system design primer
1.0.0
English ∙ 日本語 ∙ 简体中文 ∙ 繁體中文 | العَرَبِيَّة ∙ বাংলা ∙ Português do Brasil ∙ Deutsch ∙ ελληνικά ∙ עברית ∙ Italiano ∙ 한국어 ∙ فارسی ∙ Polski ∙ русский язык ∙ Español ∙ ภาษาไทย ∙ Türkçe ∙ tiếng Việt ∙ Français |翻訳を追加
このガイドの翻訳にご協力ください。
大規模なシステムを設計する方法を学びます。
システム設計面接の準備をします。
スケーラブルなシステムを設計する方法を学ぶことは、より優れたエンジニアになるのに役立ちます。
システム設計は幅広いテーマです。システム設計原則に関する膨大な量のリソースが Web 上に散在しています。
このリポジトリは、大規模なシステムを構築する方法を学ぶのに役立つリソースを整理したコレクションです。
これは継続的に更新されるオープンソース プロジェクトです。
貢献は大歓迎です!
多くのテクノロジー企業では、コーディング面接に加えて、システム設計も技術面接プロセスの必須要素となっています。
一般的なシステム設計面接の質問を練習し、その結果をサンプルソリューション(ディスカッション、コード、図) と比較します。
面接準備のための追加トピック:
提供されている Anki フラッシュカード デッキでは、重要なシステム設計コンセプトを保持するために間隔をあけて繰り返しを使用しています。
外出先での使用に最適です。
コーディング面接の準備に役立つリソースをお探しですか?
追加の Anki デッキが含まれている姉妹リポジトリInteractivecoding Challengesをチェックしてください。
コミュニティから学びましょう。
以下を支援するために、お気軽にプル リクエストを送信してください。
磨きが必要なコンテンツは開発中となります。
貢献ガイドラインを確認してください。
長所と短所を含む、さまざまなシステム設計トピックの概要。すべてはトレードオフです。
各セクションには、より詳細なリソースへのリンクが含まれています。
面接のタイムライン (短期、中期、長期) に基づいて検討する推奨トピック。
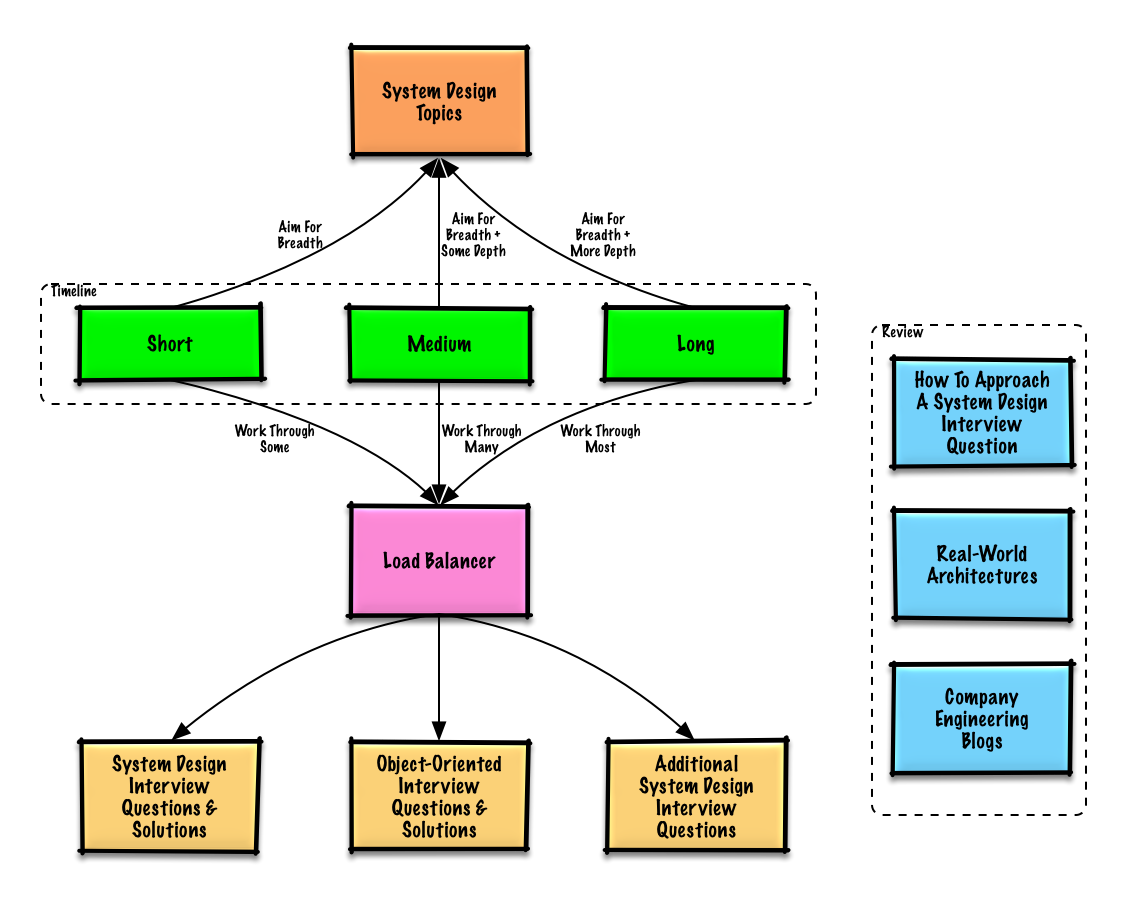
Q: 面接では、ここですべてを知る必要がありますか?
A: いいえ、面接の準備のためにここですべてを知る必要はありません。
面接で何を聞かれるかは、次のような変数によって異なります。
一般に、経験豊富な候補者は、システム設計についてより詳しいことが期待されます。アーキテクトやチームのリーダーは、個々の貢献者よりも多くのことを知っていることが期待される場合があります。トップクラスのテクノロジー企業では、1 回以上の設計面接が行われる可能性があります。
まずは広範囲から始めて、いくつかの領域を深く掘り下げていきます。さまざまな主要なシステム設計トピックについて少し知っておくと役立ちます。あなたのタイムライン、経験、面接するポジション、面接する企業に基づいて、次のガイドを調整してください。
| 短い | 中くらい | 長さ | |
|---|---|---|---|
| システム設計のトピックを読んで、システムがどのように動作するかを幅広く理解します。 | ? | ? | ? |
| 面接を受ける企業のエンジニアリング ブログにある記事をいくつか読んでください。 | ? | ? | ? |
| いくつかの現実世界のアーキテクチャを読んでください。 | ? | ? | ? |
| システム設計面接の質問へのアプローチ方法を確認する | ? | ? | ? |
| システム設計面接の質問と解決策に取り組む | いくつかの | 多くの | ほとんど |
