DeepKE
DeepKE 2.2.7
영어 | 简体中文
딥러닝 기반 지식 추출 툴킷
지식 그래프 구축을 위한
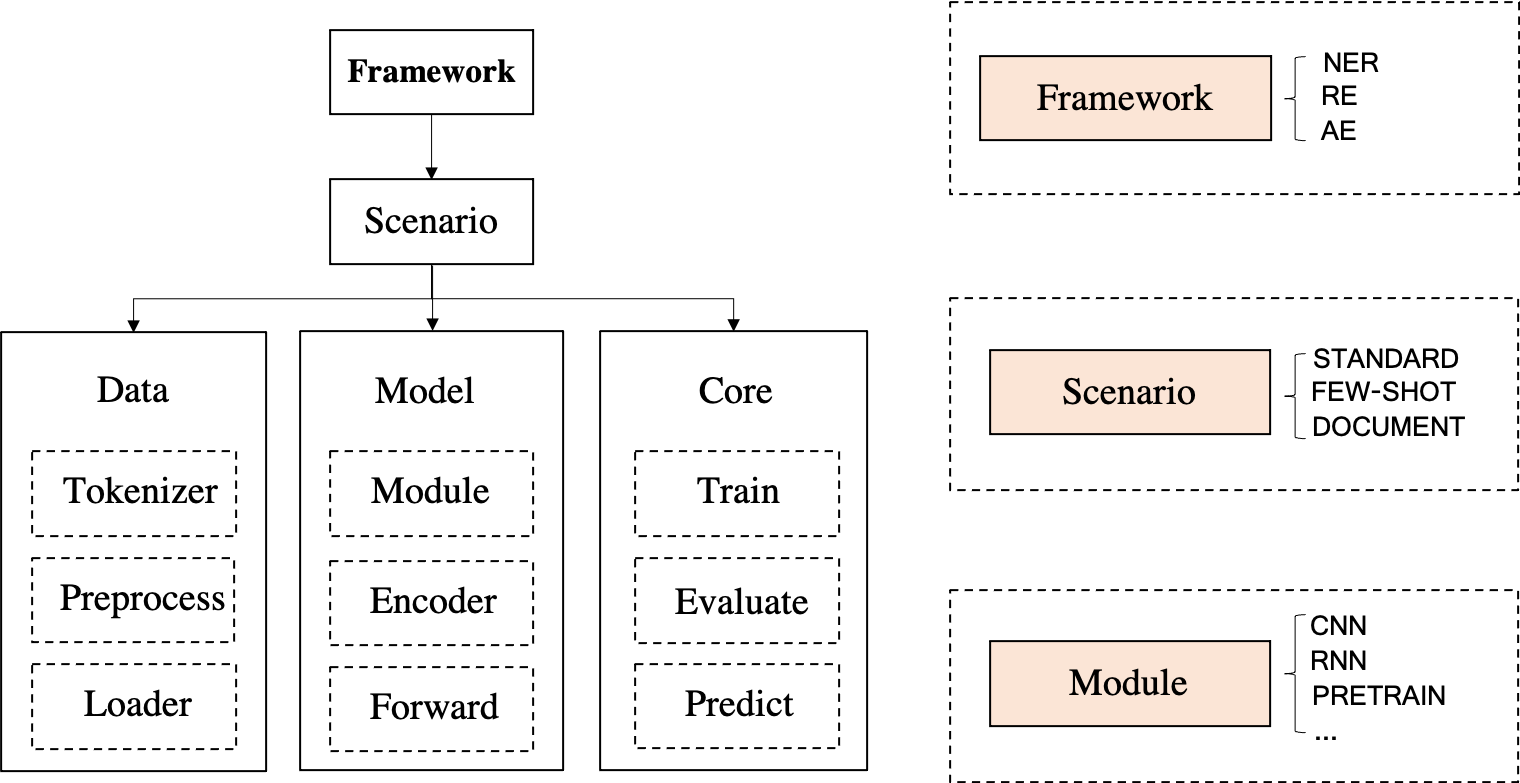
DeepKE는 엔터티 , 관계 및 속성 추출을 위한 cnSchema , 저자원 , 문서 수준 및 다중 모드 시나리오를 지원하는 지식 그래프 구성을 위한 지식 추출 툴킷입니다. 초보자를 위한 문서, 온라인 데모, 종이, 슬라이드, 포스터를 제공합니다.
