ai toolkit
1.0.0
이것은 내 연구 저장소입니다. 나는 그것에 대해 많은 실험을 하고 있으며, 문제가 발생할 가능성이 있습니다. 문제가 발생하면 이전 커밋을 체크아웃하세요. 이 저장소는 많은 것을 훈련할 수 있으며, 그 모든 것을 따라잡기는 어렵습니다.
이 프로젝트에 대한 나의 작업은 Glif와 팀원 모두의 놀라운 지원 없이는 불가능했을 것입니다. 나를 지원하고 싶다면 Glif를 지원하십시오. 사이트에 가입하고, Discord에 가입하고, Twitter에서 우리를 팔로우하고 와서 우리와 함께 멋진 것들을 만들어 보세요.
요구사항:
리눅스:
git clone https://github.com/ostris/ai-toolkit.git
cd ai-toolkit
git submodule update --init --recursive
python3 -m venv venv
source venv/bin/activate
# .venvScriptsactivate on windows
# install torch first
pip3 install torch
pip3 install -r requirements.txt윈도우:
git clone https://github.com/ostris/ai-toolkit.git
cd ai-toolkit
git submodule update --init --recursive
python -m venv venv
. v env S cripts a ctivate
pip install torch torchvision --index-url https://download.pytorch.org/whl/cu121
pip install -r requirements.txt빠르게 시작하려면 24GB VRAM을 갖춘 3090의 Finetuning Flux Dev에 대한 @araminta_k 튜토리얼을 확인하세요.
현재 FLUX.1을 훈련하려면 최소 24GB의 VRAM을 갖춘 GPU가 필요합니다. 모니터를 제어하기 위해 GPU로 사용하는 경우 model: 아래 구성 파일에서 low_vram: true 플래그를 설정해야 할 수 있습니다. 이렇게 하면 CPU에서 모델을 양자화하고 연결된 모니터를 사용하여 훈련할 수 있습니다. 사용자는 WSL을 사용하여 Windows에서 작동하도록 했지만 기본적으로 Windows에서 실행할 때 버그에 대한 보고가 있습니다. 지금은 Linux에서만 테스트했습니다. 이것은 여전히 매우 실험적이며 24GB에 맞도록 많은 양자화와 트릭이 발생해야했습니다.
FLUX.1-dev에는 비상업적 라이센스가 있습니다. 이는 귀하가 훈련하는 모든 것이 비상업적 라이센스를 상속받게 됨을 의미합니다. 또한 게이트형 모델이므로 사용하기 전에 HF에서 라이선스에 동의해야 합니다. 그렇지 않으면 실패합니다. 라이센스를 설정하는 데 필요한 단계는 다음과 같습니다.
.env 라는 파일을 만듭니다.HF_TOKEN=your_key_here 와 같이 .env 파일에 추가하세요.FLUX.1-schnell은 Apache 2.0입니다. 이에 대한 교육을 받은 모든 항목은 원하는 대로 라이선스를 취득할 수 있으며 교육을 위해 HF_TOKEN이 필요하지 않습니다. 그러나 훈련하려면 특수 어댑터인 ostris/FLUX.1-schnell-training-adapter가 필요합니다. 또한 매우 실험적입니다. 최상의 전반적인 품질을 위해서는 FLUX.1-dev에 대한 교육을 권장합니다.
이를 사용하려면 다음과 같이 구성 파일의 model 섹션에 도우미를 추가하면 됩니다.
model :
name_or_path : " black-forest-labs/FLUX.1-schnell "
assistant_lora_path : " ostris/FLUX.1-schnell-training-adapter "
is_flux : true
quantize : trueschnell에는 많은 양의 샘플 단계가 필요하지 않으므로 샘플 단계도 조정해야 합니다.
sample :
guidance_scale : 1 # schnell does not do guidance
sample_steps : 4 # 1 - 4 works wellconfig/examples/train_lora_flux_24gb.yaml (schnell의 경우 config/examples/train_lora_flux_schnell_24gb.yaml )에 있는 예제 구성 파일을 config 폴더에 복사하고 이름을 whatever_you_want.yml 로 바꿉니다.python run.py config/whatever_you_want.yml 과 같이 파일을 실행합니다.시작하면 해당 이름의 폴더와 구성 파일의 교육 폴더가 생성됩니다. 여기에는 모든 체크포인트와 이미지가 포함됩니다. Ctrl+C를 사용하여 언제든지 훈련을 중지할 수 있으며, 다시 시작하면 마지막 체크포인트에서 다시 시작됩니다.