| オブジェクト指向設計の面接での質問と解決策を解決する | いくつかの | 多くの | ほとんど |
| システム設計面接の追加質問を確認する | いくつかの | 多くの | ほとんど |
システム設計面接の質問に取り組む方法。
システム設計の面接は自由形式の会話です。あなたにはそれを主導することが期待されています。
次の手順を使用して、ディスカッションを進めることができます。このプロセスを確実にするために、次の手順を使用して、「システム設計インタビューの質問と解決策」セクションに取り組んでください。
要件を収集し、問題の範囲を特定します。質問してユースケースと制約を明確にします。仮定について話し合う。
すべての重要なコンポーネントを含む高レベルの設計の概要を説明します。
各コアコンポーネントの詳細を調べます。たとえば、URL 短縮サービスの設計を依頼された場合は、次のことについて話し合います。
制約を考慮して、ボトルネックを特定して対処します。たとえば、スケーラビリティの問題に対処するには次のことが必要ですか?
考えられる解決策とトレードオフについて話し合います。すべてはトレードオフです。スケーラブルなシステム設計の原則を使用してボトルネックに対処します。
手動で見積もりを行うよう求められる場合があります。次のリソースについては、付録を参照してください。
何が予想されるかをよりよく理解するには、次のリンクをチェックしてください。
システム設計面接の一般的な質問とサンプルディスカッション、コード、図。
ソリューションは、
solutions/フォルダー内のコンテンツにリンクされています。
| 質問 | |
|---|---|
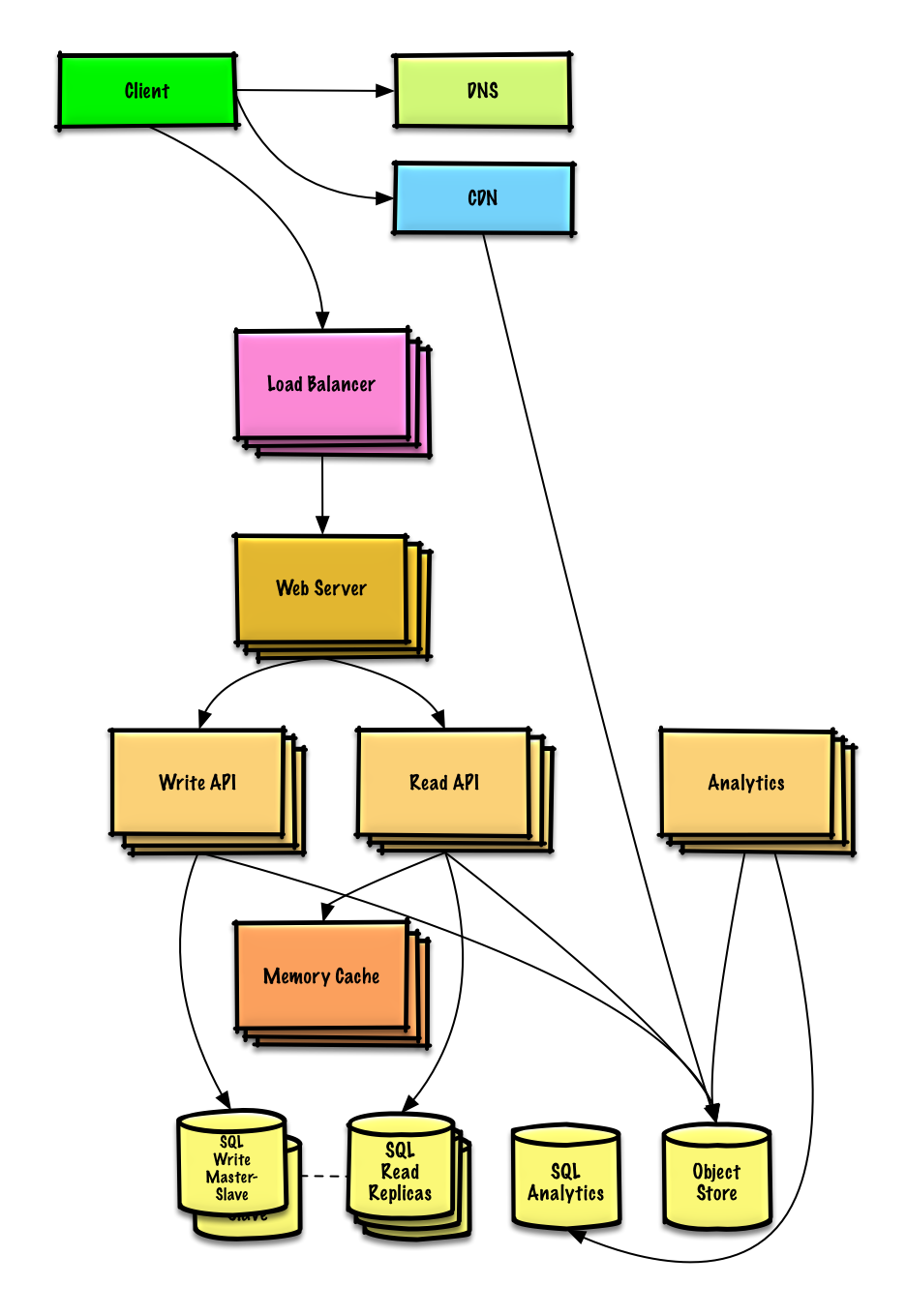
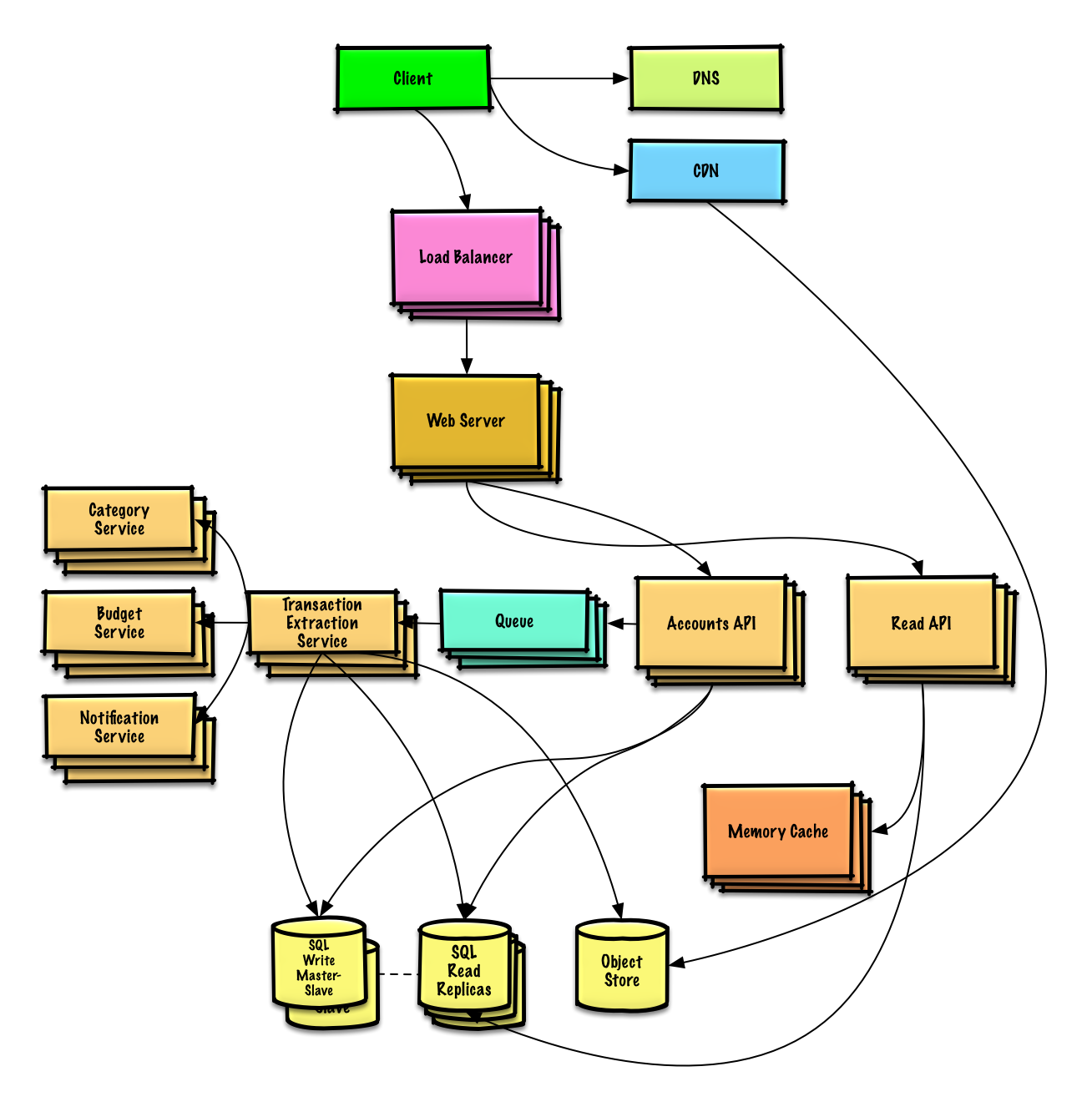
| デザイン Pastebin.com (または Bit.ly) | 解決 |
| Twitter のタイムラインと検索 (または Facebook のフィードと検索) をデザインする | 解決 |
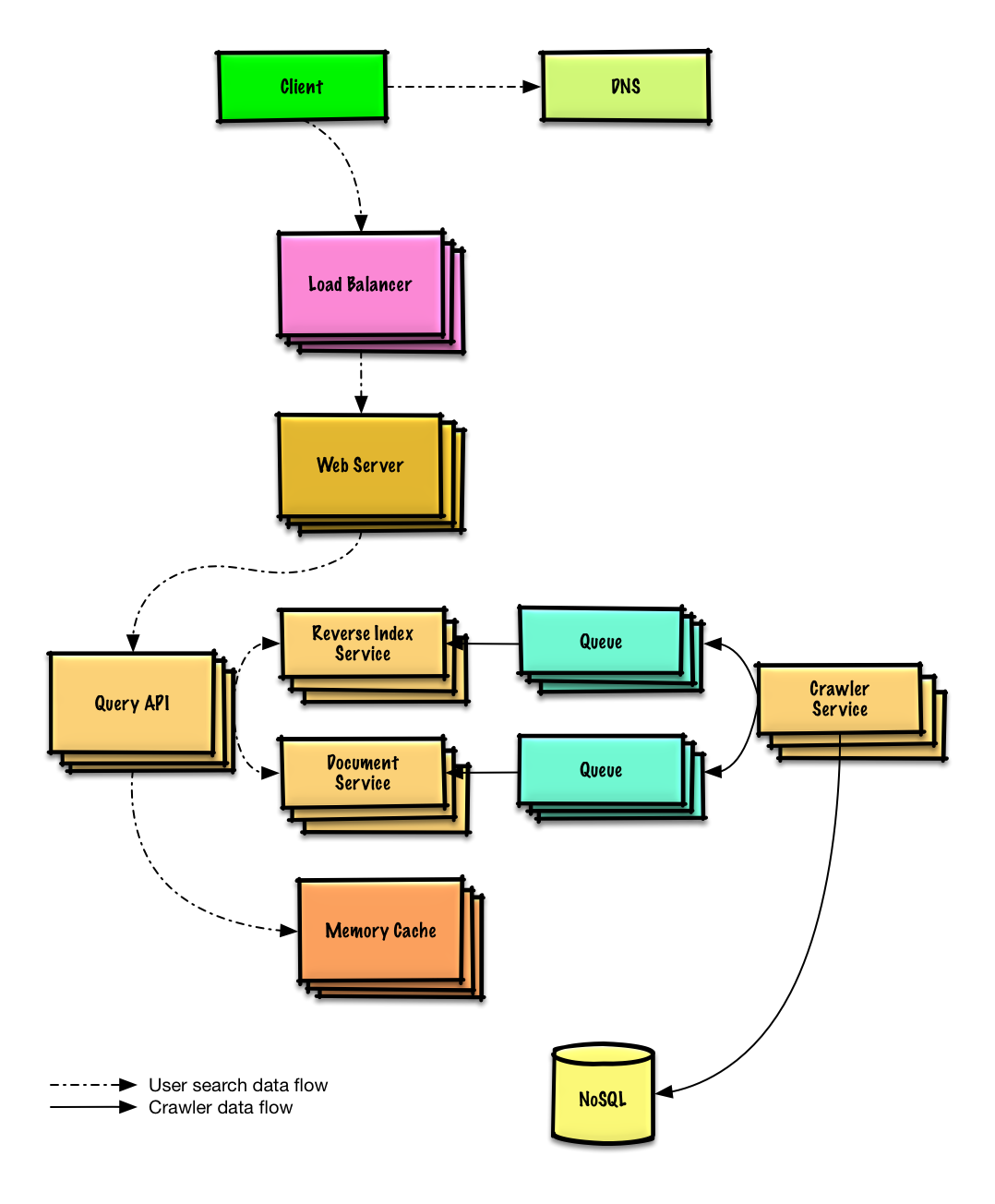
| Web クローラーを設計する | 解決 |
| デザインミント.com | 解決 |
| ソーシャル ネットワークのデータ構造を設計する | 解決 |
| 検索エンジン用の Key-Value ストアを設計する | 解決 |
| Amazonのカテゴリ別売上ランキング機能をデザインする | 解決 |
| AWS で数百万のユーザーに拡張できるシステムを設計する | 解決 |
| システム設計の質問を追加する | 貢献する |
演習と解決策を表示する
演習と解決策を表示する
演習と解決策を表示する
演習と解決策を表示する
演習と解決策を表示する
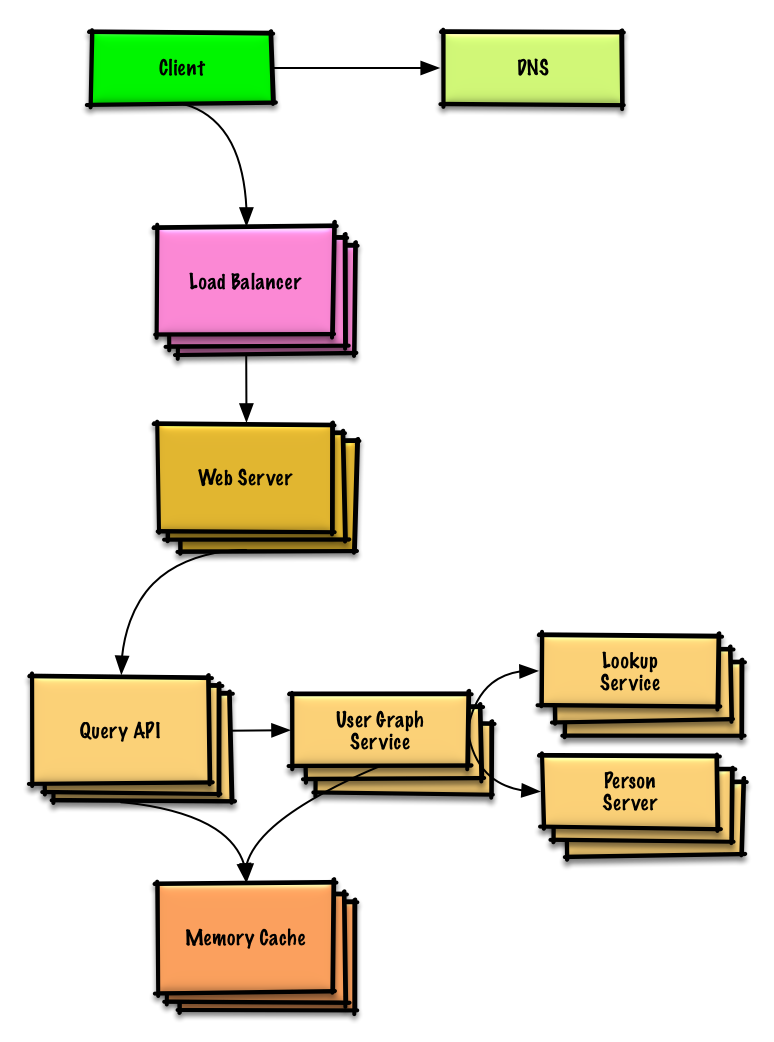
演習と解決策を表示する
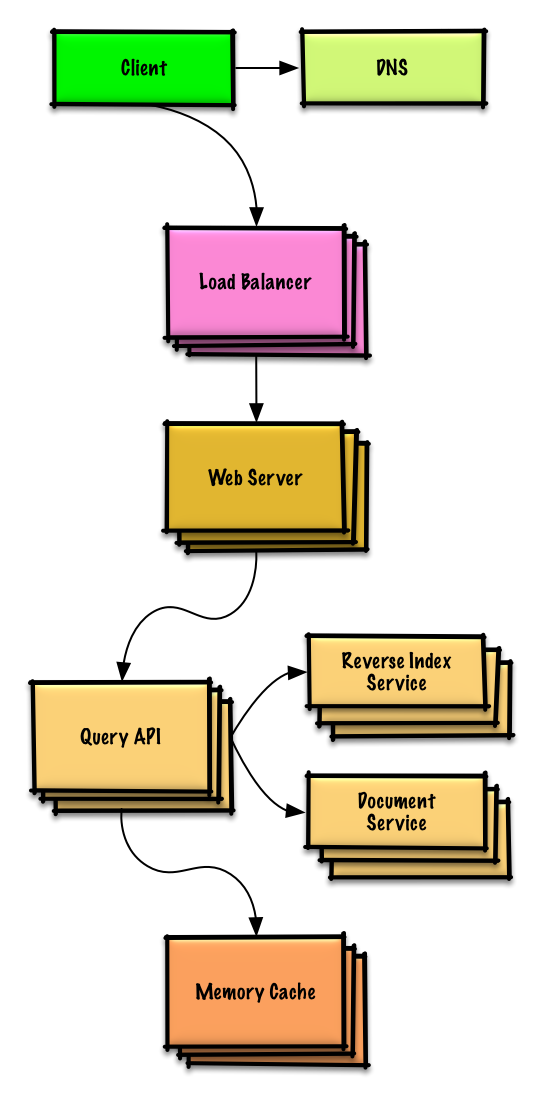
演習と解決策を表示する
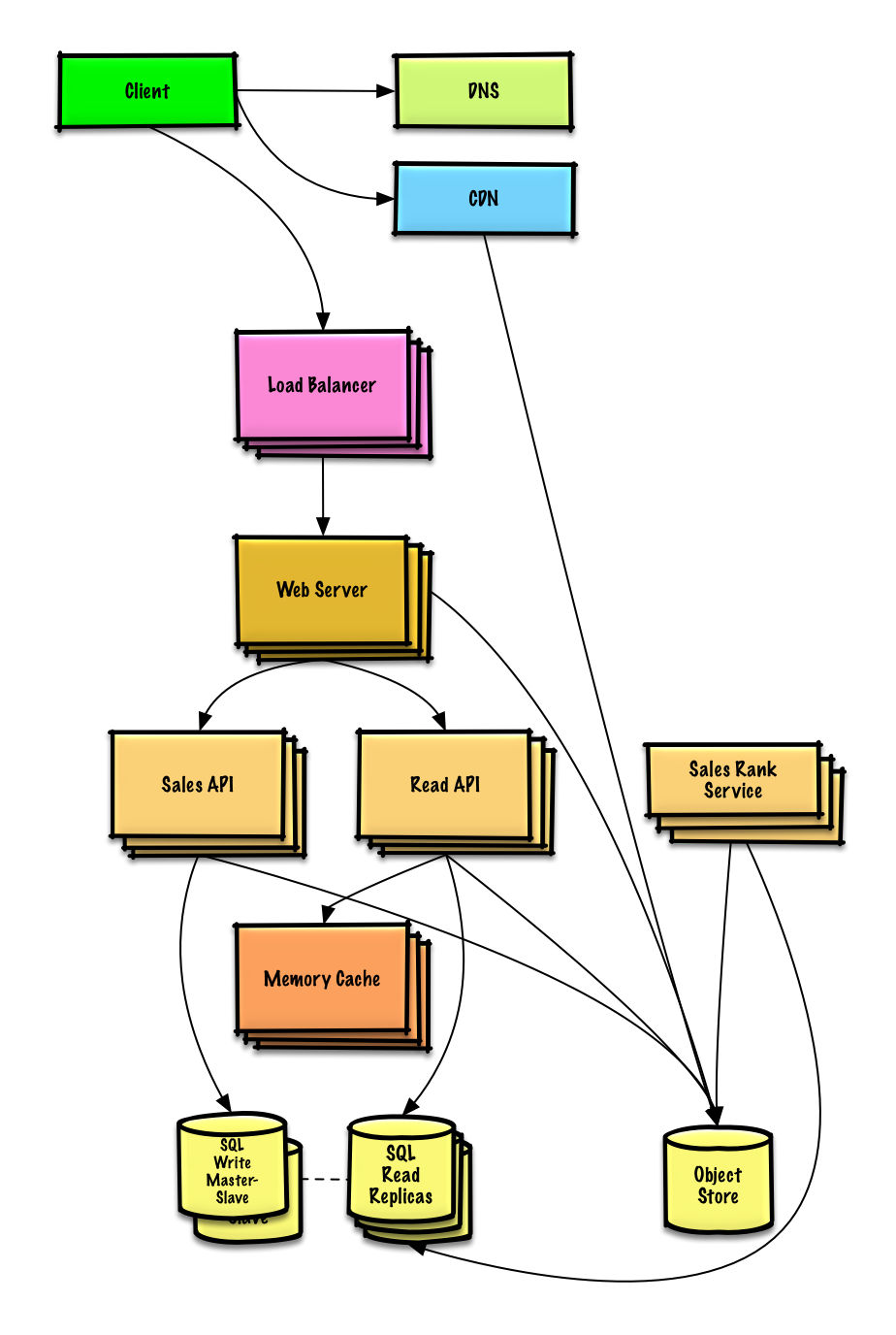
演習と解決策を表示する
オブジェクト指向設計に関する一般的な面接の質問と、サンプルのディスカッション、コード、図。
ソリューションは、
solutions/フォルダー内のコンテンツにリンクされています。
注: このセクションは開発中です
| 質問 | |
|---|---|
| ハッシュマップを設計する | 解決 |
| 最も最近使用されていないキャッシュを設計する | 解決 |
| コールセンターを設計する | 解決 |
| トランプのデッキをデザインする | 解決 |
| 駐車場の設計をする | 解決 |
| チャットサーバーを設計する | 解決 |
| 円形配列を設計する | 貢献する |
| オブジェクト指向設計の質問を追加する | 貢献する |
システム設計は初めてですか?