\ 사용하십시오.wisemodel 또는 modescape 사용을 고려해 보세요.DeepKE 및 DeepKE-LLM 설치 중 문제가 발생하는 경우 팁을 확인하거나 즉시 문제를 제출해 주시면 문제 해결을 도와드리겠습니다!
April, 2024 Chinese-Alpaca-2-13B를 기반으로 OneKE라는 새로운 이중 언어(중국어 및 영어) 스키마 기반 정보 추출 모델을 출시합니다.Feb, 2024 IEPile 로 훈련된 두 가지 모델인 baichuan2-13b-iepile-lora 및 llama2와 함께 IEPile이라는 대규모(0.32B 토큰) 고품질 이중 언어(중국어 및 영어) 정보 추출(IE) 지침 데이터 세트를 출시합니다. -13b-iepile-lora.Sep 2023 여기에 설명된 대로 지침 기반 지식 그래프 구성 작업(명령 기반 KGC)을 위해 InstructIE 라는 이중 언어 중국어 영어 정보 추출(IE) 명령 데이터 세트가 출시되었습니다.June, 2023 KnowLM, ChatGLM, LLaMA 시리즈, GPT 시리즈 등을 통한 지식 추출을 지원하도록 DeepKE-LLM을 업데이트합니다.Apr, 2023 CP-NER(IJCAI'23), ASP(EMNLP'22), PRGC(ACL'21), PURE(NAACL'21) 등 신규 모델을 추가했으며, 이벤트 추출 기능(중국어, 영어)을 제공했으며, 더 높은 버전의 Python 패키지(예: Transformers)와의 호환성을 제공했습니다.Feb, 2023 상황 내 학습(EasyInstruct 기반) 및 데이터 생성과 함께 LLM(GPT-3) 사용을 지원하고 NER 모델 W2NER(AAAI'22)를 추가했습니다. Nov, 2022 엔터티 인식 및 관계 추출을 위한 데이터 주석 지침을 추가하고, 약한 감독 데이터의 자동 레이블 지정(엔티티 추출 및 관계 추출), 다중 GPU 교육 최적화를 수행합니다.
Sept, 2022 DeepKE: 지식 기반 인구를 위한 딥 러닝 기반 지식 추출 툴킷 논문이 EMNLP 2022 시스템 데모 트랙에 승인되었습니다.
Aug, 2022 저자원 관계 추출을 위한 데이터 증강(중국어, 영어) 지원을 추가했습니다.
June, 2022 엔터티 및 관계 추출에 대한 다중 모드 지원을 추가했습니다.
May, 2022 기성 지식 추출 모델을 갖춘 DeepKE-cnschema를 출시했습니다.
Jan, 2022 DeepKE: A Deep Learning Based Knowledge Extraction Toolkit for Knowledge Base Population 논문을 발표했습니다.
Dec, 2021 환경을 자동으로 생성하기 위해 dockerfile 추가했습니다.
Nov, 2021 배포 및 교육 없이 실시간 추출을 지원하는 DeepKE 데모가 출시되었습니다.
소스 코드, 데이터 세트 등 DeepKE의 세부 정보가 포함된 DeepKE 문서가 공개되었습니다.
Oct, 2021 pip install deepke
deepke-v2.0의 코드가 공개되었습니다.
Aug, 2019 deepke-v1.0의 코드가 공개되었습니다.
Aug, 2018 DeepKE 프로젝트 시작 및 deepke-v0.1 코드가 공개되었습니다.
