LLaMA Omni
1.0.0
著者:青色の牙、Soutao Guo、Yan Zhou、Zhengrui MA、Shaolei Zhang、Yang Feng*
llama-omniは、llama-3.1-8b-instructに基づいて構築された音声言語モデルです。低遅延および高品質の音声相互作用をサポートし、同時に音声指示に基づいてテキストと音声応答の両方を生成します。
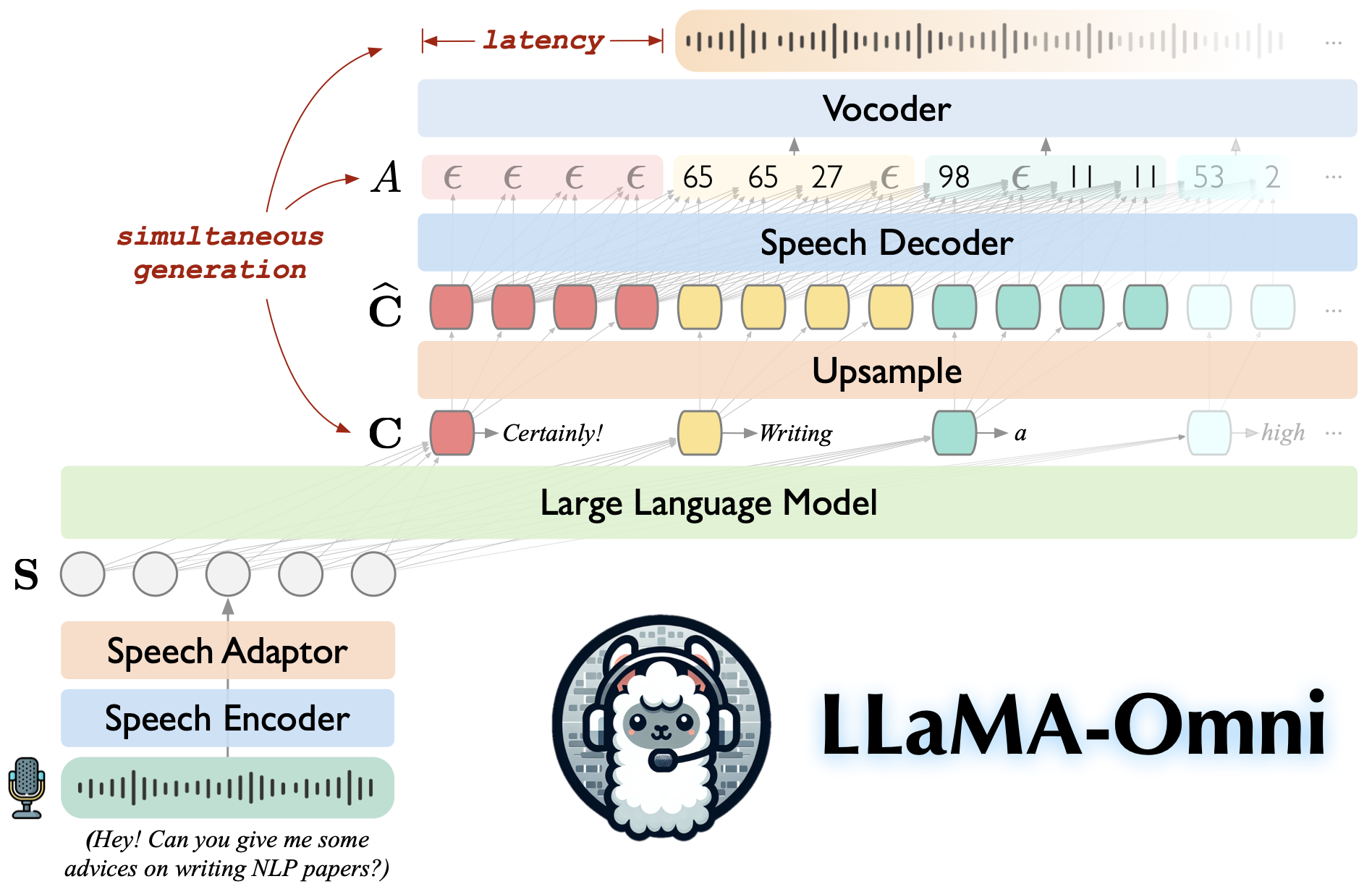
llama-3.1-8b-instructに構築され、高品質の応答が確保されます。
226msという低いレイテンシとの低遅延の音声相互作用。
テキストと音声応答の両方の同時生成。
たった4 GPUを使用して、3日以内に訓練されています。
このリポジトリをクローンします。
git clone https://github.com/ictnlp/llama-omnicd llama-omni
パッケージをインストールします。
Conda Create -N llama -omni python = 3.10 コンドラはllama-omniを活性化します PIPインストールPIP == 24.0 ピップインストール-e。
fairseqをインストールします。
git clone https://github.com/pytorch/fairseqcd fairseq ピップインストール-e。 - ノービルドイソル化
flash-attentionをインストールします。
PIPインストールFlash-attn - ノービルドイソル化
huggingfaceからLlama-3.1-8B-Omniモデルをダウンロードします。
Whisper-large-v3モデルをダウンロードしてください。
ささやきをインポートします Model = whisper.load_model( "large-v3"、download_root = "Models/Speech_Encoder/")
ユニットベースのHIFI-GANボコーダーをダウンロードします。
wget https://dl.fbaipbublicfiles.com/fairseq/speech_to_speech/vocoder/code_hifigan/mhubert_ven_es_fr_it3_400k_layer11_km1000_lj/g/g_00500000-vocoder/ Wget https://dl.fbaipbublicfiles.com/fairseq/speech_to_speech/vocoder/code_hifigan/mhubert_ven_es_fr_it3_400k_layer11_km1000_lj/config.json -vocoder/
コントローラーを起動します。
python -m omni_speech.serve.controller - host 0.0.0.0-ポート10000
Gradio Webサーバーを起動します。