まず、共通原則の基本を理解し、それらが何であるか、それらがどのように使用されるか、およびその長所と短所について学ぶ必要があります。
ハーバード大学でのスケーラビリティ講義
スケーラビリティ
次に、大まかなトレードオフについて見ていきます。
すべてはトレードオフであることに留意してください。
次に、DNS、CDN、ロード バランサーなどのより具体的なトピックについて詳しく説明します。
追加されたリソースに比例してパフォーマンスが向上する場合、サービスはスケーラブルです。一般に、パフォーマンスの向上とは、より多くの作業単位を処理することを意味しますが、データセットが増大した場合など、より大きな作業単位を処理できるようになることもあります。 1
パフォーマンスとスケーラビリティを比較する別の方法:
レイテンシは、何らかのアクションを実行するか、何らかの結果を生み出すまでの時間です。
スループットは、単位時間あたりのそのようなアクションまたは結果の数です。
一般に、許容可能な遅延で最大のスループットを目指す必要があります。
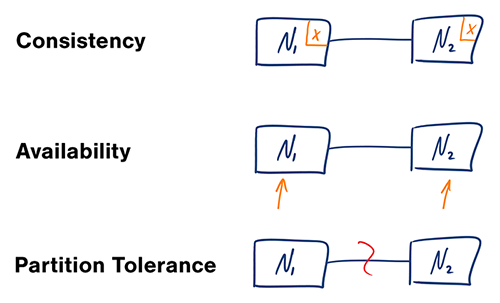
出典: CAP 定理の再検討
分散コンピュータ システムでは、次の保証のうち 2 つだけをサポートできます。
ネットワークは信頼できないため、パーティショントレランスをサポートする必要があります。ソフトウェアの一貫性と可用性の間でトレードオフを行う必要があります。
パーティション化されたノードからの応答を待機すると、タイムアウト エラーが発生する可能性があります。ビジネス ニーズでアトミックな読み取りと書き込みが必要な場合、CP は良い選択です。
応答は、どのノードでも利用可能なデータの最も容易に利用可能なバージョンを返しますが、最新ではない可能性があります。パーティションが解決されると、書き込みが伝播するまでに時間がかかる場合があります。
AP は、ビジネスで最終的な整合性を確保する必要がある場合、または外部エラーにもかかわらずシステムが動作し続ける必要がある場合に適しています。
同じデータのコピーが複数ある場合、クライアントがデータの一貫したビューを得るためにそれらを同期する方法についての選択肢に直面します。 CAP 定理からの一貫性の定義を思い出してください。すべての読み取りは最新の書き込みまたはエラーを受け取ります。
書き込み後の読み取りでは、それが認識される場合と認識されない場合があります。ベストエフォート型のアプローチが採用されます。
このアプローチは、memcached などのシステムで見られます。弱い整合性は、VoIP、ビデオ チャット、リアルタイム マルチプレイヤー ゲームなどのリアルタイムのユースケースでうまく機能します。たとえば、電話中に数秒間受信できなくなった場合、接続を回復すると、接続切断中に話されていた内容が聞こえなくなります。
書き込み後、最終的に読み取りでそれが認識されます (通常はミリ秒以内)。データは非同期的にレプリケートされます。
このアプローチは、DNS や電子メールなどのシステムで見られます。最終的な整合性は、高可用性システムでうまく機能します。
書き込み後、読み取りでそれが表示されます。データは同期的にレプリケートされます。
このアプローチは、ファイル システムや RDBMS で見られます。強い整合性は、トランザクションを必要とするシステムでうまく機能します。
高可用性をサポートするには、フェイルオーバーとレプリケーションという 2 つの補完的なパターンがあります。
アクティブ/パッシブ フェイルオーバーでは、アクティブ サーバーとスタンバイのパッシブ サーバーの間でハートビートが送信されます。ハートビートが中断されると、パッシブ サーバーがアクティブ サーバーの IP アドレスを引き継ぎ、サービスを再開します。
ダウンタイムの長さは、パッシブ サーバーがすでに「ホット」スタンバイで実行されているかどうか、または「コールド」スタンバイから起動する必要があるかどうかによって決まります。アクティブなサーバーのみがトラフィックを処理します。
アクティブ/パッシブ フェイルオーバーは、マスター/スレーブ フェイルオーバーとも呼ばれます。
アクティブ/アクティブでは、両方のサーバーがトラフィックを管理し、サーバー間で負荷を分散します。
サーバーが公開されている場合、DNS は両方のサーバーのパブリック IP について知る必要があります。サーバーが内部に面している場合、アプリケーション ロジックは両方のサーバーについて認識する必要があります。
アクティブ/アクティブ フェイルオーバーは、マスター/マスター フェイルオーバーとも呼ばれます。
このトピックについては、「データベース」セクションでさらに詳しく説明します。
可用性は、多くの場合、サービスが利用可能な時間の割合としてのアップタイム (またはダウンタイム) によって定量化されます。可用性は通常、9 の数で測定されます。99.99% の可用性を持つサービスは、9 が 4 つあると表現されます。
| 間隔 | 許容可能なダウンタイム |
|---|---|
| 年間のダウンタイム | 8時間45分57秒 |
| 月あたりのダウンタイム | 43分49.7秒 |
| 週あたりのダウンタイム | 10分4.8秒 |
| 1 日あたりのダウンタイム | 1分26.4秒 |
| 間隔 | 許容可能なダウンタイム |
|---|---|
| 年間のダウンタイム | 52分35.7秒 |
| 月あたりのダウンタイム | 4分23秒 |
| 週あたりのダウンタイム | 1分5秒 |
| 1 日あたりのダウンタイム | 8.6秒 |
サービスが障害を起こしやすい複数のコンポーネントで構成されている場合、サービス全体の可用性は、コンポーネントが順番に配置されているか並列に配置されているかによって異なります。
可用性が 100% 未満の 2 つのコンポーネントが連続している場合、全体の可用性は低下します。
Availability (Total) = Availability (Foo) * Availability (Bar)
FooとBar両方の可用性がそれぞれ 99.9% である場合、シーケンスの合計可用性は 99.8% になります。
可用性が 100% 未満の 2 つのコンポーネントが並列されると、全体の可用性が向上します。
Availability (Total) = 1 - (1 - Availability (Foo)) * (1 - Availability (Bar))
FooとBar両方の可用性がそれぞれ 99.9% である場合、並列での合計可用性は 99.9999% になります。
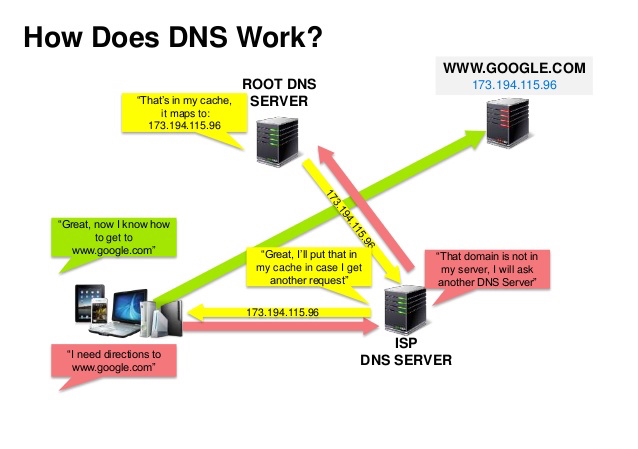
出典: DNS セキュリティのプレゼンテーション
ドメイン ネーム システム (DNS) は、www.example.com などのドメイン名を IP アドレスに変換します。
DNS は階層構造になっており、最上位にいくつかの権限のあるサーバーがあります。ルーターまたは ISP は、検索時にどの DNS サーバーに接続するかに関する情報を提供します。下位レベルの DNS サーバーはマッピングをキャッシュしますが、DNS 伝播の遅延によりマッピングが古くなってしまう可能性があります。 DNS 結果は、存続時間 (TTL) によって決まる一定期間、ブラウザまたは OS によってキャッシュされることもあります。
CNAME (example.com から www.example.com) またはAレコードを指します。CloudFlare や Route 53 などのサービスは、マネージド DNS サービスを提供します。一部の DNS サービスは、さまざまな方法でトラフィックをルーティングできます。
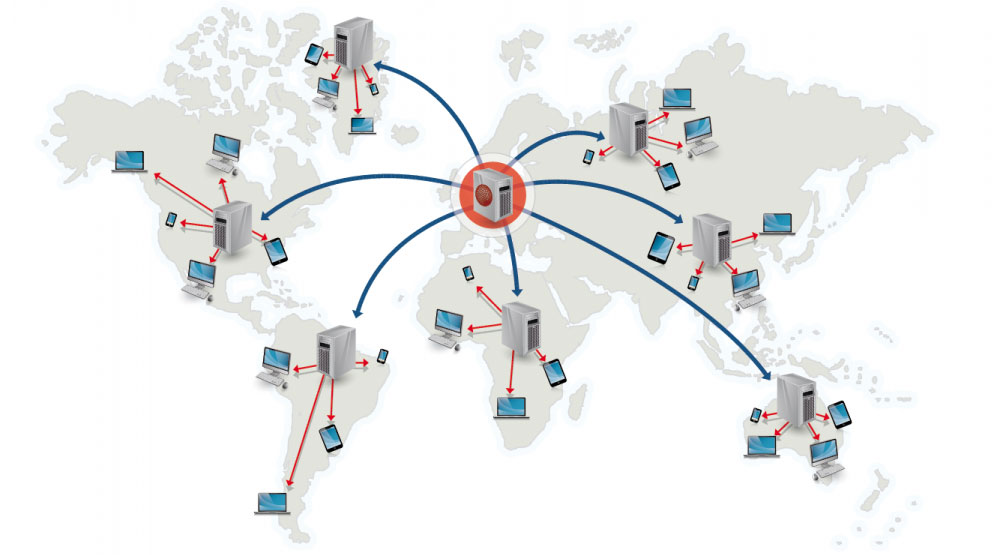
出典: CDN を使用する理由
コンテンツ配信ネットワーク (CDN) は、プロキシ サーバーのグローバルに分散されたネットワークであり、ユーザーに近い場所からコンテンツを提供します。通常、HTML/CSS/JS、写真、ビデオなどの静的ファイルは CDN から提供されますが、Amazon の CloudFront などの一部の CDN は動的コンテンツをサポートしています。サイトの DNS 解決により、クライアントはどのサーバーに接続すればよいかがわかります。