예측 시연이 있습니다. GIF 파일은 Terminalizer에 의해 생성됩니다. 코드를 받으세요. 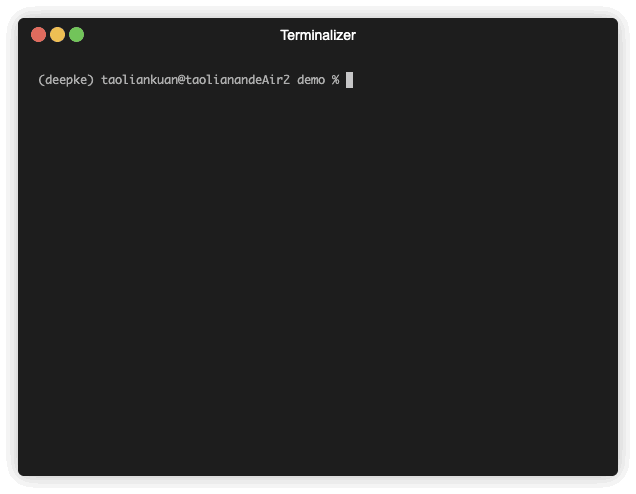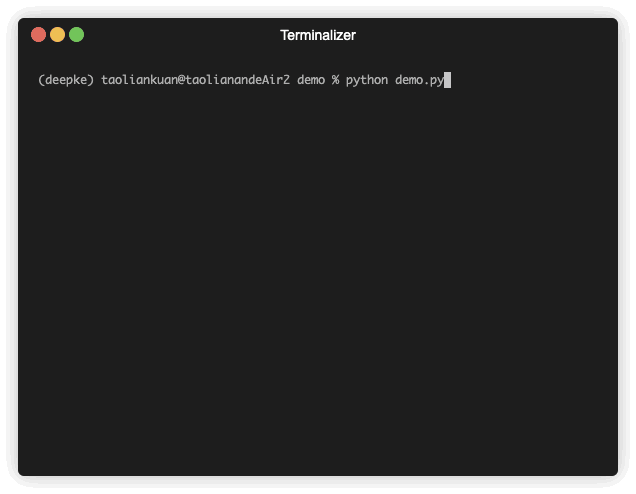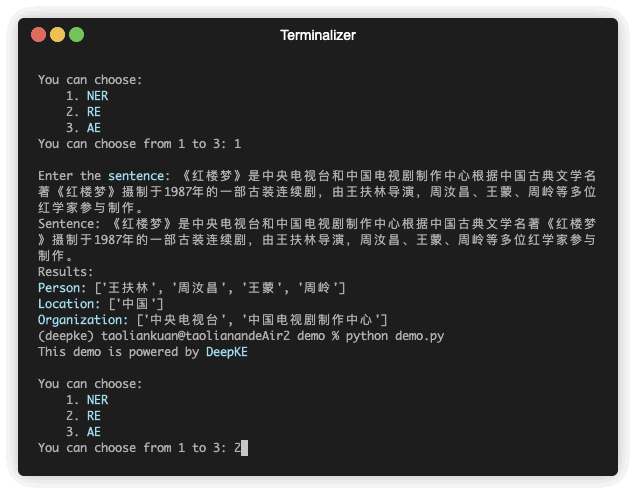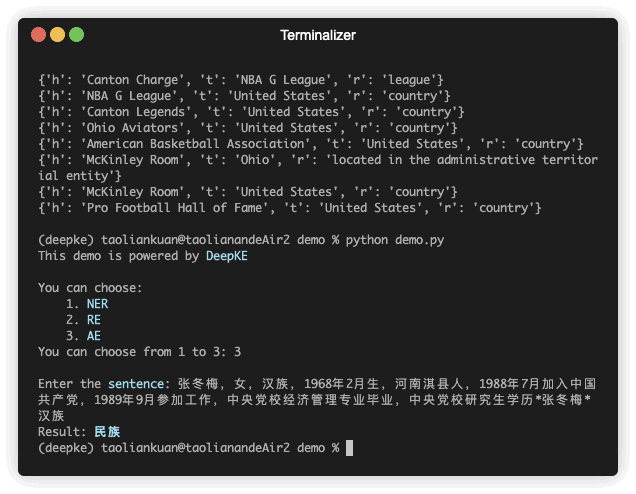
대형 모델 시대에 DeepKE-LLM은 완전히 새로운 환경 종속성을 활용합니다.
conda create -n deepke-llm python=3.9
conda activate deepke-llm
cd example/llm
pip install -r requirements.txt
요구사항 requirements.txt 파일은 example/llm 폴더에 있습니다.
pip install deepke 지원합니다.Step1 기본 코드 다운로드
git clone --depth 1 https://github.com/zjunlp/DeepKE.git Step2 Anaconda 이용하여 가상환경을 생성하고 들어가보세요.
conda create -n deepke python=3.8
conda activate deepke소스 코드로 DeepKE 설치
pip install -r requirements.txt
python setup.py install
python setup.py develop pip 로 DeepKE 설치( 권장하지 않음! )
pip install deepkeStep3 작업 디렉토리를 입력하세요
cd DeepKE/example/re/standard4단계 데이터 세트를 다운로드하거나 주석 지침에 따라 데이터를 얻습니다.
wget 120.27.214.45/Data/re/standard/data.tar.gz
tar -xzvf data.tar.gz다양한 유형의 데이터 형식이 지원되며 자세한 내용은 각 부분에 나와 있습니다.