중요한. 저장하는 동안 crtl+c를 누르면 해당 체크포인트가 손상될 가능성이 높습니다. 그러니 저장이 완료될 때까지 기다리세요.
코드의 버그가 아닌 한 버그 보고서를 열지 마십시오. 내 Discord에 가입하여 도움을 요청하실 수 있습니다. 그러나 일반적인 질문이나 지원을 위해 저에게 직접 메시지를 보내는 것은 삼가해 주시기 바랍니다. 불화 속에서 물어보세요. 가능할 때 답변해 드리겠습니다.
사용자 정의 UI를 사용하여 로컬에서 훈련을 시작하려면 위의 단계를 수행하고 ai-toolkit 이 설치된 후:
cd ai-toolkit # in case you are not yet in the ai-toolkit folder
huggingface-cli login # provide a `write` token to publish your LoRA at the end
python flux_train_ui.py 이미지를 업로드하고, 캡션을 추가하고, LoRA를 학습 및 게시할 수 있는 UI를 인스턴스화합니다. 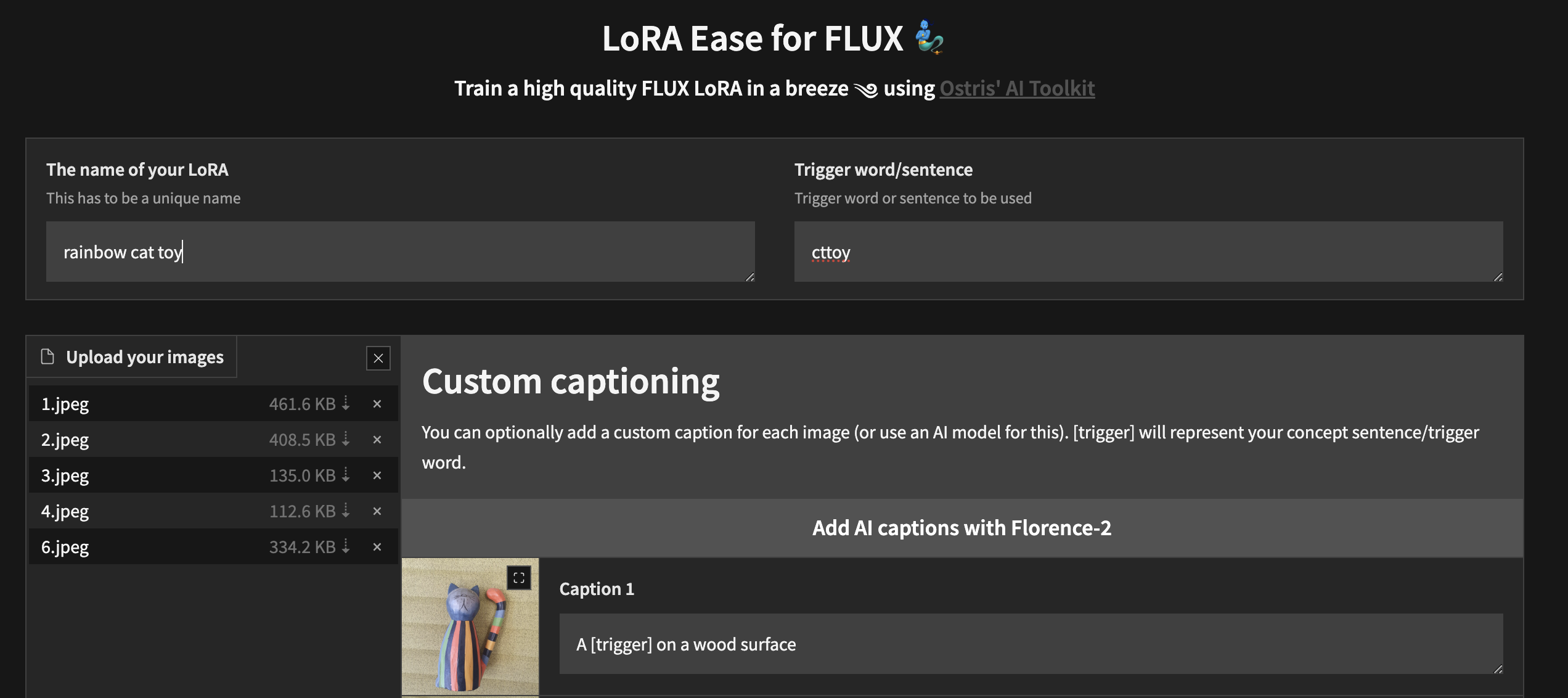
RunPod 템플릿 예: runpod/pytorch:2.2.0-py3.10-cuda12.1.1-devel-ubuntu22.04
최소 24GB VRAM이 필요하며 원하는 대로 GPU를 선택하세요.
