LLaMA_MPS
1.0.0
Apple Silicon GPU で LLaMA (および Stanford-Alpaca) 推論を実行します。
ご覧のとおり、他の LLM とは異なり、LLaMA にはいかなる形でもバイアスがありません。
1. このリポジトリのクローンを作成します
git clone https://github.com/jankais3r/LLaMA_MPS
2. Python の依存関係をインストールする
cd LLaMA_MPS
pip3 install virtualenv
python3 -m venv env
source env/bin/activate
pip3 install -r requirements.txt
pip3 install -e .3. モデルの重みをダウンロードし、 modelsという名前のフォルダーに置きます(例: LLaMA_MPS/models/7B )。
4. (オプション)モデルの重みを再シャードします (13B/30B/65B)
単一の GPU で推論を実行しているため、より大きなモデルの重みを 1 つのファイルにマージする必要があります。
mv models/13B models/13B_orig
mkdir models/13B
python3 reshard.py 1 models/13B_orig models/13B5. 推論を実行する
python3 chat.py --ckpt_dir models/13B --tokenizer_path models/tokenizer.model --max_batch_size 8 --max_seq_len 256
上記の手順により、生の LLaMA モデルに対して「オートコンプリート」モードで推論を実行できるようになります。
Stanford Alpaca の微調整された重みを使用して、ChatGPT に似た「命令応答」モードを試したい場合は、次の手順でセットアップを続けます。
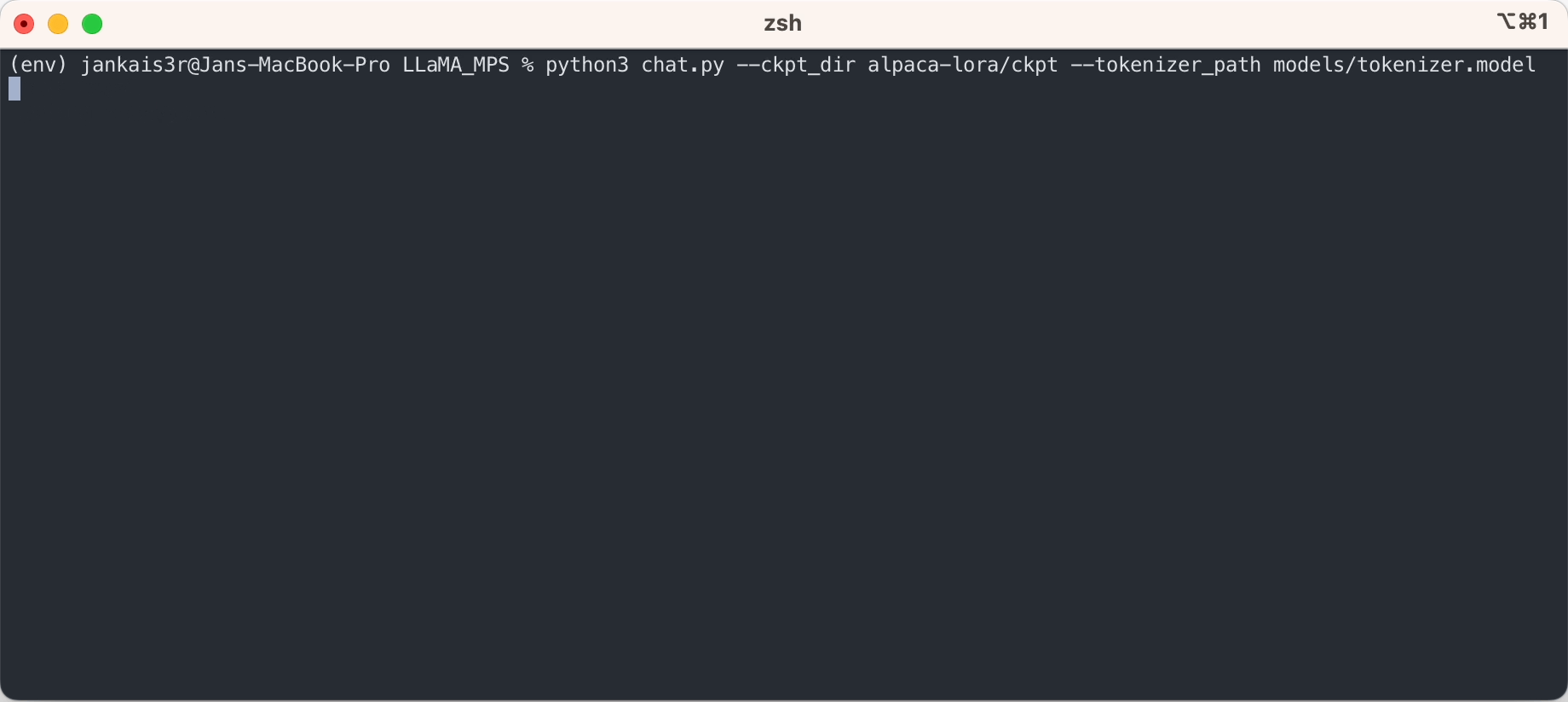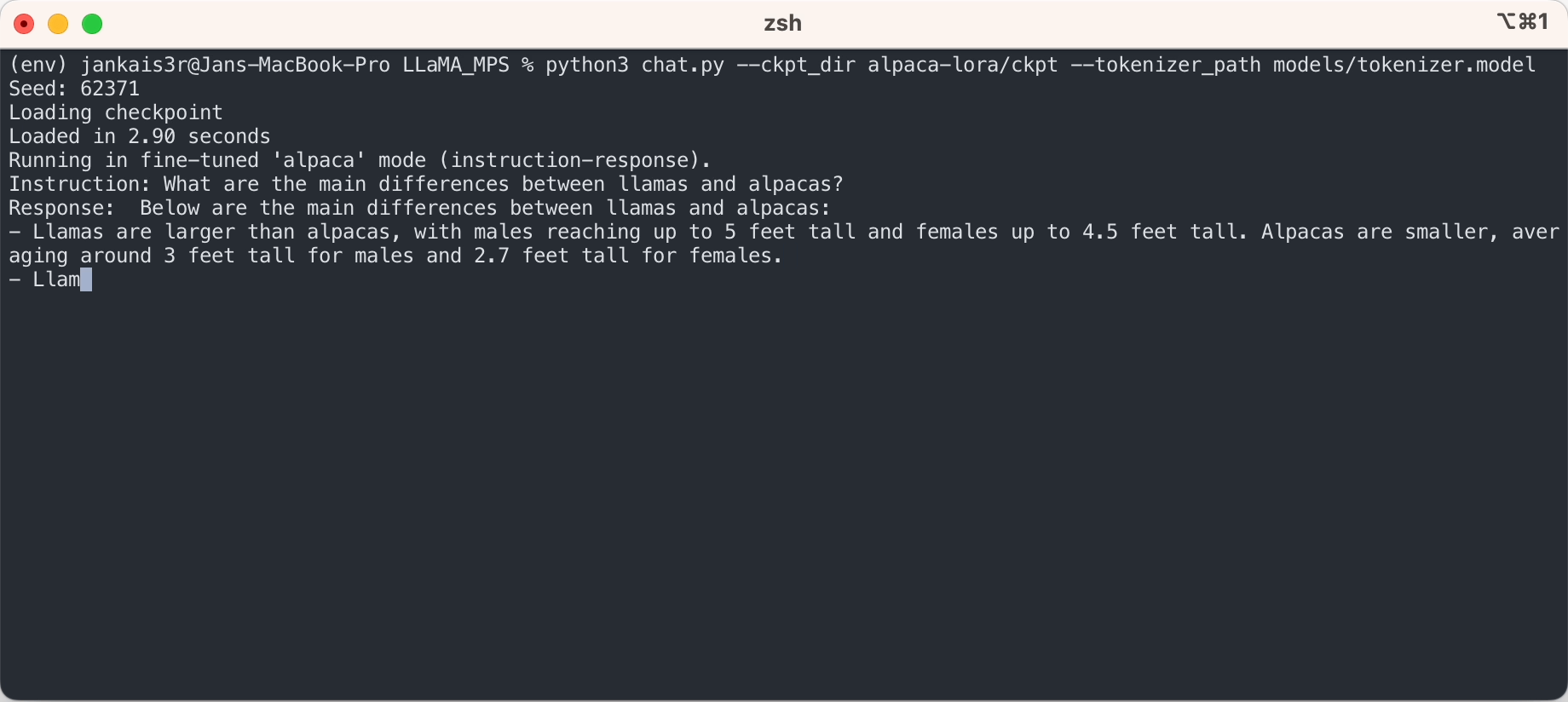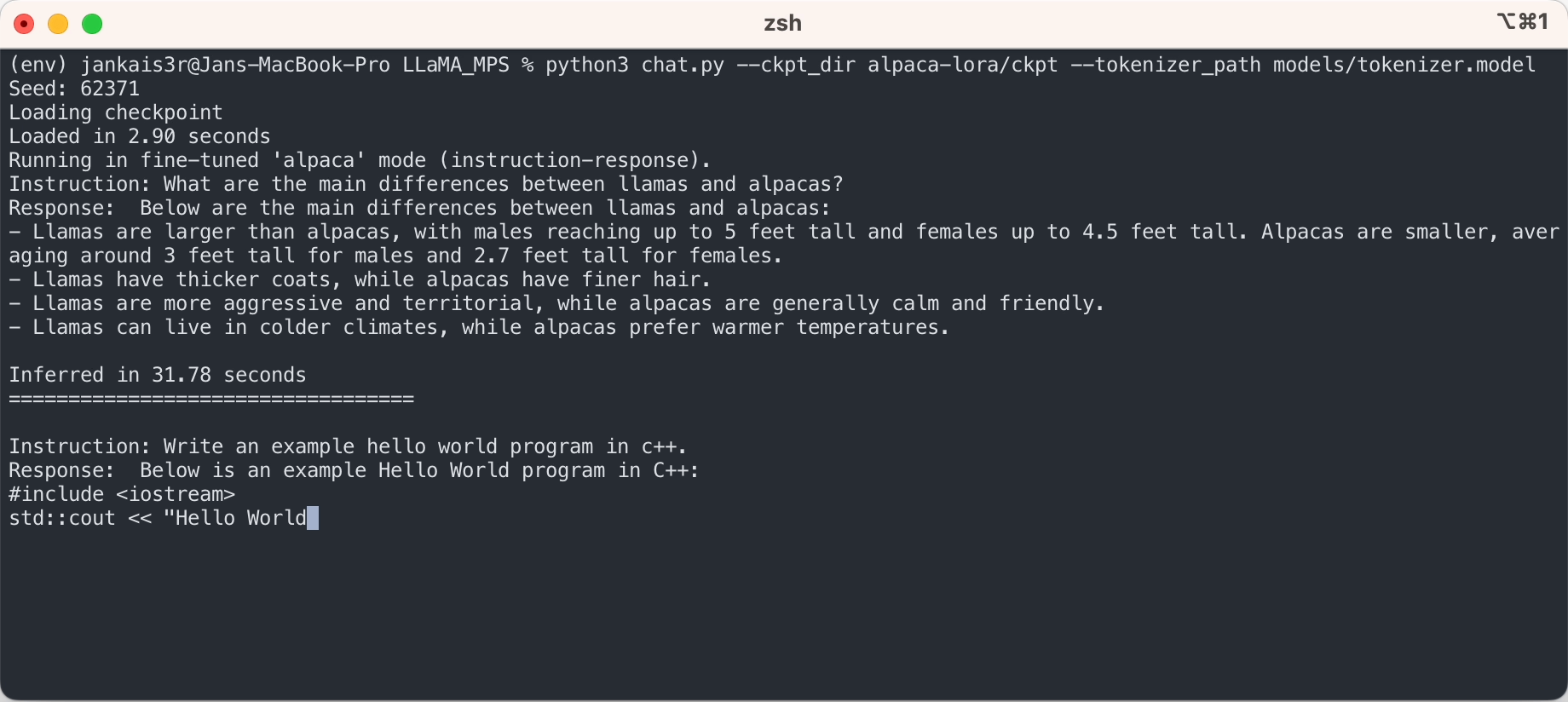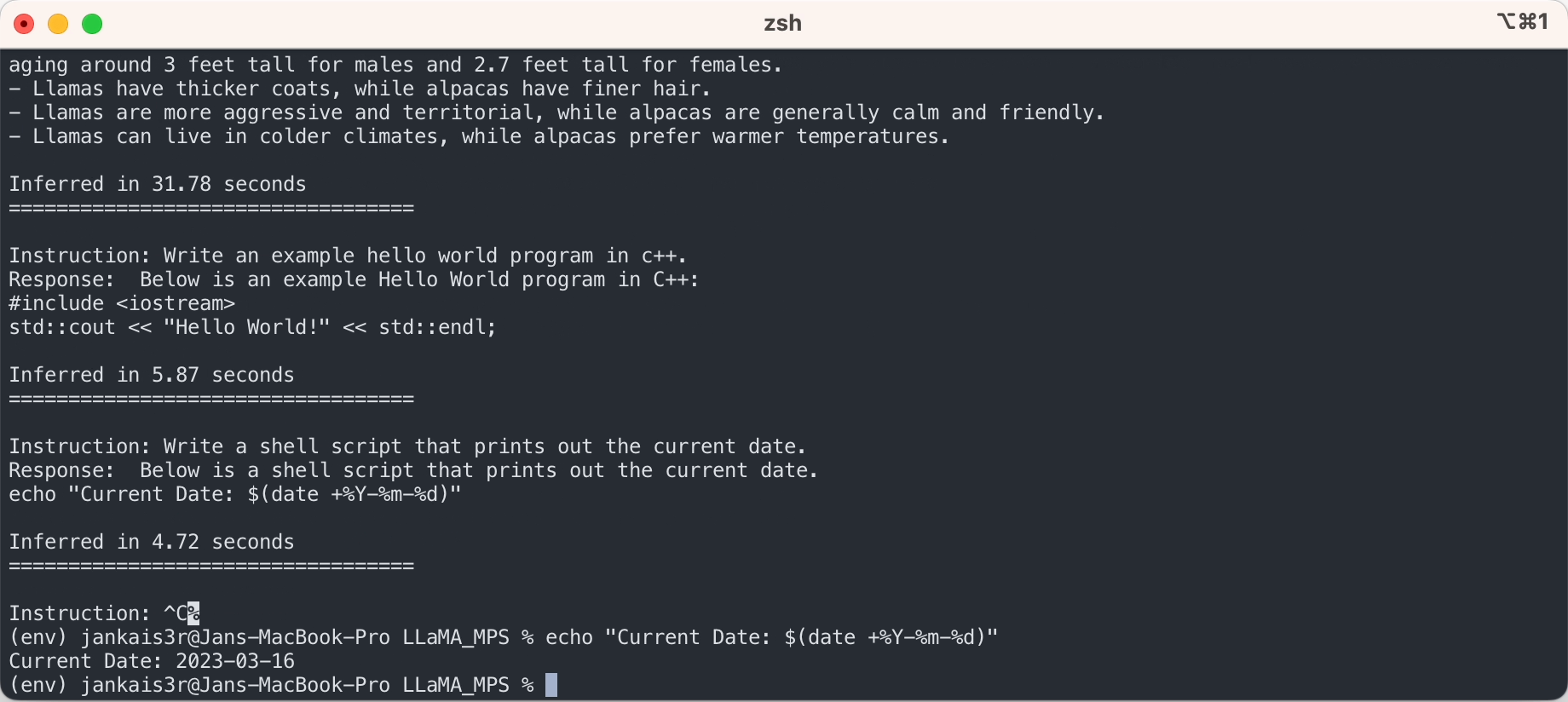
3. 微調整されたウェイトをダウンロードします (7B/13B で利用可能)
python3 export_state_dict_checkpoint.py 7B
python3 clean_hf_cache.py4. 推論を実行する