Step5 훈련(훈련을 위한 매개변수는 conf 폴더에서 변경 가능)
wandb 를 사용하여 시각적 매개변수 조정을 지원합니다.
python run.py Step6 예측(예측을 위한 매개변수는 conf 폴더에서 변경 가능)
predict.yaml 에서 훈련된 모델의 경로를 수정합니다. 모델의 절대 경로를 사용해야 합니다(예: xxx/checkpoints/2019-12-03_ 17-35-30/cnn_ epoch21.pth .
python predict.pyStep1 Docker 클라이언트 설치
Docker를 설치하고 Docker 서비스를 시작합니다.
Step2 도커 이미지를 끌어오고 컨테이너를 실행합니다.
docker pull zjunlp/deepke:latest
docker run -it zjunlp/deepke:latest /bin/bash나머지 단계는 수동 환경 구성 의 3단계 이후와 동일합니다.
파이썬 == 3.8
명명된 엔터티 인식은 구조화되지 않은 텍스트에 언급된 명명된 엔터티를 사람 이름, 조직, 위치, 조직 등과 같은 사전 정의된 범주로 찾고 분류하려고 합니다.
데이터는 .txt 파일에 저장됩니다. 다음과 같은 일부 사례(사용자는 Doccano, MarkTool 도구를 기반으로 데이터에 레이블을 지정하거나 DeepKE와 함께 Weak Supervision을 사용하여 자동으로 데이터를 얻을 수 있습니다):
| 문장 | 사람 | 위치 | 조직 |
|---|---|---|---|
| 本报北京9月4日讯记者杨涌报道:부분분성区人民日报宣传发行工作座谈会9月3日在4日在京举行。 | 杨涌 | 북경 | 인민일报 |
| 《红楼梦》由王扶lin导演, 周汝昌, 王蒙, 周岭等多位专家参与演演. | 王扶lin,周汝昌,王蒙,周岭 | ||
| 秦始皇兵马俑位于陕西省西安市,是世界八大奇迹之一. | 秦始皇 | 陕西省,서안시 |
특정 README에서 자세한 프로세스를 읽어보세요.
표준(완전히 감독됨)
우리는 LLM을 지원하고 교육 없이 cnSchema에서 엔터티를 추출하는 기성 모델인 DeepKE-cnSchema-NER를 제공합니다.
1단계 DeepKE/example/ner/standard 입력하세요. 데이터세트를 다운로드합니다.
wget 120.27.214.45/Data/ner/standard/data.tar.gz
tar -xzvf data.tar.gz Step2 훈련
데이터 세트와 매개변수는 각각 data 폴더와 conf 폴더에서 사용자 정의할 수 있습니다.
python run.pyStep3 예측
python predict.py퓨샷
1단계 DeepKE/example/ner/few-shot 입력하세요. 데이터세트를 다운로드합니다.
wget 120.27.214.45/Data/ner/few_shot/data.tar.gz
tar -xzvf data.tar.gz Step2 저자원 환경에서의 훈련
모델이 로드되고 저장되는 디렉토리와 구성 매개변수는 conf 폴더에서 사용자 정의할 수 있습니다.
python run.py +train=few_shot 사용자는 conf/train/few_shot.yaml 에서 load_path 수정하여 기존 로드된 모델을 사용할 수 있습니다.