git clone https://github.com/ostris/ai-toolkit.git
cd ai-toolkit
git submodule update --init --recursive
python -m venv venv
source venv/bin/activate
pip install torch
pip install -r requirements.txt
pip install --upgrade accelerate transformers diffusers huggingface_hub #Optional, run it if you run into issues
dataset 또는 원하는 대로 지정합니다.huggingface-cli login 실행하고 토큰을 붙여넣습니다.config/examples 에 있는 예제 구성 파일을 config 폴더에 복사하고 이름을 whatever_you_want.yml 로 바꿉니다.folder_path: "/path/to/images/folder" folder_path: "/workspace/ai-toolkit/your-dataset" 와 같은 데이터 세트 경로로 변경합니다.python run.py config/whatever_you_want.yml .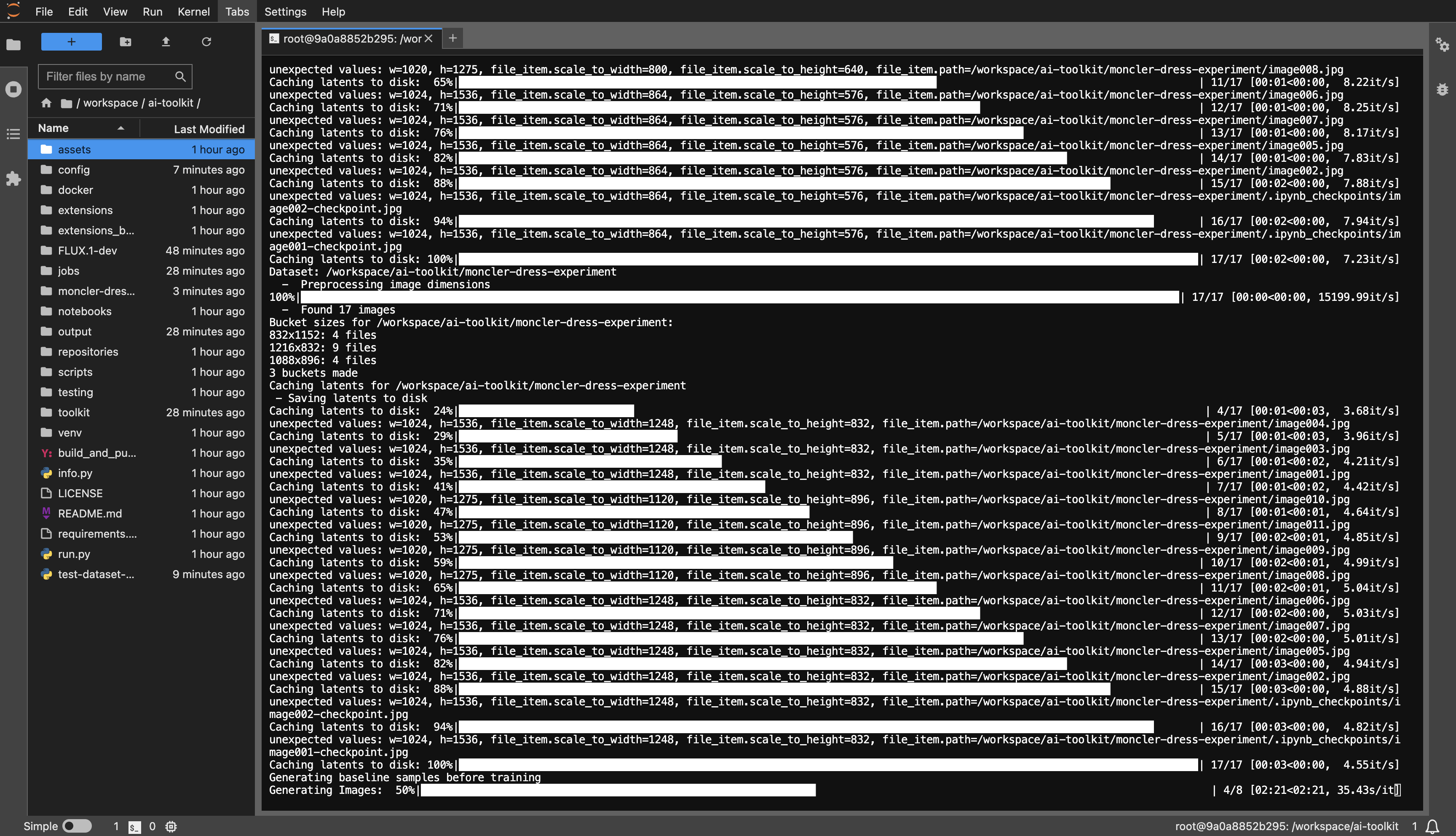
git clone https://github.com/ostris/ai-toolkit.git
cd ai-toolkit
git submodule update --init --recursive
python -m venv venv
source venv/bin/activate
pip install torch
pip install -r requirements.txt
pip install --upgrade accelerate transformers diffusers huggingface_hub #Optional, run it if you run into issues