python3 chat.py --ckpt_dir models/7B-alpaca --tokenizer_path models/tokenizer.model --max_batch_size 8 --max_seq_len 256
| モデル | 推論中の記憶の開始 | チェックポイント変換中のピークメモリ | リシャーディング中のピークメモリ |
|---|---|---|---|
| 7B | 16ギガバイト | 14GB | 該当なし |
| 13B | 32GB | 37GB | 45GB |
| 30B | 66GB | 76GB | 125GB |
| 65B | ?? GB | ?? GB | ?? GB |
モデルごとの最小スペック (スワップにより遅い):
モデルごとの推奨スペック:
- 最大バッチサイズ
メモリに余裕がある場合 (たとえば、64 GB Mac で 13B モデルを実行している場合)、 --max_batch_size=32引数を使用してバッチ サイズを増やすことができます。デフォルト値は1です。
- max_seq_len
生成されるテキストの最大長を増減するには、 --max_seq_len=256引数を使用します。デフォルト値は512です。
- use_repetition_penalty
サンプル スクリプトでは、反復的なコンテンツを生成するモデルにペナルティを与えます。これにより、出力の品質が向上しますが、推論がわずかに遅くなります。 --use_repetition_penalty=False引数を指定してスクリプトを実行し、ペナルティ アルゴリズムを無効にします。
Apple Silicon ユーザーにとって、LLaMA_MPS に代わる最良の選択肢は llama.cpp です。これは、純粋に SoC の CPU 部分で推論を実行する C/C++ 再実装です。コンパイルされた C コードは Python よりもはるかに高速であるため、速度では実際にこの MPS 実装を上回る可能性がありますが、電力効率と熱効率が大幅に悪化します。
どちらの実装がユースケースに適しているかを判断する場合は、以下の比較を参照してください。
| 実装 | 合計実行時間 - 256 トークン | トークン/秒 | ピーク時のメモリ使用量 | SoC のピーク温度 | SoC のピーク消費電力 | 1Whあたりのトークン数 |
|---|---|---|---|---|---|---|
| LLAMA_MPS (13B fp16) | 75秒 | 3.41 | 30GB | 79℃ | 10W | 1,228.80 |
| ラマ.cpp (13B fp16) | 70年代 | 3.66 | 25GB | 106℃ | 35W | 376.16 |