CDN からコンテンツを提供すると、次の 2 つの方法でパフォーマンスが大幅に向上します。
プッシュ CDN は、サーバー上で変更が発生するたびに新しいコンテンツを受信します。コンテンツの提供、CDN への直接アップロード、CDN を指すように URL を書き換えるのは、お客様が全責任を負います。コンテンツの有効期限がいつ切れるか、いつ更新されるかを構成できます。コンテンツは新規または変更された場合にのみアップロードされるため、トラフィックは最小限に抑えられますが、ストレージは最大化されます。
トラフィック量が少ないサイト、またはコンテンツが頻繁に更新されないサイトは、プッシュ CDN で適切に機能します。コンテンツは定期的に再取得されるのではなく、一度 CDN に配置されます。
プル CDN は、最初のユーザーがコンテンツを要求したときに、サーバーから新しいコンテンツを取得します。コンテンツをサーバー上に残し、CDN を指すように URL を書き換えます。これにより、コンテンツが CDN にキャッシュされるまでリクエストが遅くなります。
有効期間 (TTL) によって、コンテンツがキャッシュされる期間が決まります。プル CDN は CDN 上のストレージ容量を最小限に抑えますが、ファイルの有効期限が切れて実際に変更される前にプルされた場合、冗長なトラフィックが作成される可能性があります。
トラフィックがより均等に分散され、最近リクエストされたコンテンツのみが CDN 上に残るため、トラフィックが多いサイトはプル CDN とうまく機能します。
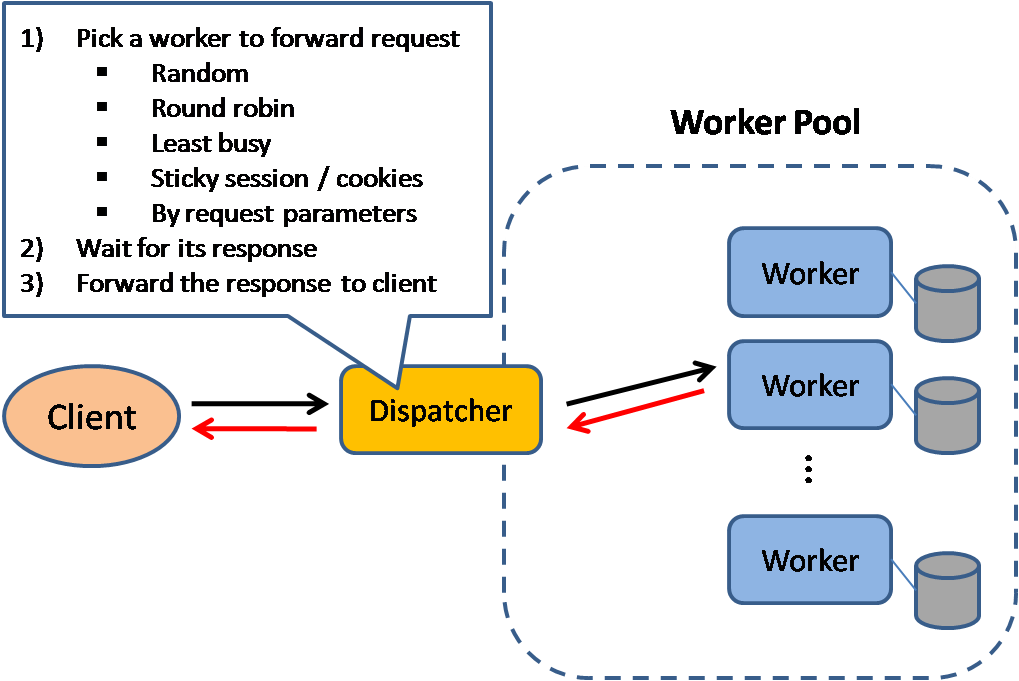
出典: スケーラブルなシステム設計パターン
ロード バランサは、受信したクライアント リクエストをアプリケーション サーバーやデータベースなどのコンピューティング リソースに分散します。いずれの場合も、ロード バランサーはコンピューティング リソースからの応答を適切なクライアントに返します。ロード バランサーは次の場合に効果的です。
ロード バランサーは、ハードウェア (高価) または HAProxy などのソフトウェアを使用して実装できます。
その他の利点は次のとおりです。
障害から保護するために、複数のロード バランサーをアクティブ/パッシブ モードまたはアクティブ/アクティブ モードでセットアップするのが一般的です。
ロード バランサーは、次のようなさまざまなメトリックに基づいてトラフィックをルーティングできます。
レイヤ 4 ロード バランサは、トランスポート層の情報を調べて、リクエストを分散する方法を決定します。一般に、これにはヘッダー内の送信元、宛先 IP アドレス、およびポートが含まれますが、パケットの内容は含まれません。レイヤ 4 ロード バランサは、ネットワーク アドレス変換 (NAT) を実行して、上流のサーバーとの間でネットワーク パケットを転送します。
レイヤ 7 ロード バランサは、アプリケーション レイヤを調べてリクエストを分散する方法を決定します。これには、ヘッダー、メッセージ、Cookie の内容が含まれる場合があります。レイヤ 7 ロード バランサは、ネットワーク トラフィックを終了し、メッセージを読み取り、負荷分散の決定を行って、選択したサーバーへの接続を開きます。たとえば、レイヤー 7 ロード バランサーは、ビデオ トラフィックをビデオをホストするサーバーに送信すると同時に、より機密性の高いユーザーの請求トラフィックをセキュリティが強化されたサーバーに送信することができます。
柔軟性を犠牲にして、レイヤー 4 の負荷分散に必要な時間とコンピューティング リソースはレイヤー 7 よりも少なくなりますが、最新の汎用ハードウェアではパフォーマンスへの影響は最小限に抑えることができます。
ロード バランサーは水平スケーリングにも役立ち、パフォーマンスと可用性が向上します。汎用マシンを使用したスケールアウトは、垂直スケーリングと呼ばれる、より高価なハードウェアで単一サーバーをスケールアップするよりもコスト効率が高く、可用性が高くなります。また、特殊なエンタープライズ システムよりも、汎用ハードウェアに取り組む人材のほうが採用が簡単です。
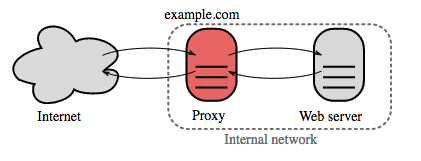
出典: ウィキペディア
リバース プロキシは、内部サービスを一元化し、統一されたインターフェイスを一般公開する Web サーバーです。クライアントからの要求は、リバース プロキシがサーバーの応答をクライアントに返す前に、要求を実行できるサーバーに転送されます。
その他の利点は次のとおりです。
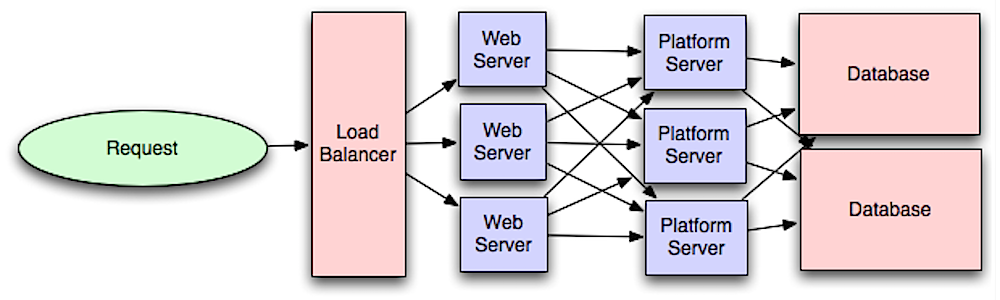
出典: 大規模なシステムの設計の概要
Web 層をアプリケーション層 (プラットフォーム層とも呼ばれる) から分離すると、両方の層を独立して拡張および構成できるようになります。新しい API を追加すると、必ずしも Web サーバーを追加する必要がなく、アプリケーション サーバーが追加されます。単一責任の原則は、連携して機能する小規模で自律的なサービスを推奨します。小規模なサービスを備えた小規模なチームは、急速な成長に向けてより積極的に計画を立てることができます。
アプリケーション層のワーカーも非同期の有効化に役立ちます。
この議論に関連するのはマイクロサービスです。マイクロサービスは、独立して展開可能な小規模なモジュール式サービスのスイートとして説明できます。各サービスは独自のプロセスを実行し、明確に定義された軽量メカニズムを通じて通信して、ビジネス目標を達成します。 1
たとえば、Pinterest には、ユーザー プロフィール、フォロワー、フィード、検索、写真のアップロードなどのマイクロサービスを含めることができます。
Consul、Etcd、Zookeeper などのシステムは、登録された名前、アドレス、ポートを追跡することで、サービスが相互に検索できるようにします。ヘルスチェックはサービスの整合性を検証するのに役立ち、多くの場合、HTTP エンドポイントを使用して実行されます。 Consul と Etcd の両方には、構成値やその他の共有データを保存するのに役立つ組み込みのキーと値のストアがあります。
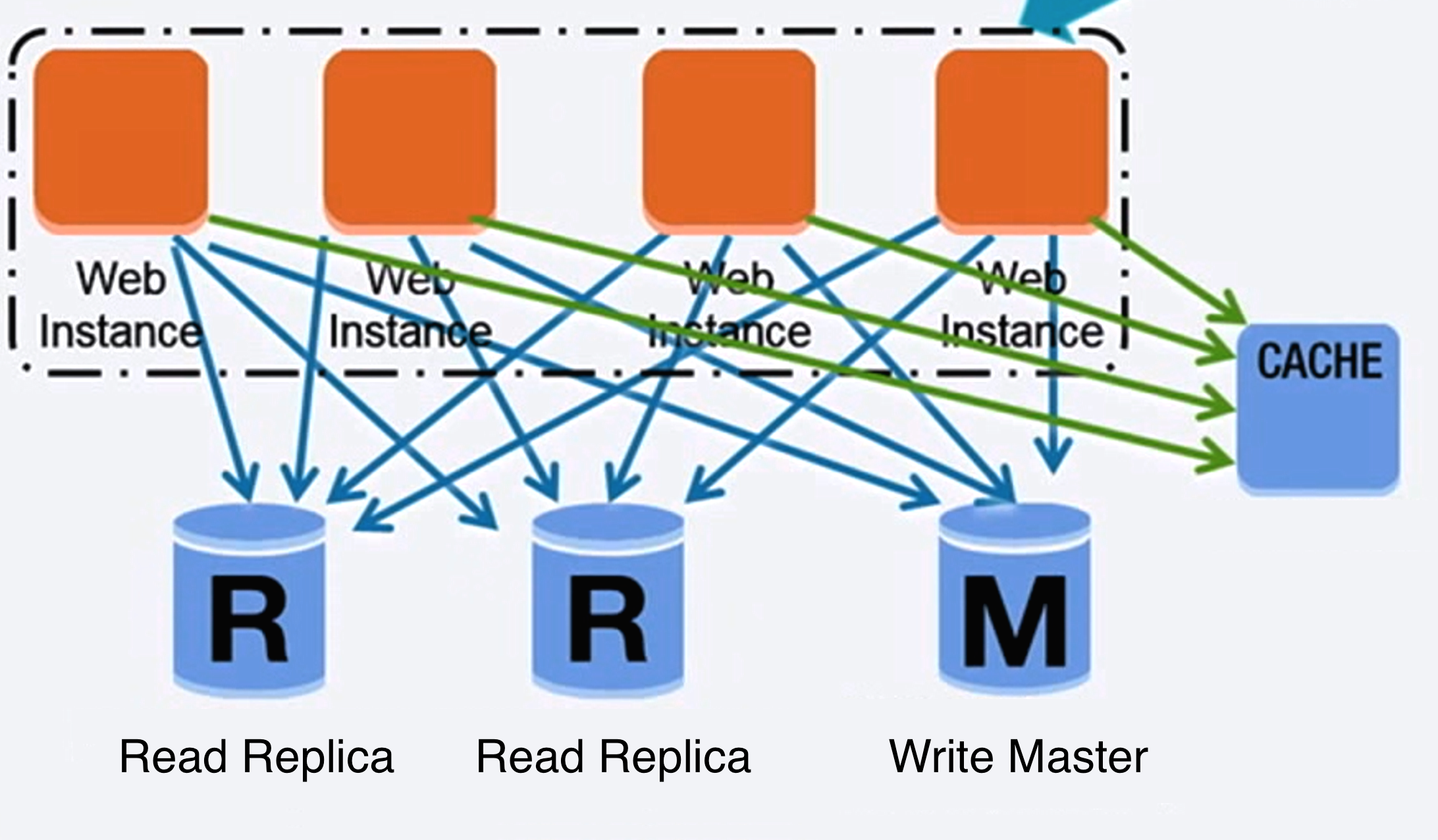
出典: 最初の 1,000 万ユーザーまでのスケールアップ
SQL のようなリレーショナル データベースは、テーブルに編成されたデータ項目のコレクションです。
ACID は、リレーショナル データベース トランザクションのプロパティのセットです。
リレーショナル データベースをスケーリングするには、マスター/スレーブ レプリケーション、マスター/マスター レプリケーション、フェデレーション、シャーディング、非正規化、 SQL チューニングなど、さまざまな手法があります。
マスターは読み取りと書き込みを処理し、読み取りのみを処理する 1 つ以上のスレーブに書き込みを複製します。スレーブは、ツリー状の方法で追加のスレーブに複製することもできます。マスターがオフラインになった場合、システムは、スレーブがマスターに昇格するか、新しいマスターがプロビジョニングされるまで、読み取り専用モードで動作し続けることができます。
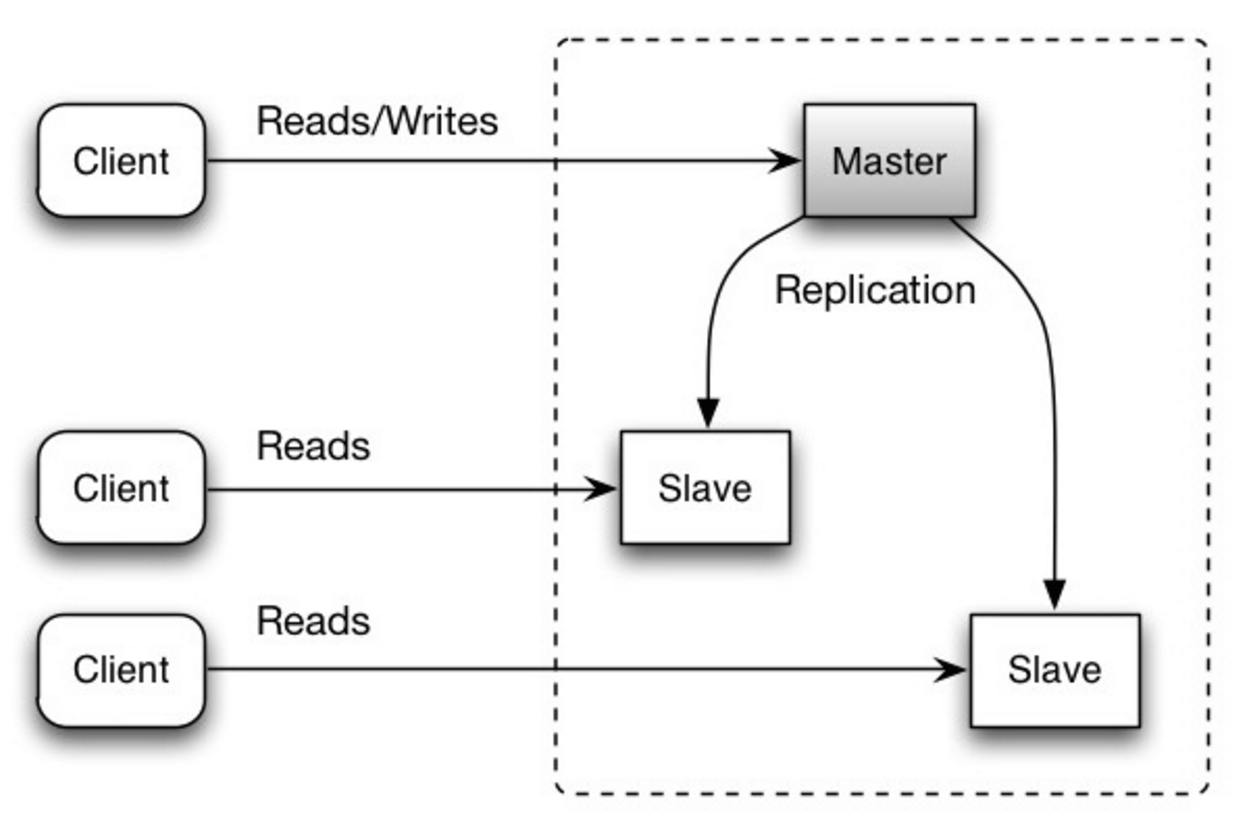
出典: スケーラビリティ、可用性、安定性、パターン
どちらのマスターも読み取りと書き込みを実行し、書き込み時に相互に調整します。いずれかのマスターがダウンしても、システムは読み取りと書き込みの両方で動作を継続できます。
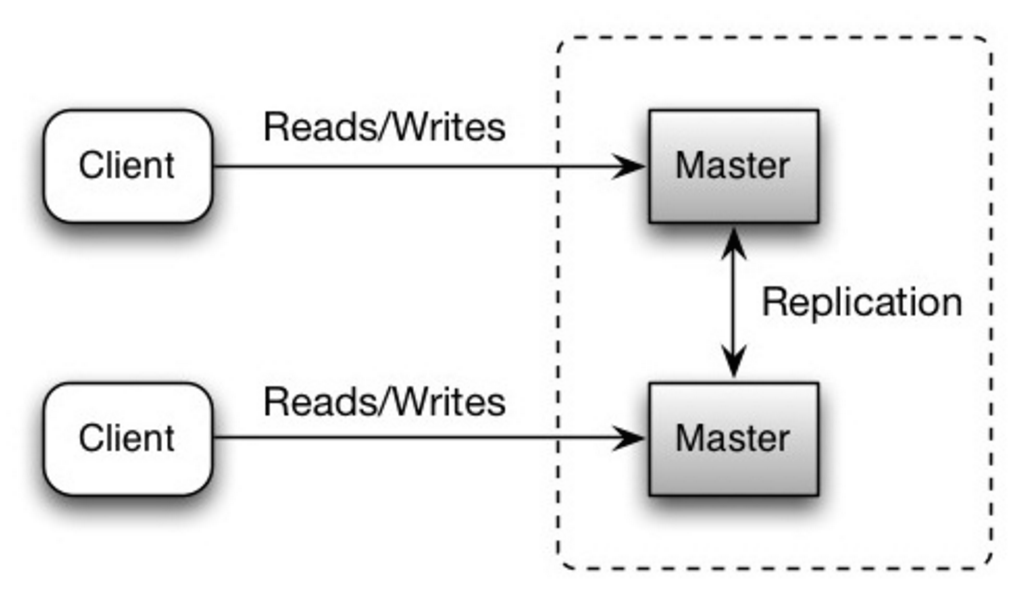
出典: スケーラビリティ、可用性、安定性、パターン
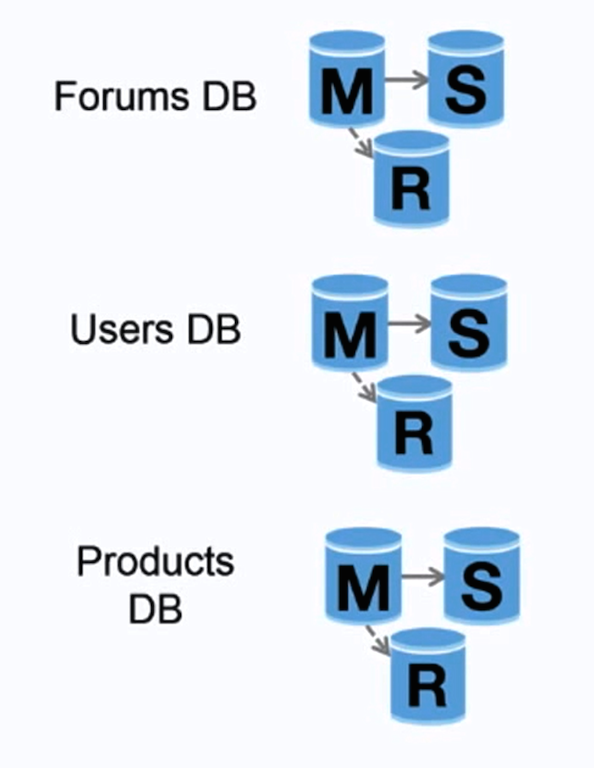
出典: 最初の 1,000 万ユーザーまでのスケールアップ
