SadTalker
v0.0.2 rc Release Note


TL;DR: 単一のポートレート画像 ?♂️ + 音声 ? = トーキング ヘッドのビデオ ?。
ライセンスが Apache 2.0 に更新され、非営利の制限が削除されました。
SadTalker は Discord に正式に統合され、ファイルを送信することで無料で使用できるようになりました。テキスト プロンプトから高品質のビデオを生成することもできます。参加する:
私たちは、stable-diffusion-webui 拡張機能を公開しました。詳細については、こちらをご覧ください。デモビデオ
フルイメージモードが利用可能になりました!さらに詳しく...
| v0.0.1 のスチル+エンハンサー | v0.0.2 の静止画 + エンハンサー | 入力画像 @bagbag1815 |
|---|---|---|
Still_e_n.mp4 | full_body_2.バス_中国語_強化.mp4 |  |
いくつかの新しいモード (静止モード、参照モード、サイズ変更モード) が利用できるようになりました。
bilibili、YouTube、X (#sadtalker) でさらに多くのコミュニティ デモが見られることを嬉しく思います。
以前の変更ログはここにあります。
[2023.06.12] : WebUI 拡張機能にさらに新機能が追加されました。ここでのディスカッションを参照してください。
[2023.06.05] : 新しい512x512px(ベータ)フェイスモデルを公開しました。いくつかのバグを修正し、パフォーマンスを向上させました。
[2023.04.15] : @camenduru による WebUI Colab ノートブックを追加しました:
[2023.04.12] : より詳細な WebUI インストールドキュメントを追加し、再インストール時の問題を修正しました。
[2023.04.12] : サードパーティパッケージによる WebUI の安全性の問題を修正し、 sd-webui-extensionの出力パスを最適化しました。
[2023.04.08] : v0.0.2 では、悪用を防ぐために、生成されたビデオにロゴのウォーターマークを追加しました。この透かしは、後のリリースでは削除されました。
[2023.04.08] : v0.0.2では、フル画像アニメーションの機能と、Baiduからチェックポイントをダウンロードするためのリンクを追加しました。エンハンサーロジックも最適化しました。
私たちは第 280 号の新しいアップデートを追跡しています。
問題がある場合は、問題を解決する前によくある質問をお読みください。
コミュニティ チュートリアル: 中文Windows教程 (中国語 Windows チュートリアル) | 日本語コース(日本語チュートリアル)。
Anaconda、Python、 gitインストールします。
環境を作成し、要件をインストールします。
git clone https://github.com/OpenTalker/SadTalker.git
cd SadTalker
conda create -n sadtalker python=3.8
conda activate sadtalker
pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu113
conda install ffmpeg
pip install -r requirements.txt
# ## Coqui TTS is optional for gradio demo.
# ## pip install TTS
中国語のビデオチュートリアルはここから入手できます。次の手順に従うこともできます。
scoop install git 。scoop install ffmpeg使用して、 ffmpegをインストールします。git clone https://github.com/Winfredy/SadTalker.git実行して、SadTalker リポジトリをダウンロードします。start.bat実行すると、Gradio を利用した WebUI デモが開始されます。macOS への SadTalker のインストールに関するチュートリアルは、ここにあります。
ここで追加のチュートリアルを確認してください。
Linux/macOS で次のスクリプトを実行すると、すべてのモデルを自動的にダウンロードできます。
bash scripts/download_models.shオフライン パッチ ( gfpgan/ ) も提供しているため、生成時にモデルはダウンロードされません。
sadt )sadt )モデルは次のように説明します。
| モデル | 説明 |
|---|---|
| チェックポイント/mapping_00229-model.pth.tar | Sadtalker で事前トレーニングされた MappingNet。 |
| チェックポイント/mapping_00109-model.pth.tar | Sadtalker で事前トレーニングされた MappingNet。 |
| チェックポイント/SadTalker_V0.0.2_256.safetensors | 古いバージョンのパッケージ化されたsadtalkerチェックポイント、256面レンダリング)。 |
| チェックポイント/SadTalker_V0.0.2_512.safetensors | 古いバージョンのパッケージ化されたsadtalkerチェックポイント、512面レンダリング)。 |
| gfpgan/重み | facexlibとgfpganで使用される顔検出と拡張モデル。 |
| モデル | 説明 |
|---|---|
| チェックポイント/auido2exp_00300-model.pth | Sadtalker で事前トレーニングされた ExpNet。 |
| チェックポイント/auido2pose_00140-model.pth | Sadtalker で事前にトレーニングされた PoseVAE。 |
| チェックポイント/mapping_00229-model.pth.tar | Sadtalker で事前トレーニングされた MappingNet。 |
| チェックポイント/mapping_00109-model.pth.tar | Sadtalker で事前トレーニングされた MappingNet。 |
| チェックポイント/facevid2vid_00189-model.pth.tar | face-vid2vid の再登場からの事前トレーニング済みの face-vid2vid モデル。 |
| チェックポイント/epoch_20.pth | Deep3DFaceReconstruction で事前トレーニングされた 3DMM エクストラクター。 |
| チェックポイント/wav2lip.pth | Wav2lipの高精度リップシンクモデル。 |
| チェックポイント/shape_predictor_68_face_landmarks.dat | dilbで使用される顔のランドマークモデル。 |
| チェックポイント/BFM | 3DMMライブラリファイル。 |
| チェックポイント/ハブ | 顔の位置合わせに使用される顔検出モデル。 |
| gfpgan/重み | facexlibとgfpganで使用される顔検出と拡張モデル。 |
最終的なフォルダーは次のように表示されます。
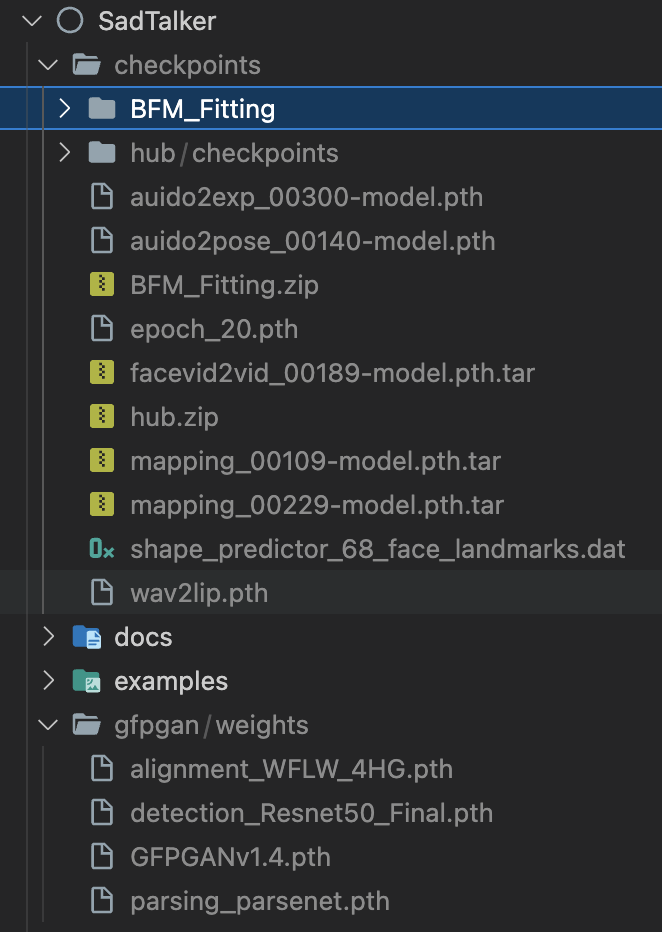
ベスト プラクティスと構成のヒントに関するドキュメントをお読みください。
オンラインデモ:HuggingFace | SDWebUI-Colab |コラボ
