを設定するには、以下の手順に従ってください。
まず、 Usersフォルダー内に新しいユーザーの JSON ファイルを作成します。これを行う最も簡単な方法は、既存のユーザー JSON ファイルをコピーし、複製として貼り付けて、名前を変更することです。ユーザー JSON ファイルの例を次に示します。
{
"port" : 5006 ,
"stream" : true ,
"customWorkflowOverride" : false ,
"customWorkflow" : " CodingWorkflow-LargeModel-Centric " ,
"routingConfig" : " assistantSingleModelCategoriesConfig " ,
"categorizationWorkflow" : " CustomCategorizationWorkflow " ,
"defaultParallelProcessWorkflow" : " SlowButQualityRagParallelProcessor " ,
"fileMemoryToolWorkflow" : " MemoryFileToolWorkflow " ,
"chatSummaryToolWorkflow" : " GetChatSummaryToolWorkflow " ,
"conversationMemoryToolWorkflow" : " CustomConversationMemoryToolWorkflow " ,
"recentMemoryToolWorkflow" : " RecentMemoryToolWorkflow " ,
"discussionIdMemoryFileWorkflowSettings" : " _DiscussionId-MemoryFile-Workflow-Settings " ,
"discussionDirectory" : " D: \ Temp " ,
"sqlLiteDirectory" : " D: \ Temp " ,
"chatPromptTemplateName" : " _chatonly " ,
"verboseLogging" : true ,
"chatCompleteAddUserAssistant" : true ,
"chatCompletionAddMissingAssistantGenerator" : true ,
"useOfflineWikiApi" : true ,
"offlineWikiApiHost" : " 127.0.0.1 " ,
"offlineWikiApiPort" : 5728 ,
"endpointConfigsSubDirectory" : " assistant-single-model " ,
"useFileLogging" : false
}0.0.0.0でホストされており、別のコンピュータで実行されている場合にネットワーク上に表示されます。異なるポートでの Wilmer の複数のインスタンスの実行がサポートされています。trueの場合、ルーターは無効になり、すべてのプロンプトは指定されたワークフローにのみ表示され、Wilmer の単一のワークフロー インスタンスになります。customWorkflowOverrideがtrueの場合に使用するカスタム ワークフロー。Routingフォルダーからの、 .json拡張子を除いたルーティング構成ファイルの名前。DiscussionId使用するときのクラッシュを避けるために、このディレクトリが存在することを確認してください。chatCompleteAddUserAssistantがtrueの場合にのみ使用されます。DataFinder文字に使用するかを指定します。次に、 _current-user.jsonファイルを更新して、使用するユーザーを指定します。 .json拡張子を除いた、新しいユーザー JSON ファイルの名前と一致します。
注: Wilmer を実行するときに --User 引数を代わりに使用する場合は、これを無視できます。
Routingフォルダーにルーティング JSON ファイルを作成します。このファイルには任意の名前を付けることができます。ユーザー JSON ファイルのroutingConfigプロパティを、 .json拡張子を除いたこの名前で更新します。ルーティング構成ファイルの例を次に示します。
{
"CODING" : {
"description" : " Any request which requires a code snippet as a response " ,
"workflow" : " CodingWorkflow "
},
"FACTUAL" : {
"description" : " Requests that require factual information or data " ,
"workflow" : " ConversationalWorkflow "
},
"CONVERSATIONAL" : {
"description" : " Casual conversation or non-specific inquiries " ,
"workflow" : " FactualWorkflow "
}
}.json拡張子を除いたワークフロー JSON ファイルの名前。 Workflowフォルダー内に、 Usersフォルダーのユーザー名と一致する新しいフォルダーを作成します。これを行う最も簡単な方法は、既存のユーザーのフォルダーをコピーして複製し、名前を変更することです。
他に変更を加えないことを選択した場合は、ワークフローを実行し、必要なエンドポイントを指すようにエンドポイントを更新する必要があります。 Wilmer で追加されたサンプル ワークフローを使用している場合は、ここですでに問題ないはずです。
「Public」フォルダー内には以下が必要です。
このプロジェクトのワークフローは、ユーザー固有のワークフロー フォルダー内のPublic/Workflowsフォルダーで変更および制御されます。たとえば、ユーザーの名前がsocgで、 Usersフォルダーにsocg.jsonファイルがある場合、ワークフロー内にはWorkflows/socgフォルダーが必要です。
ワークフロー JSON がどのようになるかの例を次に示します。
[
{
"title" : " Coding Agent " ,
"agentName" : " Coder Agent One " ,
"systemPrompt" : " You are an exceptionally powerful and intelligent technical AI that is currently in a role play with a user in an online chat. n The instructions for the roleplay can be found below: n [ n {chat_system_prompt} n ] n Please continue the conversation below. Please be a good team player. This means working together towards a common goal, and does not always include being overly polite or agreeable. Disagreement when the other user is wrong can help foster growth in everyone, so please always speak your mind and critically review your peers. Failure to correct someone who is wrong could result in the team's work being a failure. " ,