フェデレーション (または機能分割) は、データベースを機能ごとに分割します。たとえば、単一のモノリシック データベースの代わりに、 forums 、 users 、 products の3 つのデータベースを作成すると、各データベースへの読み取りおよび書き込みトラフィックが減り、レプリケーション ラグが少なくなります。データベースが小さいほど、メモリに収まるデータが多くなり、キャッシュの局所性が向上するため、キャッシュ ヒットも増加します。書き込みをシリアル化する単一の中央マスターが存在しないため、並列書き込みが可能になり、スループットが向上します。
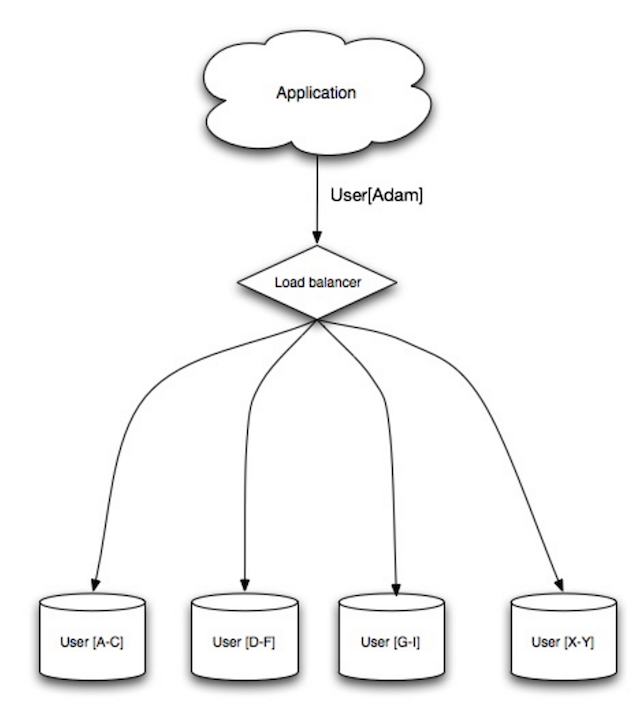
出典: スケーラビリティ、可用性、安定性、パターン
シャーディングは、各データベースがデータのサブセットのみを管理できるように、異なるデータベースにデータを分散します。ユーザー データベースを例にとると、ユーザーの数が増えると、より多くのシャードがクラスターに追加されます。
フェデレーションの利点と同様に、シャーディングにより読み取りおよび書き込みトラフィックが減少し、レプリケーションが減少し、キャッシュ ヒットが増加します。インデックス サイズも小さくなり、一般にクエリが高速化されてパフォーマンスが向上します。 1 つのシャードがダウンしても、他のシャードは引き続き動作しますが、データの損失を避けるために何らかの形式のレプリケーションを追加する必要があります。フェデレーションと同様に、書き込みをシリアル化する単一の中央マスターが存在しないため、スループットを向上させながら並行して書き込みを行うことができます。
ユーザーのテーブルをシャーディングする一般的な方法は、ユーザーの姓のイニシャルまたはユーザーの地理的位置を使用することです。
非正規化は、いくつかの書き込みパフォーマンスを犠牲にして読み取りパフォーマンスを改善しようとします。データの冗長なコピーは、高価な結合を避けるために複数のテーブルに記述されています。 PostgreSQLやOracleなどの一部のRDBMは、冗長な情報を保存し、冗長コピーを一貫して保持する作業を処理する具体化されたビューをサポートしています。
フェデレーションやシャードなどの手法でデータが分散されると、データセンター全体で結合することは、複雑さをさらに高めます。非正規化は、そのような複雑な結合の必要性を回避する可能性があります。
ほとんどのシステムでは、読み取りは100:1または1000:1さえも大幅に上の書き込みを行うことができます。複雑なデータベース結合をもたらす読み取りは非常に高価であり、ディスク操作にかなりの時間を費やすことができます。
SQLチューニングは幅広いトピックであり、多くの本が参照として書かれています。
ボトルネックをシミュレートして明らかにするために、ベンチマークとプロファイルが重要です。
ベンチマークとプロファイリングは、次の最適化を指す場合があります。
VARCHARの代わりにCHAR使用します。CHAR効果的に高速でランダムなアクセスを可能にしますが、 VARCHAR使用すると、次の文字列に移動する前に文字列の終わりを見つける必要があります。TEXT使用します。 TEXTでは、ブール検索も可能です。 TEXTフィールドを使用すると、テキストブロックを見つけるために使用されるディスクにポインターを保存します。INT使用します。DECIMAL使用して、浮動小数点表現エラーを回避します。BLOBS保存しないでください。代わりにオブジェクトを取得する場所の場所を保管してください。VARCHAR(255)は、8ビット数でカウントできる最大数の文字であり、多くの場合、一部のRDBMでバイトの使用を最大化します。NOT NULL制約を設定します。 SELECT 、 GROUP BY 、 ORDER BY 、 JOIN )は、インデックスを使用すると高速になる可能性があります。NOSQLは、キー価値ストア、ドキュメントストア、ワイドコラムストア、またはグラフデータベースで表されるデータ項目のコレクションです。データは非正規化され、結合は通常、アプリケーションコードで行われます。ほとんどのNOSQLストアには、真の酸トランザクションがなく、最終的な一貫性を支持しています。
ベースは、NOSQLデータベースのプロパティを記述するためによく使用されます。キャップ定理と比較して、ベースは一貫性よりも可用性を選択します。
SQLまたはNOSQLのいずれかを選択することに加えて、どのタイプのNOSQLデータベースがユースケースに最適なタイプに最適なものを理解することが役立ちます。次のセクションでは、キーと価値のあるストア、ドキュメントストア、幅広の列ストア、グラフデータベースを確認します。
抽象化:ハッシュテーブル
通常、キーと価値のあるストアは、O(1)が読み取り、書き込みを可能にし、多くの場合、メモリまたはSSDによって裏付けられています。データストアは、キーを辞書的な順序で維持することができ、キー範囲の効率的な取得を可能にします。キー価値ストアでは、メタデータを値で保存できます。
キー価値ストアは高性能を提供し、多くの場合、単純なデータモデルや、メモリ内キャッシュ層などの急速に変化するデータに使用されます。限られた操作セットのみを提供するため、追加の操作が必要な場合は、複雑さがアプリケーションレイヤーにシフトされます。
キー価値ストアは、ドキュメントストアなどのより複雑なシステムの基礎であり、場合によってはグラフデータベースです。
抽象化:値として保存されたドキュメントを備えたキー値ストア
ドキュメントストアは、ドキュメント(XML、JSON、バイナリなど)を中心としており、ドキュメントは特定のオブジェクトのすべての情報を保存します。ドキュメントストアは、ドキュメント自体の内部構造に基づいて、APIまたはクエリ言語をクエリするクエリ言語を提供します。注、多くのキー価値ストアには、値のメタデータを操作するための機能が含まれており、これら2つのストレージタイプ間のラインを曖昧にします。
基礎となる実装に基づいて、ドキュメントはコレクション、タグ、メタデータ、またはディレクトリによって編成されています。ドキュメントは一緒に整理またはグループ化できますが、ドキュメントには互いに完全に異なるフィールドがある場合があります。
MongoDBやCouchDBなどのドキュメントストアの一部は、複雑なクエリを実行するためのSQLのような言語も提供しています。 DynamoDBは、キー価値とドキュメントの両方をサポートしています。
ドキュメントストアは柔軟性が高く、時折変更されたデータで作業するためによく使用されます。
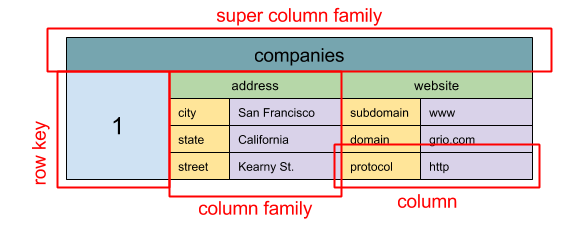
出典:SQL&NOSQL、簡単な履歴
抽象化:ネストされたマップ
ColumnFamily<RowKey, Columns<ColKey, Value, Timestamp>>
幅広の列ストアの基本ユニットのデータは、列(名前/値ペア)です。列は、列ファミリにグループ化できます(SQLテーブルに類似)。スーパーコラムファミリーさらにグループ列家族。行キーと、同じ行キーを持つ列を行のある列を使用して、各列に個別にアクセスできます。各値には、バージョン化と紛争解決のためのタイムスタンプが含まれています。
Googleは、Bigtableを最初のワイドコラムストアとして導入しました。これは、Hadoopエコシステムでよく使用されるオープンソースのHBaseとFacebookのCassandraに影響を与えました。 Bigtable、Hbase、Cassandraなどのストアは、辞書編集順に鍵を維持し、選択的キー範囲の効率的な検索を可能にします。
ワイドコラムストアは、高可用性と高いスケーラビリティを提供します。非常に大きなデータセットに使用されることがよくあります。
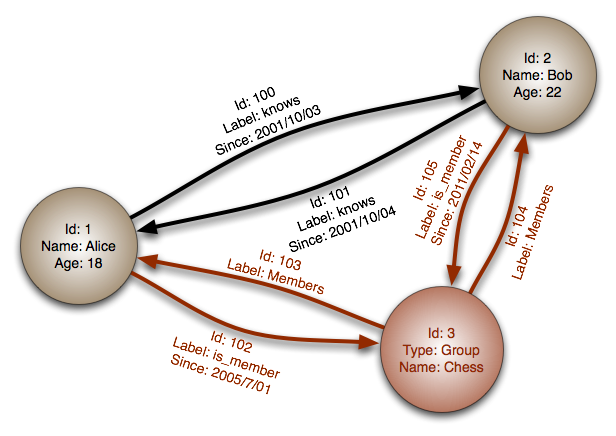
出典:グラフデータベース
抽象化:グラフ
グラフデータベースでは、各ノードはレコードであり、各アークは2つのノード間の関係です。グラフデータベースは、多くの外国の鍵または多くの関係との複雑な関係を表すように最適化されています。