pip install modal 실행하여 모달 Python 패키지를 설치합니다.modal setup 실행하여 인증합니다(이 방법이 작동하지 않으면 python -m modal setup 시도). huggingface-cli login 실행하고 토큰을 붙여넣습니다.ai-toolkit 에 드래그 앤 드롭하세요.config/examples/modal 에 있는 예제 구성 파일을 config 폴더에 복사하고 이름을 whatever_you_want.yml 로 바꿉니다./root/ai-toolkit paths 예제를 따르십시오 . code_mount = modal.Mount.from_local_dir 에서 전체 로컬 ai-toolkit 경로를 다음과 같이 설정하세요.
code_mount = modal.Mount.from_local_dir("/Users/username/ai-toolkit", remote_path="/root/ai-toolkit")
@app.function 에서 GPU 및 Timeout 선택합니다 (기본값은 A100 40GB 및 2시간 시간 초과) .
modal run run_modal.py --config-file-list-str=/root/ai-toolkit/config/whatever_you_want.yml .Storage > flux-lora-models 에 저장됩니다.modal volume ls flux-lora-models 실행하여 볼륨의 내용을 확인하세요.modal volume get flux-lora-models your-model-name 실행하여 콘텐츠를 다운로드합니다.modal volume get flux-lora-models my_first_flux_lora_v1 .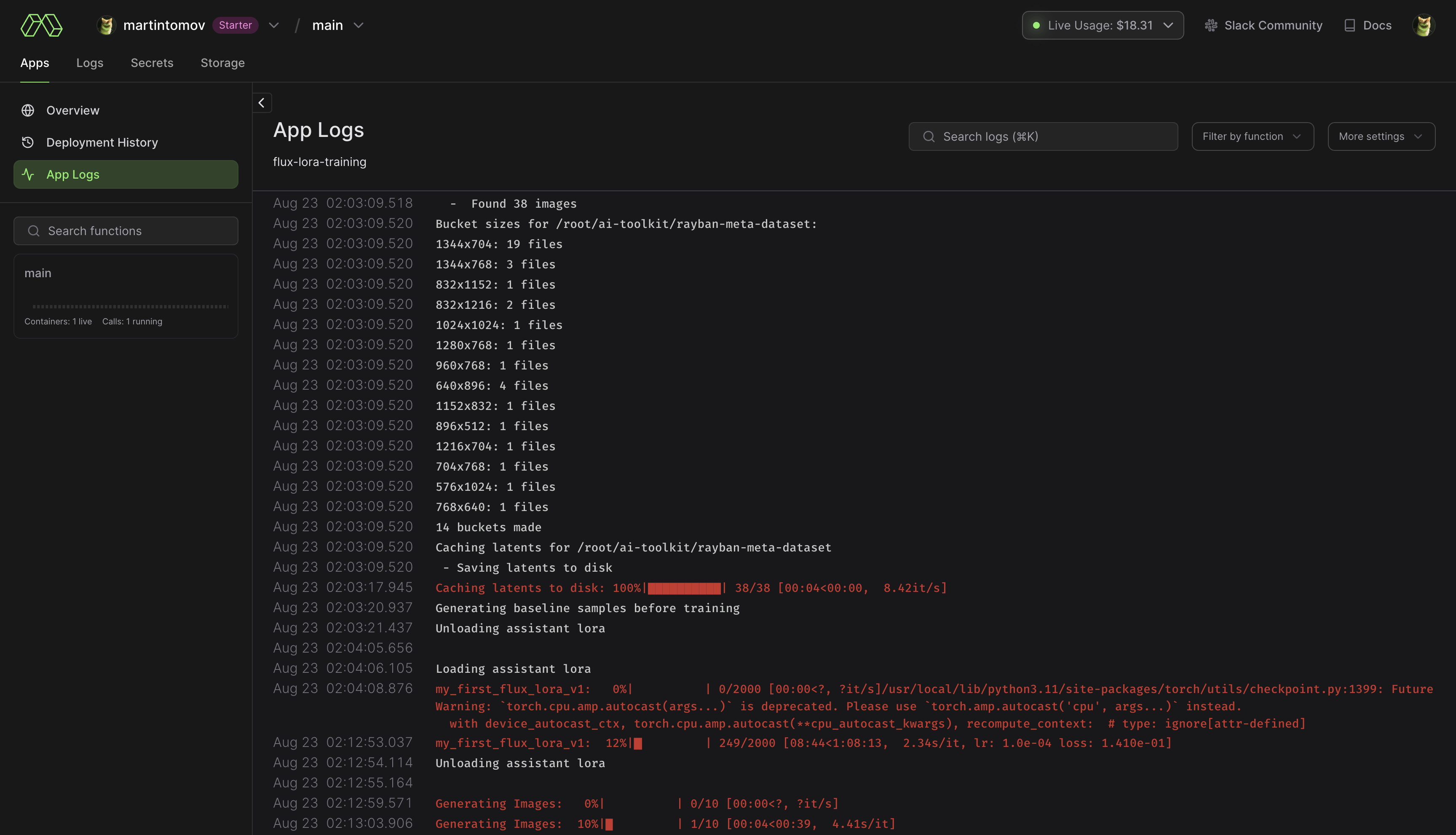
데이터세트는 일반적으로 이미지와 관련 텍스트 파일이 포함된 폴더여야 합니다. 현재 지원되는 형식은 jpg, jpeg, png뿐입니다. Webp에는 현재 문제가 있습니다. 텍스트 파일의 이름은 이미지와 동일해야 하지만 확장자는 .txt 여야 합니다. 예를 들어 image2.jpg 및 image2.txt 입니다. 텍스트 파일에는 캡션만 포함되어야 합니다. 캡션 파일에 [trigger] 단어를 추가할 수 있으며 구성에 trigger_word 있으면 자동으로 대체됩니다.
이미지는 절대 확대되지 않지만 축소되어 일괄 처리를 위해 버킷에 배치됩니다. 이미지를 자르거나 크기를 조정할 필요가 없습니다 . 로더는 자동으로 크기를 조정하고 다양한 종횡비를 처리할 수 있습니다.