3단계 conf/config.yaml 에 - predict 추가하고, 모델 경로로 loda_path 수정하고, conf/predict.yaml 에 예측 결과가 저장되는 경로로 write_path 한 후 python predict.py 실행합니다.
python predict.py멀티모달
1단계 DeepKE/example/ner/multimodal 입력합니다. 데이터세트를 다운로드합니다.
wget 120.27.214.45/Data/ner/multimodal/data.tar.gz
tar -xzvf data.tar.gz원본 이미지의 RCNN 감지 객체와 시각적 접지 객체를 시각적 로컬 정보로 사용합니다. 여기서 RCNN은 fast_rcnn을 통해, 시각적 접지는 onestage_grounding을 통해 수행됩니다.
Step2 다중 모드 설정 훈련
data 폴더와 conf 폴더에서 사용자 정의할 수 있습니다.conf/train.yaml 의 load_path 마지막으로 훈련된 모델이 저장된 경로로 수정합니다. 그리고 훈련 중에 생성된 경로 저장 로그는 log_dir 통해 사용자 정의할 수 있습니다. python run.pyStep3 예측
python predict.py관계 추출은 구조화되지 않은 텍스트에서 엔터티 간의 의미 관계를 추출하는 작업입니다.
데이터는 .csv 파일에 저장됩니다. 다음과 같은 일부 사례(사용자는 Doccano, MarkTool 도구를 기반으로 데이터에 레이블을 지정하거나 DeepKE와 함께 Weak Supervision을 사용하여 자동으로 데이터를 얻을 수 있습니다):
| 문장 | 관계 | 머리 | 헤드_오프셋 | 꼬리 | Tail_offset |
|---|---|---|---|---|---|
| 《岳父也是爹》是王军执导的电视剧,由马恩然、范明主演. | 导演 | 岳父也是爹 | 1 | 王军 | 8 |
| 《九玄珠》是는 纵横中文网连载의 일부 작은 말, 작사자是龙马입니다. | 连载网站 | 九玄珠 | 1 | 纵横中文网 | 7 |
| 提起杭州 的美景,西湖总是第一个映入脑海的词语。 | 所 재시도시 | 西湖 | 8 | 杭州 | 2 |
!참고: 하나의 관계에 여러 엔터티 유형이 있는 경우 엔터티 유형 앞에 관계를 입력으로 붙일 수 있습니다.
특정 README에서 자세한 프로세스를 읽어보세요.
표준(완전히 감독됨)
우리는 LLM을 지원하고 교육 없이 cnSchema에서 관계를 추출하는 기성 모델인 DeepKE-cnSchema-RE를 제공합니다.
1단계 DeepKE/example/re/standard 폴더로 들어갑니다. 데이터세트를 다운로드합니다.
wget 120.27.214.45/Data/re/standard/data.tar.gz
tar -xzvf data.tar.gz Step2 훈련
데이터 세트와 매개변수는 각각 data 폴더와 conf 폴더에서 사용자 정의할 수 있습니다.
python run.pyStep3 예측
python predict.py퓨샷
1단계 DeepKE/example/re/few-shot 입력하세요. 데이터세트를 다운로드합니다.
wget 120.27.214.45/Data/re/few_shot/data.tar.gz
tar -xzvf data.tar.gz 2단계 훈련
data 폴더와 conf 폴더에서 사용자 정의할 수 있습니다.conf/train.yaml 의 train_from_saved_model 마지막으로 훈련된 모델이 저장된 경로로 수정합니다. 그리고 훈련 중에 생성된 경로 저장 로그는 log_dir 통해 사용자 정의할 수 있습니다. python run.pyStep3 예측
python predict.py 문서
1단계 DeepKE/example/re/document 입력하세요. 데이터세트를 다운로드합니다.
wget 120.27.214.45/Data/re/document/data.tar.gz
tar -xzvf data.tar.gz Step2 훈련
data 폴더와 conf 폴더에서 사용자 정의할 수 있습니다.conf/train.yaml 의 train_from_saved_model 마지막으로 훈련된 모델이 저장된 경로로 수정합니다. 그리고 훈련 중에 생성된 경로 저장 로그는 log_dir 통해 사용자 정의할 수 있습니다. python run.pyStep3 예측
python predict.py멀티모달
1단계 DeepKE/example/re/multimodal 입력하세요. 데이터세트를 다운로드합니다.
wget 120.27.214.45/Data/re/multimodal/data.tar.gz
tar -xzvf data.tar.gz원본 이미지의 RCNN 감지 객체와 시각적 접지 객체를 시각적 로컬 정보로 사용합니다. 여기서 RCNN은 fast_rcnn을 통해, 시각적 접지는 onestage_grounding을 통해 수행됩니다.