グラフデータベースは、ソーシャルネットワークなど、複雑な関係を持つデータモデルの高性能を提供します。それらは比較的新しいものであり、まだ広く使用されていません。開発ツールとリソースを見つけることはより難しいかもしれません。多くのグラフは、REST APIでのみアクセスできます。
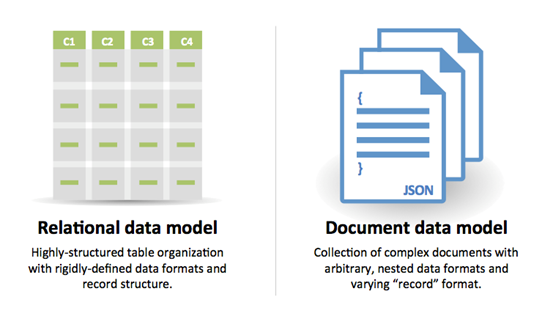
出典:RDBMSからNOSQLへの移行
SQLの理由:
NOSQLの理由:
NOSQLに適したサンプルデータ:
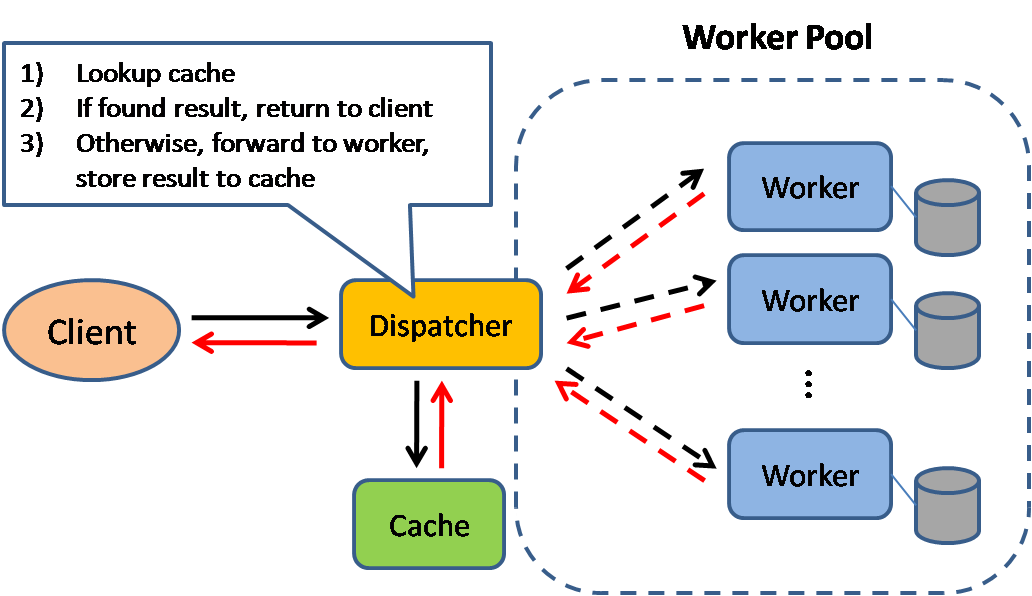
出典:スケーラブルなシステム設計パターン
キャッシュすると、ページの読み込み時間が改善され、サーバーとデータベースの負荷が減少します。このモデルでは、リクエストが以前に行われた場合にディスパッチャーが最初に検索し、実際の実行を保存するために、以前の結果を返して戻します。
データベースは、多くの場合、そのパーティション全体に読み取りと書き込みの均一な分布の恩恵を受けます。人気のあるアイテムは、分布を歪め、ボトルネックを引き起こす可能性があります。データベースの前にキャッシュを置くと、トラフィックの不均一な負荷やスパイクを吸収するのに役立ちます。
キャッシュは、クライアント側(OSまたはブラウザ)、サーバー側、または個別のキャッシュレイヤーに配置できます。
CDNはキャッシュの一種と見なされます。
逆プロキシやワニスなどのキャッシュは、静的コンテンツと動的なコンテンツを直接提供できます。 Webサーバーは、リクエストをキャッシュして、アプリケーションサーバーに連絡することなく応答を返すこともできます。
データベースには通常、一般的なユースケース用に最適化されたデフォルト構成でのある程度のキャッシュが含まれます。特定の使用パターンのためにこれらの設定を調整すると、パフォーマンスがさらに向上する可能性があります。
MemcachedやRedisなどのメモリ内キャッシュは、アプリケーションとデータストレージの間のキー価値のストアです。データはRAMに保持されているため、データがディスクに保存されている典型的なデータベースよりもはるかに高速です。 RAMはディスクよりも制限されているため、最近使用されていない(LRU)などのキャッシュ無効化アルゴリズムは、「コールド」エントリを無効にし、RAMの「ホット」データを維持するのに役立ちます。
Redisには次の追加機能があります。
2つの一般的なカテゴリに分類される複数のレベルがあります。データベースクエリとオブジェクト:
一般的に、ファイルベースのキャッシュを避けて、クローニングと自動スケーリングをより困難にするためです。
データベースを照会するたびに、クエリをキーとしてハッシュし、結果をキャッシュに保存します。このアプローチには、有効期限の問題があります。
アプリケーションコードで行うことと同様に、データをオブジェクトとして見てください。アプリケーションにデータベースからデータセットをクラスインスタンスまたはデータ構造に組み立てます。
何をキャッシュするかの提案:
限られた量のデータはキャッシュにしか保存できないため、どのキャッシュ更新戦略がユースケースに最適かを判断する必要があります。
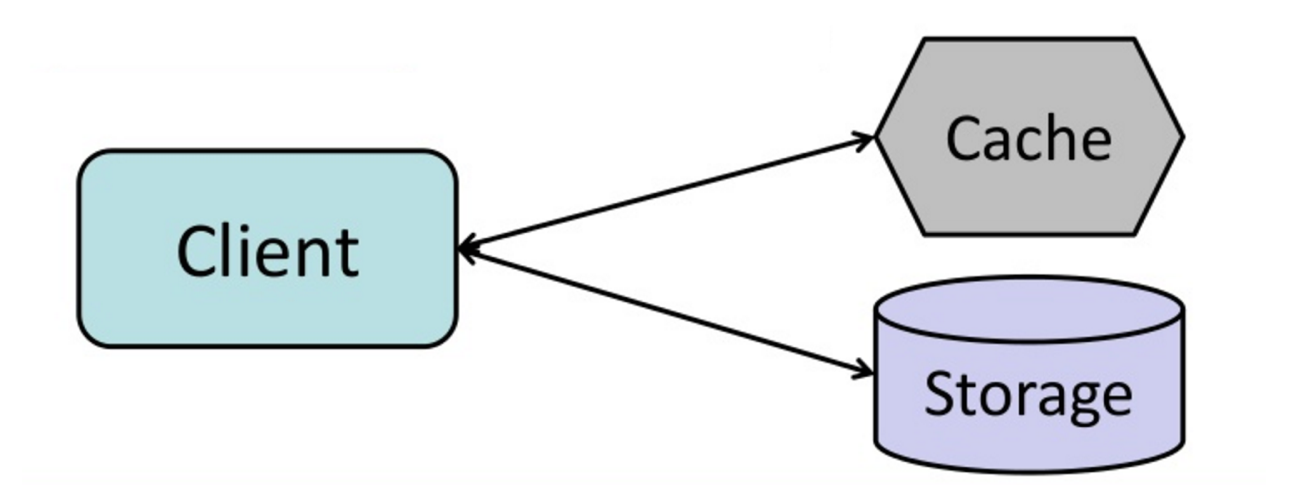
出典:キャッシュからインメモリデータグリッドまで
アプリケーションは、ストレージからの読み書きを担当します。キャッシュはストレージと直接相互作用しません。アプリケーションは次のことを行います。
def get_user ( self , user_id ):
user = cache . get ( "user.{0}" , user_id )
if user is None :
user = db . query ( "SELECT * FROM users WHERE user_id = {0}" , user_id )
if user is not None :
key = "user.{0}" . format ( user_id )
cache . set ( key , json . dumps ( user ))
return usermemcachedは一般にこの方法で使用されます。
キャッシュに追加されたデータの後続の読み取りは高速です。 Cache-Asideは、怠zyなロードとも呼ばれます。要求されたデータのみがキャッシュされているため、要求されていないデータをキャッシュに記入しないようにします。
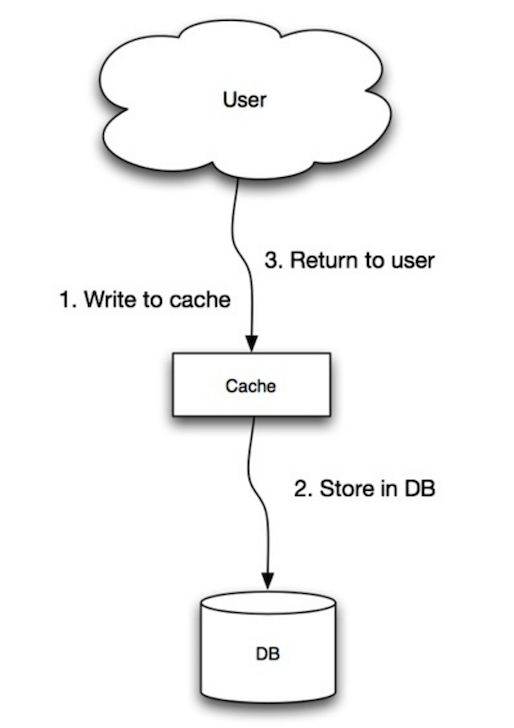
出典:スケーラビリティ、可用性、安定性、パターン
このアプリケーションは、キャッシュをメインデータストアとして使用し、データを読み取り、書き込みますが、キャッシュはデータベースの読み取りと書き込みを担当します。
アプリケーションコード:
set_user ( 12345 , { "foo" : "bar" })キャッシュコード:
def set_user ( user_id , values ):
user = db . query ( "UPDATE Users WHERE id = {0}" , user_id , values )
cache . set ( user_id , user )書き込みスルーは、書き込み操作のために全体的な操作が遅いことですが、その後の書かれたデータの読み取りは高速です。ユーザーは通常、データを読み取るよりもデータを更新する際にレイテンシに対して寛容です。キャッシュ内のデータは古くなっていません。
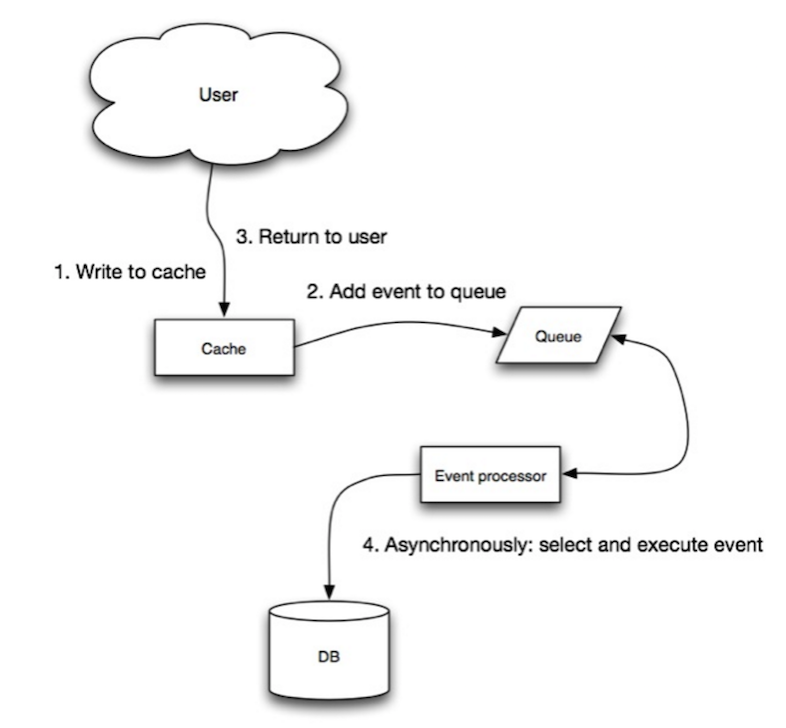
出典:スケーラビリティ、可用性、安定性、パターン
Write-Behindでは、アプリケーションは次のことを行います。
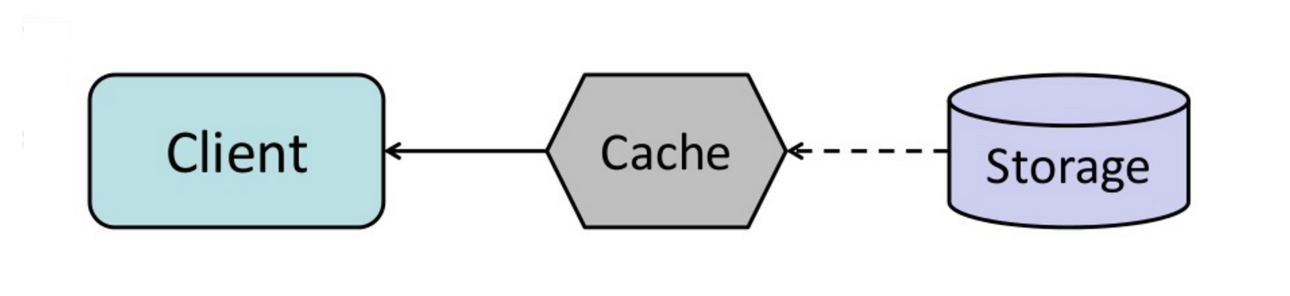
出典:キャッシュからインメモリデータグリッドまで
キャッシュを構成して、有効期限が切れる前に、最近アクセスしたキャッシュエントリを自動的に更新できます。
リフレッシュアヘッドは、キャッシュが将来どのアイテムが必要になる可能性があるかを正確に予測できる場合、レイテンシと読み取りスルーを減らすことができます。
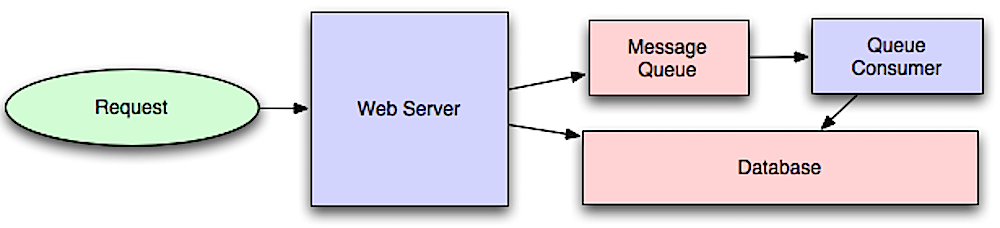
出典:スケールのためのシステムアーキテクチャティングのイントロ
非同期ワークフローは、そうでなければインラインで実行される高価な操作のリクエスト時間を短縮するのに役立ちます。また、データの定期的な集約など、事前に時間のかかる作業を行うことで支援することもできます。
メッセージキューはメッセージを受信、保持、および配信します。操作が遅すぎてインラインを実行できない場合は、次のワークフローでメッセージキューを使用できます。
ユーザーはブロックされておらず、ジョブはバックグラウンドで処理されます。この間、クライアントはオプションで少量の処理を行い、タスクが完了したように見えるようにします。たとえば、ツイートを投稿する場合、ツイートはすぐにタイムラインに投稿される可能性がありますが、ツイートが実際にすべてのフォロワーに配信されるまでには時間がかかる可能性があります。
Redisは単純なメッセージブローカーとして役立ちますが、メッセージを失う可能性があります。
RabbitMQは人気がありますが、「AMQP」プロトコルに適応し、独自のノードを管理する必要があります。
Amazon SQSはホストされていますが、高遅延を持つことができ、メッセージが2回配信される可能性があります。
タスクキューはタスクとその関連データを受信し、それらを実行し、結果を提供します。スケジューリングをサポートすることができ、バックグラウンドで計算集約型のジョブを実行するために使用できます。
セロリはスケジューリングのサポートがあり、主にPythonサポートがあります。