ローカル WebUI 拡張機能: WebUI ドキュメントを参照してください。
ローカル gradio デモ (推奨) : Hugging Face デモと同様の Gradio インスタンスをローカルで実行できます。
# # you need manually install TTS(https://github.com/coqui-ai/TTS) via `pip install tts` in advanced.
python app_sadtalker.pyもっと簡単に開始することもできます。
webui.batをダブルクリックするだけで、要件が自動的にインストールされます。bash webui.shを実行して webui を起動します。python inference.py --driven_audio < audio.wav >
--source_image < video.mp4 or picture.png >
--enhancer gfpgan 結果はresults/$SOME_TIMESTAMP/*.mp4に保存されます。
--still使用して自然な全身ビデオを生成します。 enhancerを追加して、生成されるビデオの品質を向上させることができます。
python inference.py --driven_audio < audio.wav >
--source_image < video.mp4 or picture.png >
--result_dir < a file to store results >
--still
--preprocess full
--enhancer gfpgan その他の例、構成、ヒントについては、>>> ベスト プラクティス ドキュメント <<< を参照してください。
私たちの研究があなたの研究に役立つと思われる場合は、以下を引用することを検討してください。
@article { zhang2022sadtalker ,
title = { SadTalker: Learning Realistic 3D Motion Coefficients for Stylized Audio-Driven Single Image Talking Face Animation } ,
author = { Zhang, Wenxuan and Cun, Xiaodong and Wang, Xuan and Zhang, Yong and Shen, Xi and Guo, Yu and Shan, Ying and Wang, Fei } ,
journal = { arXiv preprint arXiv:2211.12194 } ,
year = { 2022 }
}Facerender コードは、zhanglonghao による face-vid2vid と PIRender の再現から多くを借用しています。素晴らしいコードを共有してくれた作者に感謝します。トレーニング プロセスでは、Deep3DFaceReconstruction と Wav2lip のモデルも使用しました。彼らの素晴らしい仕事に感謝します。
次のサードパーティ ライブラリも使用します。
これはテンセントの公式製品ではありません。
1. Please carefully read and comply with the open-source license applicable to this code before using it.
2. Please carefully read and comply with the intellectual property declaration applicable to this code before using it.
3. This open-source code runs completely offline and does not collect any personal information or other data. If you use this code to provide services to end-users and collect related data, please take necessary compliance measures according to applicable laws and regulations (such as publishing privacy policies, adopting necessary data security strategies, etc.). If the collected data involves personal information, user consent must be obtained (if applicable). Any legal liabilities arising from this are unrelated to Tencent.
4. Without Tencent's written permission, you are not authorized to use the names or logos legally owned by Tencent, such as "Tencent." Otherwise, you may be liable for legal responsibilities.
5. This open-source code does not have the ability to directly provide services to end-users. If you need to use this code for further model training or demos, as part of your product to provide services to end-users, or for similar use, please comply with applicable laws and regulations for your product or service. Any legal liabilities arising from this are unrelated to Tencent.
6. It is prohibited to use this open-source code for activities that harm the legitimate rights and interests of others (including but not limited to fraud, deception, infringement of others' portrait rights, reputation rights, etc.), or other behaviors that violate applicable laws and regulations or go against social ethics and good customs (including providing incorrect or false information, spreading pornographic, terrorist, and violent information, etc.). Otherwise, you may be liable for legal responsibilities.
ロゴ: 色とフォントの提案: ChatGPT、ロゴのフォント: Montserrat Alternates 。
デモ画像と音声の著作権はすべて、コミュニティ ユーザーまたは安定した拡散による世代にあります。取り外して使用したい場合はお気軽にお問い合わせください。