Step2 훈련
data 폴더와 conf 폴더에서 사용자 정의할 수 있습니다.conf/train.yaml 의 load_path 마지막으로 훈련된 모델이 저장된 경로로 수정합니다. 그리고 훈련 중에 생성된 경로 저장 로그는 log_dir 통해 사용자 정의할 수 있습니다. python run.pyStep3 예측
python predict.py속성 추출은 구조화되지 않은 텍스트에서 엔터티에 대한 속성을 추출하는 것입니다.
데이터는 .csv 파일에 저장됩니다. 다음과 같은 일부 경우:
| 문장 | Att | 엔트 | Ent_offset | 발 | Val_offset |
|---|---|---|---|---|---|
| 张冬梅,女,汉族,1968年2月生,河南淇县人 | 민族 | 张冬梅 | 0 | 汉族 | 6 |
| 诸葛亮,字孔am,三國时期杰会军事家、文schoolfamily、发mingfamily。 | 朝代 | 诸葛亮 | 0 | 삼국지 | 8 |
| 2014년 10월 1일 许鞍华执导的电影 《黄金时代》上映 | 上映时间 | 黄金时代 | 19 | 2014년 10월 1일 | 0 |
특정 README에서 자세한 프로세스를 읽어보세요.
표준(완전히 감독됨)
1단계 DeepKE/example/ae/standard 폴더를 입력하세요. 데이터세트를 다운로드합니다.
wget 120.27.214.45/Data/ae/standard/data.tar.gz
tar -xzvf data.tar.gz Step2 훈련
데이터 세트와 매개변수는 각각 data 폴더와 conf 폴더에서 사용자 정의할 수 있습니다.
python run.pyStep3 예측
python predict.py.tsv 파일에 저장되며 일부 인스턴스는 다음과 같습니다.| 문장 | 이벤트 유형 | 방아쇠 | 역할 | 논쟁 | |
|---|---|---|---|---|---|
| 据 《欧洲时报》报道,当地时间27日,法國巴黎卢浮宫博物馆员工因不满工条件恶化而罢工,导致该博物馆也因此闭门谢客一天. | 组织行为-罢工 | 罢工 | 罢工人员 | 법국巴黎卢浮宫博물馆员工 | |
| 时间 | 当地时间27일 | ||||
| 所属组织 | 법국巴黎卢浮宫博물馆 | ||||
| 중국 야외 2019年上半年归母净利润增长17%:收购了少数股东股权 | 财经/交易-take售/收购 | 收购 | 출력 | 少数股东 | |
| 收购方 | 중국외국어 | ||||
| 交易물 | 股权 | ||||
| 美國亚特兰大航航航13日发生一起表演机坠机事故,飞行员弹射流舱并安全着陆,故事没有造成人员伤亡. | 灾害/의외-坠机 | 坠机 | 时间 | 13일 | |
| 地点 | 미국 특산품 | ||||
특정 README에서 자세한 프로세스를 읽어보세요.
표준(완전히 감독됨)
1단계 DeepKE/example/ee/standard 폴더를 입력하세요. 데이터세트를 다운로드합니다.
wget 120.27.214.45/Data/ee/DuEE.zip
unzip DuEE.zip2단계 훈련
데이터 세트와 매개변수는 각각 data 폴더와 conf 폴더에서 사용자 정의할 수 있습니다.
python run.py3단계 예측
python predict.py 1. Using nearest mirror ( 중국 THU)를 사용하면 Anaconda 설치 속도가 빨라집니다. 중국의 aliyun은 pip install XXX .
2. ModuleNotFoundError: No module named 'past' 가 발생하면 pip install future 실행하세요.
3. 사전 훈련된 언어 모델을 온라인으로 설치하는 것이 느립니다. 사용하기 전에 사전 훈련된 모델을 다운로드하고 pretrained 폴더에 저장하는 것이 좋습니다. 사전 학습된 모델을 저장하기 위한 특정 요구 사항을 확인하려면 모든 작업 디렉터리에서 README.md 읽어보세요.