python -m omni_speech.serve.gradio_web_server - コントローラーhttp:// localhost:10000-port 8000 - model-list-mode reload -vocoder vocoder/g_00500000 -vocoder-cfg vocoder/config.jsonson
モデルワーカーを起動します。
python -m omni_speech.serve.model_worker - host 0.0.0.0-コントローラーhttp:// localhost:10000-port 40000 -worker http:// localhost:40000 - model-path llama-3.1-8b-omnini -Model-Name llama-3.1-8b-omni - s2s
http:// localhost:8000/にアクセスし、llama-3.1-8b-omniと対話してください!
注:Gradioでのストリーミングオーディオ再生の不安定性により、オートプレイを有効にせずにストリーミングオーディオ合成を実装するだけです。良い解決策がある場合は、PRをお気軽に送信してください。ありがとう!
局所的に推論を実行するには、 omni_speech/infer/examplesディレクトリの形式に従って音声命令ファイルを整理してから、次のスクリプトを参照してください。
bash omni_speech/yems/run.sh omni_speech/yems/embly/examples
私たちのコードは、Apache-2.0ライセンスの下でリリースされます。私たちのモデルは、学術研究の目的のみを目的としており、商業目的では使用できません。
次の条件が満たされている場合、このモデルは自由に使用、変更、および分配できます。
非営利目的:このモデルは、商業目的で使用されない場合があります。
引用:研究でこのモデルを使用する場合は、元の作品を引用してください。
商用利用の問い合わせや商用ライセンスの取得については、 [email protected]にお問い合わせください。
Llava:私たちが構築したコードベース。
Slam-llm:スピーチエンコーダーと音声アダプターに関するコードを借ります。
ご質問がある場合は、問題をお気軽に送信するか、 [email protected]にお問い合わせください。
私たちの仕事があなたに役立つなら、次のように引用してください
@article{fang-etal-2024-llama-omni,
title={LLaMA-Omni: Seamless Speech Interaction with Large Language Models},
author={Fang, Qingkai and Guo, Shoutao and Zhou, Yan and Ma, Zhengrui and Zhang, Shaolei and Feng, Yang},
journal={arXiv preprint arXiv:2409.06666},
year={2024}
} 