"prompt" : " " ,
"lastMessagesToSendInsteadOfPrompt" : 6 ,
"endpointName" : " SocgMacStudioPort5002 " ,
"preset" : " Coding " ,
"maxResponseSizeInTokens" : 500 ,
"addUserTurnTemplate" : false
},
{
"title" : " Reviewing Agent " ,
"agentName" : " Code Review Agent Two " ,
"systemPrompt" : " You are an exceptionally powerful and intelligent technical AI that is currently in a role play with a user in an online chat. " ,
"prompt" : " You are in an online conversation with a user. The last five messages can be found here: n [ n {chat_user_prompt_last_five} n ] n You have already considered this request quietly to yourself within your own inner thoughts, and come up with a possible answer. The answer can be found here: n [ n {agent1Output} n ] n Please critically review the response, reconsidering your initial choices, and ensure that it is accurate, complete, and fulfills all requirements of the user's request. nn Once you have finished reconsidering your answer, please respond to the user with the correct and complete answer. nn IMPORTANT: Do not mention your inner thoughts or make any mention of reviewing a solution. The user cannot see the answer above, and any mention of it would confuse the user. Respond to the user with a complete answer as if it were the first time you were answering it. " ,
"endpointName" : " SocgMacStudioPort5002 " ,
"preset" : " Coding " ,
"maxResponseSizeInTokens" : 1000 ,
"addUserTurnTemplate" : true
}
]上記のワークフローは会話ノードで構成されています。どちらのノードも、エンドポイントで指定された LLM にメッセージを送信するという 1 つの単純な処理を実行します。
titleに似ています。エージェントの出力を追跡するには、これらに「One」、「Two」などで終わる名前を付けると便利です。最初のノードの出力は{agent1Output}に保存され、2 番目のノードの出力は{agent2Output}に保存されます。.json拡張子を除いた、 Endpointsフォルダーの JSON ファイル名と一致する必要があります。.json拡張子を除いた、 Presetsフォルダーの JSON ファイル名と一致する必要があります。falseに設定します (上記の最初のノード例を参照)。プロンプトを送信する場合は、これをtrueに設定します (上記の 2 番目のノード例を参照)。 NOTE: The addDiscussionIdTimestampsForLLM feature was an experiment, and truthfully I am not happy with how the experiment went. Even the largest LLMs misread the timestamps, got confused by them, etc. I have other plans for this feature which should be far more useful, but I left it in and won't be removing it, even though I don't necessarily recommend using it. -Socg
これらのプロンプト内のいくつかの変数を使用できます。これらは、実行時に適切に交換されます。
{chat_user_prompt_last_one} :メッセージをラップするプロンプトテンプレートタグなしで、会話の最後のメッセージ。{templated_user_prompt_last_one} :会話の最後のメッセージは、適切なユーザー/アシスタントプロンプトテンプレートタグに巻き付けられています。{chat_system_prompt} :フロントエンドから送信されるシステムプロンプト。多くの場合、キャラクターカードやその他の重要な情報が含まれています。{templated_system_prompt} :適切なシステムプロンプトテンプレートタグにラップされたフロントエンドからのシステムプロンプト。{agent#Output} : #必要な数に置き換えられます。すべてのノードはエージェント出力を生成します。最初のノードは常に1であり、各ノード増分は1です。たとえば、最初のノードの場合は{agent1Output} 、 {agent2Output}は2番目です。{category_colon_descriptions} : Routing JSONファイルからカテゴリと説明をプルします。{categoriesSeparatedByOr} :「または」で区切られたカテゴリ名を引いてください。[TextChunk] :パラレルプロセッサに固有の特別な変数であり、頻繁に使用されない可能性があります。注:思い出がどのように機能するかをより深く理解するために、理解の思い出セクションをご覧ください
このノードは、nの数のメモリ(またはDiscussionIDが存在しない場合は最新のメッセージ)を引き出し、それらの間にカスタムデリミタを追加します。したがって、3つのメモリのメモリファイルがあり、「 n -------- n」の区切り文字を選択した場合は、次のことを取得できます。
This is the first memory
---------
This is the second memory
---------
This is the third memory
このノードとチャットの概要を組み合わせることで、LLMは会話全体の要約された内訳だけでなく、要約が構築されたすべての記憶のリストも受け取ることができます。それ。これらの両方を最後の15-20のメッセージと一緒に送信すると、チャット全体の継続的で永続的なメモリの印象を最新のメッセージまで作成できます。思い出を生成するための適切なプロンプトを作成するための特別なケアは、あなたが気にする詳細がキャプチャされるようにするのに役立ちますが、適切な詳細は無視されます。
このノードは新しいメモリを生成しません。これは、マルチコンピューターセットアップでそれらを使用している場合、ワークフローロックを尊重できるようにするためです。現在、思い出を生成する最良の方法は、FullChatsummaryノードです。