4. DeepKE 의 이전 버전은 deepke-v1.0 브랜치에 있습니다. 사용자는 이전 버전을 사용하도록 분기를 변경할 수 있습니다. 이전 버전은 표준 관계 추출(예/재/표준)으로 완전히 이전되었습니다.
5.소스 코드를 수정하려면 소스 코드와 함께 DeepKE를 설치하는 것이 좋습니다. 그렇지 않으면 수정이 작동하지 않습니다. 문제 보기
6. 더 많은 관련 저자원 지식 추출 작업은 저자원 시나리오의 지식 추출: 설문 조사 및 관점에서 찾을 수 있습니다.
requirements.txt 에서 요구사항의 정확한 버전을 확인하세요.
다음 버전에서는 더욱 강력한 KE용 LLM을 출시할 계획입니다.
한편, 우리는 버그 수정 , 문제 해결 및 새로운 요청 충족을 위한 장기 유지 관리를 제공할 것입니다. 따라서 문제가 있으면 우리에게 문제를 제기하십시오.
데이터 효율적인 지식 그래프 구축, 高效知识图谱构建(CCKS 2022 튜토리얼) [슬라이드]
효율적이고 강력한 지식 그래프 구축(AACL-IJCNLP 2022 튜토리얼) [슬라이드]
PromptKG Family: 프롬프트 학습 및 KG 관련 연구 작품, 툴킷 및 논문 목록 갤러리 [자료]
저자원 시나리오의 지식 추출: 설문조사 및 관점 [설문조사][논문 목록]
Doccano、MarkTool、LabelStudio: 데이터 주석 툴킷
LambdaKG: PLM 기반 KG 임베딩을 위한 라이브러리 및 벤치마크
EasyInstruct: 대규모 언어 모델을 교육하기 위한 사용하기 쉬운 프레임워크
읽기 자료 :
데이터 효율적인 지식 그래프 구축, 高效知识图谱构建(CCKS 2022 튜토리얼) [슬라이드]
효율적이고 강력한 지식 그래프 구축(AACL-IJCNLP 2022 튜토리얼) [슬라이드]
PromptKG Family: 프롬프트 학습 및 KG 관련 연구 작품, 툴킷 및 논문 목록 갤러리 [자료]
저자원 시나리오의 지식 추출: 설문조사 및 관점 [설문조사][논문 목록]
관련 툴킷 :
Doccano、MarkTool、LabelStudio: 데이터 주석 툴킷
LambdaKG: PLM 기반 KG 임베딩을 위한 라이브러리 및 벤치마크
EasyInstruct: 대규모 언어 모델을 교육하기 위한 사용하기 쉬운 프레임워크
작업에 DeepKE를 사용하는 경우 당사 논문을 인용해 주세요.
@inproceedings { EMNLP2022_Demo_DeepKE ,
author = { Ningyu Zhang and
Xin Xu and
Liankuan Tao and
Haiyang Yu and
Hongbin Ye and
Shuofei Qiao and
Xin Xie and
Xiang Chen and
Zhoubo Li and
Lei Li } ,
editor = { Wanxiang Che and
Ekaterina Shutova } ,
title = { DeepKE: {A} Deep Learning Based Knowledge Extraction Toolkit for Knowledge Base Population } ,
booktitle = { {EMNLP} (Demos) } ,
pages = { 98--108 } ,
publisher = { Association for Computational Linguistics } ,
year = { 2022 } ,
url = { https://aclanthology.org/2022.emnlp-demos.10 }
}Ningyu Zhang, Haofen Wang, Fei Huang, Feiyu Xiong, Liankuan Tao, Xin Xu, Honghao Gui, Zhenru Zhang, Chuanqi Tan, Qiang Chen, Xiaohan Wang, Zekun Xi, Xinrong Li, Haiyang Yu, Hongbin Ye, Shuofei Qiao, Peng Wang , Yuqi Zhu, Xin Xie, Xiang Chen, Zhoubo Li, Lei Li, Xiaozhuan Liang, Yunzhi Yao, Jing Chen, Yuqi Zhu, Shumin Deng, Wen Zhang, Guozhou Zheng, Huajun Chen
커뮤니티 기여자: thredreams, eltociear, Ziwen Xu, Rui Huang, Xiaolong Weng