キューが大幅に増加し始めた場合、キューサイズはメモリよりも大きくなり、キャッシュミス、ディスクの読み取り、さらにはパフォーマンスが遅くなります。バック圧力は、キューのサイズを制限することで役立ち、それにより、すでにキューにあるジョブのスループット率と良好な応答時間を維持します。キューがいっぱいになると、クライアントはサーバーをビジーまたはHTTP 503ステータスコードを取得して、後で再試行します。クライアントは、おそらく指数関数的なバックオフで、後でリクエストを再試行することができます。
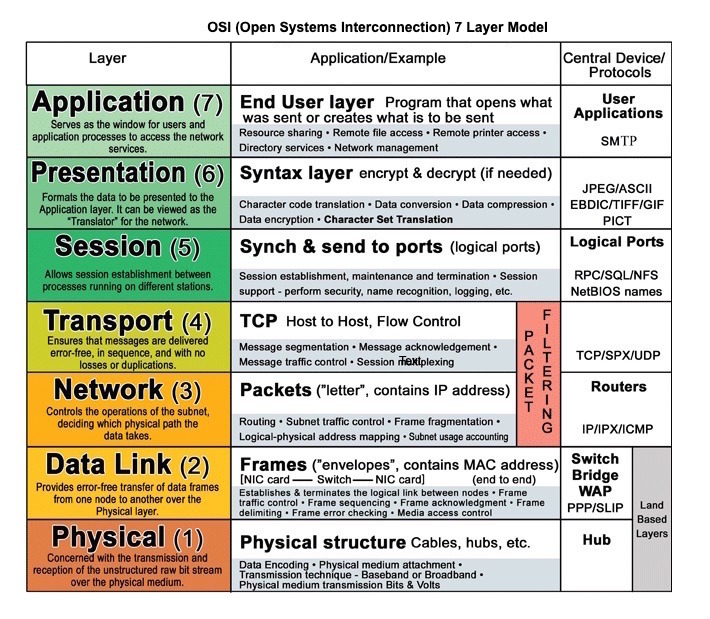
出典:OSI 7レイヤーモデル
HTTPは、クライアントとサーバー間でデータをエンコードおよび輸送する方法です。これはリクエスト/応答プロトコルです。クライアントはリクエストを発行し、サーバーは関連するコンテンツとリクエストに関する完了ステータス情報で回答を発行します。 HTTPは自己完結型であり、ロードバランス、キャッシュ、暗号化、および圧縮を実行する多くの中間ルーターとサーバーを介してリクエストと応答を流すことができます。
基本的なHTTP要求は、動詞(メソッド)とリソース(エンドポイント)で構成されています。以下は一般的なHTTP動詞です。
| 動詞 | 説明 | idempotent* | 安全 | キャッシュ可能 |
|---|---|---|---|---|
| 得る | リソースを読み取ります | はい | はい | はい |
| 役職 | リソースを作成するか、データを処理するプロセスをトリガーします | いいえ | いいえ | はい、応答に新鮮さ情報が含まれている場合 |
| 置く | リソースを作成または交換します | はい | いいえ | いいえ |
| パッチ | リソースを部分的に更新します | いいえ | いいえ | はい、応答に新鮮さ情報が含まれている場合 |
| 消去 | リソースを削除します | はい | いいえ | いいえ |
*異なる結果なしで何度も呼ぶことができます。
HTTPは、 TCPやUDPなどの低レベルのプロトコルに依存するアプリケーションレイヤープロトコルです。
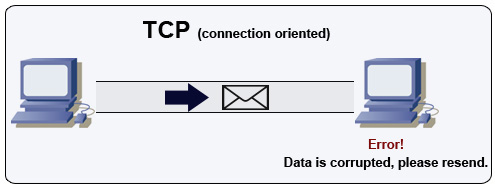
出典:マルチプレイヤーゲームの作成方法
TCPは、IPネットワーク上の接続指向プロトコルです。接続が確立され、握手を使用して終了します。送信されたすべてのパケットは、元の順序で目的地に到達することが保証されています。
送信者が正しい応答を受け取らない場合、パケットを再送信します。複数のタイムアウトがある場合、接続が削除されます。 TCPはまた、フロー制御と輻輳制御を実装します。これらの保証は遅延を引き起こし、一般にUDPよりも効率的な伝送をもたらします。
高いスループットを確保するために、Webサーバーは多数のTCP接続を開いたままにしておくことができ、メモリの使用量が高くなります。 Webサーバースレッドとたとえば、Memcached Serverとの間に多数のオープン接続を持つことは費用がかかる場合があります。接続プーリングは、該当する場合にUDPへの切り替えに加えて役立ちます。
TCPは、高い信頼性を必要とするが、時間が少ないアプリケーションに役立ちます。いくつかの例には、Webサーバー、データベース情報、SMTP、FTP、およびSSHが含まれます。
次の場合はUDPでTCPを使用します
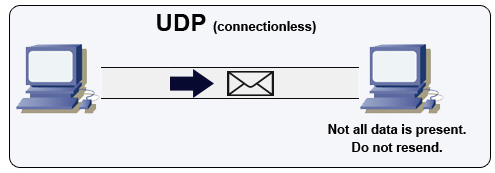
出典:マルチプレイヤーゲームの作成方法
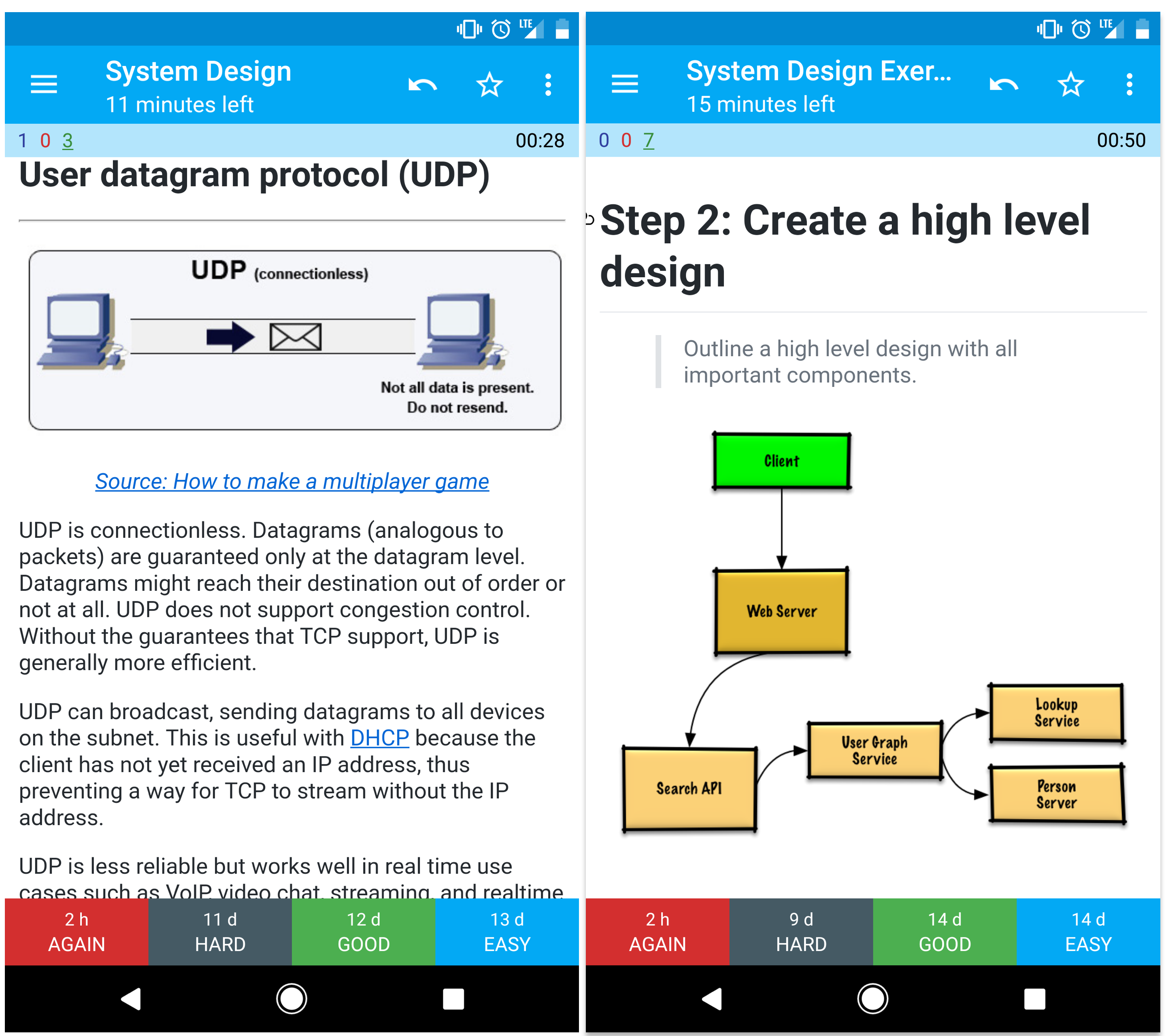
UDPはコネクションレスです。データグラム(パケットに類似)は、データグラムレベルでのみ保証されます。データグラムは、目的地が故障しないか、まったく到達しない場合があります。 UDPは混雑制御をサポートしていません。 TCPサポートの保証がなければ、UDPは一般的により効率的です。
UDPはブロードキャストして、サブネット上のすべてのデバイスにデータグラムを送信できます。これは、クライアントがまだIPアドレスを受信していないため、DHCPで役立ちます。したがって、IPアドレスなしでTCPがストリーミングする方法を防ぎます。
UDPは信頼性が低いですが、VoIP、ビデオチャット、ストリーミング、リアルタイムマルチプレイヤーゲームなどのリアルタイムユースケースではうまく機能します。
TCPでUDPを使用してください。
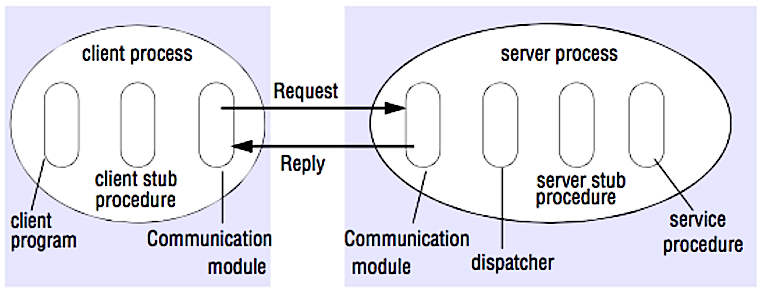
出典:システム設計インタビューをクラックします
RPCでは、クライアントは、通常はリモートサーバーである別のアドレススペースで手順を実行します。手順は、それがローカル手順呼び出しのようにコーディングされ、クライアントプログラムからサーバーと通信する方法の詳細を抽象化します。リモートコールは通常、ローカルコールよりも遅く、信頼性が低いため、RPCコールをローカルコールと区別すると役立ちます。人気のあるRPCフレームワークには、Protobuf、Thrift、Avroが含まれます。
RPCはリクエスト応答プロトコルです。
サンプルRPC呼び出し:
GET /someoperation?data=anId
POST /anotheroperation
{
"data":"anId";
"anotherdata": "another value"
}
RPCは、行動の公開に焦点を当てています。 RPCは、ユースケースに適合してネイティブコールを手作りすることができるため、内部通信のパフォーマンス上の理由でよく使用されます。
ネイティブライブラリ(別名SDK)を選択してください。
休憩後のHTTP APIは、公共APIに頻繁に使用される傾向があります。
RESTは、クライアント/サーバーモデルを強制するアーキテクチャスタイルであり、クライアントがサーバーが管理する一連のリソースで動作します。サーバーは、リソースとアクションの表現を提供し、リソースの新しい表現を操作または取得できます。すべてのコミュニケーションは、ステートレスでキャッシュ可能でなければなりません。
安らかなインターフェイスには4つの品質があります。
サンプルレストコール:
GET /someresources/anId
PUT /someresources/anId
{"anotherdata": "another value"}
RESTはデータの公開に焦点を当てています。クライアント/サーバー間の結合を最小限に抑え、パブリックHTTP APIによく使用されます。 RESTは、URIを介してリソースを公開するより一般的で均一な方法、ヘッダーを介した表現、およびGet、Post、Put、Delete、Patchなどの動詞を介したアクションを使用します。ステートレスであるため、休息は水平方向のスケーリングとパーティション化に最適です。
| 手術 | RPC | 休む |
|---|---|---|
| サインアップ | 投稿/サインアップ | 投稿/人 |
| 辞任する | ポスト/辞任 { 「ペンペルペンディッド」:「1234」 } | 削除/人 /1234 |
| 人を読んでください | get /readperson?personid = 1234 | get /persons /1234 |
| 人のアイテムリストを読んでください | get /readusistemslist?personid = 1234 | get /persons/1234/items |
| 人のアイテムにアイテムを追加します | POST /ADDITOUSERSITEMSLIST { 「PersonID」:「1234」; 「Itemid」:「456」 } | post /persons/1234/items { 「Itemid」:「456」 } |
| アイテムを更新します | POST /MODIFYITEM { 「Itemid」:「456」; 「キー」:「値」 } | put /items /456 { 「キー」:「値」 } |
| 項目を削除する | post /removeItem { 「Itemid」:「456」 } | 削除/アイテム /456 |
出典:RPCよりも休むことを好む理由を本当に知っていますか
このセクションでは、いくつかの更新を使用できます。貢献を検討してください!
セキュリティは幅広いトピックです。かなりの経験、セキュリティのバックグラウンド、またはセキュリティの知識を必要とするポジションを申請していない限り、おそらく基本以上のことを知る必要はありません。
「エンベロープの背中」の見積もりを行うように求められることがあります。たとえば、ディスクから100個の画像サムネイルを生成するのにかかる時間、またはデータ構造が取るメモリの量を判断する必要がある場合があります。すべてのプログラマーが知っておくべき2つのテーブルとレイテンシー番号のパワーは、便利な参照です。
Power Exact Value Approx Value Bytes
---------------------------------------------------------------
7 128
8 256
10 1024 1 thousand 1 KB
16 65,536 64 KB
20 1,048,576 1 million 1 MB
30 1,073,741,824 1 billion 1 GB
32 4,294,967,296 4 GB
40 1,099,511,627,776 1 trillion 1 TB
Latency Comparison Numbers
--------------------------
L1 cache reference 0.5 ns
Branch mispredict 5 ns
L2 cache reference 7 ns 14x L1 cache
Mutex lock/unlock 25 ns
Main memory reference 100 ns 20x L2 cache, 200x L1 cache
Compress 1K bytes with Zippy 10,000 ns 10 us
Send 1 KB bytes over 1 Gbps network 10,000 ns 10 us
Read 4 KB randomly from SSD* 150,000 ns 150 us ~1GB/sec SSD
Read 1 MB sequentially from memory 250,000 ns 250 us
Round trip within same datacenter 500,000 ns 500 us
Read 1 MB sequentially from SSD* 1,000,000 ns 1,000 us 1 ms ~1GB/sec SSD, 4X memory
HDD seek 10,000,000 ns 10,000 us 10 ms 20x datacenter roundtrip
Read 1 MB sequentially from 1 Gbps 10,000,000 ns 10,000 us 10 ms 40x memory, 10X SSD
Read 1 MB sequentially from HDD 30,000,000 ns 30,000 us 30 ms 120x memory, 30X SSD
Send packet CA->Netherlands->CA 150,000,000 ns 150,000 us 150 ms
Notes
-----
1 ns = 10^-9 seconds
1 us = 10^-6 seconds = 1,000 ns
1 ms = 10^-3 seconds = 1,000 us = 1,000,000 ns
上記の数字に基づく便利な指標:
一般的なシステム設計インタビューの質問。それぞれを解決する方法に関するリソースへのリンクを備えています。
| 質問 | 参考文献 |
|---|---|
| Dropboxのようなファイル同期サービスを設計します | youtube.com |
| Googleのような検索エンジンを設計します | queue.acm.org stackexchange.com ardendertat.com スタンフォード教育 |
| GoogleのようなスケーラブルなWebクローラーを設計します | クオラ.com |
| Googleドキュメントを設計します | code.google.com Neil.Fraser.Name |
| Redisのようなキー価値ストアを設計します | slideshare.net |
| Memcachedのようなキャッシュシステムを設計します | slideshare.net |
| Amazonのような推奨システムを設計します | hulu.com ijcai13.org |
| BitlyのようなTinyurlシステムを設計します | n00tc0d3r.blogspot.com |
| WhatsAppのようなチャットアプリを設計します | highscalability.com |
| Instagramのような画像共有システムをデザインします | highscalability.com highscalability.com |
| Facebookニュースフィード機能を設計します | クオラ.com クオラ.com slideshare.net |
| Facebookタイムライン関数を設計します | フェイスブック.com highscalability.com |
| Facebookチャット機能を設計します | erlangfactory.com フェイスブック.com |
| Facebookのようなグラフ検索機能を設計します | フェイスブック.com フェイスブック.com フェイスブック.com |
| CloudFlareのようなコンテンツ配信ネットワークを設計します | figshare.com |
| Twitterのようなトレンドトピックシステムを設計します | Michael-noll.com snikolov .wordpress.com |
| ランダムID生成システムを設計します | blog.twitter.com github.com |
| 時間間隔中にトップKリクエストを返します | cs.ucsb.edu wpi.edu |
| 複数のデータセンターからのデータを提供するシステムを設計する | highscalability.com |
| オンラインマルチプレイヤーカードゲームを設計します | indieflashblog.com buildnewgames.com |
| ごみ収集システムを設計します | Stuffwithstuff.com Washington.edu |
| APIレートリミッターを設計します | https://stripe.com/blog/ |
| 証券取引所を設計する(NasdaqやBinanceなど) | ジェーン・ストリート Golangの実装 実装に移動します |
| システム設計の質問を追加します | 貢献する |
Real World Systemsの設計方法に関する記事。
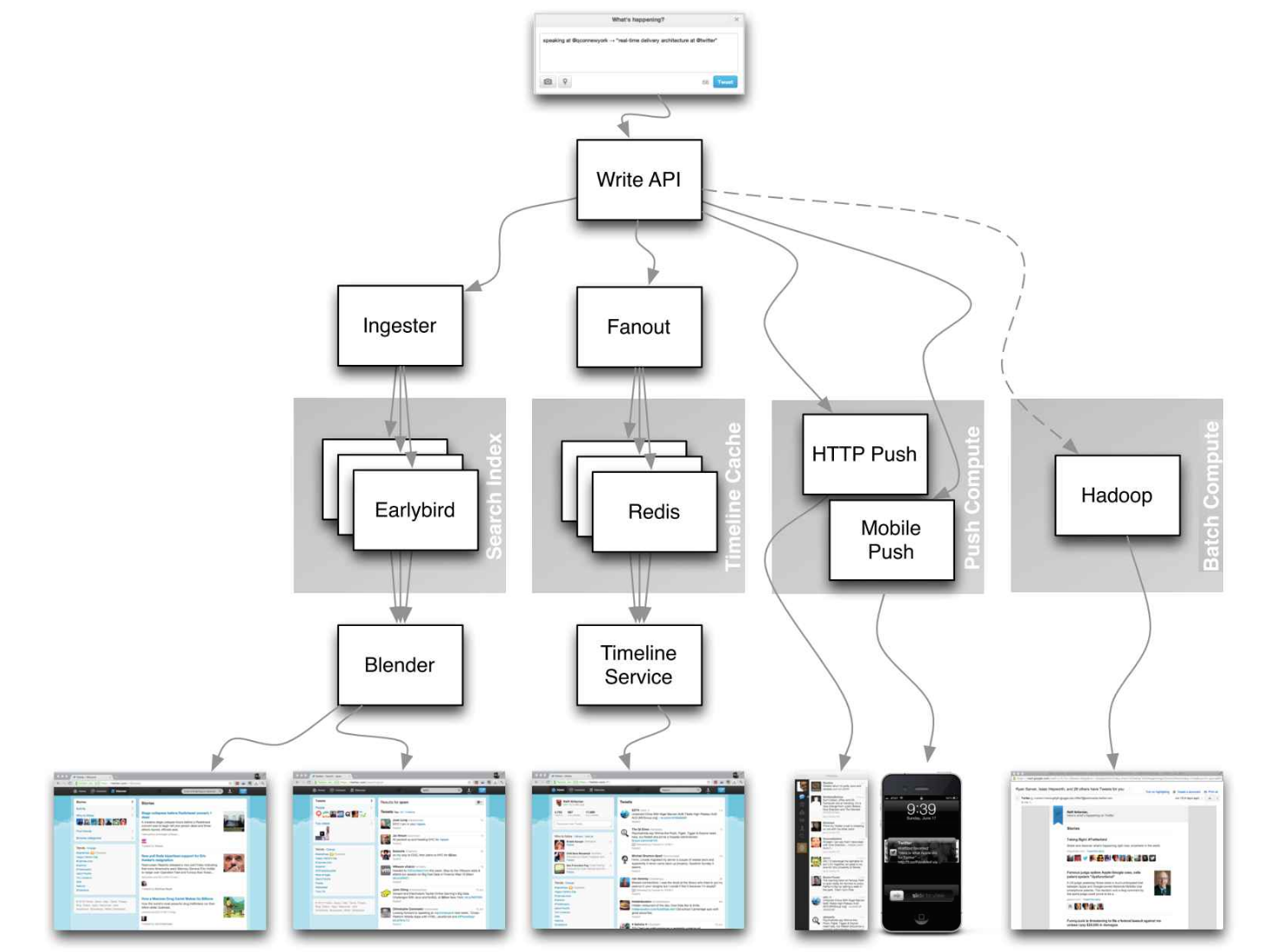
出典:大規模なTwitterタイムライン
代わりに、次の記事の核心の詳細に焦点を当てないでください。
| タイプ | システム | 参考文献 |
|---|---|---|
| データ処理 | MapReduce- Googleからの分散データ処理 | Research.Google.com |
| データ処理 | Spark-データビックからの分散データ処理 | slideshare.net |
| データ処理 | ストーム- Twitterからの分散データ処理 | slideshare.net |
| データストア | Bigtable- Googleから分散列指向データベース | harvard.edu |
| データストア | HBase- Bigtableのオープンソース実装 | slideshare.net |
| データストア | Cassandra- Facebookからの分散列指向データベース | slideshare.net |
| データストア | DynamodB- Amazonのドキュメント指向データベース | harvard.edu |
| データストア | MongoDB-ドキュメント指向のデータベース | slideshare.net |
| データストア | Spanner- Googleからグローバルに分散したデータベース | Research.Google.com |
| データストア | Memcached-分散メモリキャッシングシステム | slideshare.net |
| データストア | Redis-持続性と価値タイプの分散メモリキャッシングシステム | slideshare.net |
| ファイルシステム | Googleファイルシステム(GFS) - 分散ファイルシステム | Research.Google.com |
| ファイルシステム | Hadoopファイルシステム(HDFS) - GFSのオープンソース実装 | apache.org |
| その他 | Chubby -Googleからのゆるく結合された分散システムのためのロックサービス | Research.Google.com |
| その他 | Dapper-インフラストラクチャを追跡する分散システム | Research.Google.com |
| その他 | Kafka -LinkedInからのパブ/サブメッセージキュー | slideshare.net |
| その他 | Zookeeper-同期を可能にする集中インフラストラクチャとサービス | slideshare.net |
| アーキテクチャを追加します | 貢献する |
| 会社 | 参考文献 |
|---|---|
| アマゾン | Amazonアーキテクチャ |
| cinchcast | 毎日1,500時間のオーディオを生産しています |
| DataSift | Realtime datamining At 120,000 tweets per second |
| ドロップボックス | How we've scaled Dropbox |
| ESPN | Operating At 100,000 duh nuh nuhs per second |
| グーグル | Google architecture |
| インスタグラム | 14 million users, terabytes of photos What powers Instagram |
| Justin.tv | Justin.Tv's live video broadcasting architecture |
| フェイスブック | Scaling memcached at Facebook TAO: Facebook's distributed data store for the social graph Facebook's photo storage How Facebook Live Streams To 800,000 Simultaneous Viewers |
| フリッカー | Flickr architecture |
| メールボックス | From 0 to one million users in 6 weeks |
| Netflix | A 360 Degree View Of The Entire Netflix Stack Netflix: What Happens When You Press Play? |
| ピンタレスト | From 0 To 10s of billions of page views a month 18 million visitors, 10x growth, 12 employees |
| Playfish | 50 million monthly users and growing |
| PlentyOfFish | PlentyOfFish architecture |
| セールスフォース | How they handle 1.3 billion transactions a day |
| スタックオーバーフロー | Stack Overflow architecture |
| トリップアドバイザー | 40M visitors, 200M dynamic page views, 30TB data |
| タンブラー | 15 billion page views a month |
| ツイッター | Making Twitter 10000 percent faster Storing 250 million tweets a day using MySQL 150M active users, 300K QPS, a 22 MB/S firehose Timelines at scale Big and small data at Twitter Operations at Twitter: scaling beyond 100 million users How Twitter Handles 3,000 Images Per Second |
| ウーバー | How Uber scales their real-time market platform Lessons Learned From Scaling Uber To 2000 Engineers, 1000 Services, And 8000 Git Repositories |
| ワッツアップ | The WhatsApp architecture Facebook bought for $19 billion |
| YouTube | YouTube scalability YouTube architecture |
Architectures for companies you are interviewing with.
Questions you encounter might be from the same domain.
Looking to add a blog? To avoid duplicating work, consider adding your company blog to the following repo:
Interested in adding a section or helping complete one in-progress?貢献する!
Credits and sources are provided throughout this repo.
特別な感謝:
Feel free to contact me to discuss any issues, questions, or comments.
My contact info can be found on my GitHub page.
I am providing code and resources in this repository to you under an open source license. Because this is my personal repository, the license you receive to my code and resources is from me and not my employer (Facebook).
Copyright 2017 Donne Martin
Creative Commons Attribution 4.0 International License (CC BY 4.0)
http://creativecommons.org/licenses/by/4.0/