LoRA로 특정 레이어를 훈련하려면 only_if_contains 네트워크 kwargs를 사용할 수 있습니다. 예를 들어, 이 게시물에서 언급한 The Last Ben에서 사용하는 2개의 레이어만 훈련하려는 경우 다음과 같이 네트워크 kwargs를 조정할 수 있습니다.
network :
type : " lora "
linear : 128
linear_alpha : 128
network_kwargs :
only_if_contains :
- " transformer.single_transformer_blocks.7.proj_out "
- " transformer.single_transformer_blocks.20.proj_out " 레이어의 명명 규칙은 디퓨저 형식이므로 모델의 상태 딕셔너리를 확인하면 훈련하려는 레이어 이름의 접미사가 드러납니다. 또한 이 방법을 사용하여 특정 가중치 그룹만 훈련할 수도 있습니다. 예를 들어 FLUX.1에 대한 single_transformer 만 교육하려면 다음을 사용할 수 있습니다.
network :
type : " lora "
linear : 128
linear_alpha : 128
network_kwargs :
only_if_contains :
- " transformer.single_transformer_blocks. " ignore_if_contains network kwarg를 사용하여 이름별로 레이어를 제외할 수도 있습니다. 따라서 모든 단일 변압기 블록을 제외하려면,
network :
type : " lora "
linear : 128
linear_alpha : 128
network_kwargs :
ignore_if_contains :
- " transformer.single_transformer_blocks. " ignore_if_contains only_if_contains 보다 우선순위가 높습니다. 따라서 가중치가 두 가지 모두에 적용되는 경우 무시됩니다.
여전히 그렇게 작동할 수도 있지만 한동안 테스트해 보지 않았습니다.
구성 파일에서 pts를 가져오거나 txt 파일을 형성하여 폴더에 생성할 수 있는 이미지 생성기입니다. 주로 내가 수행 중인 SDXL 테스트에 필요했지만 배치 이미지 생성 생성에 사용할 수 있도록 약간의 광택을 추가했습니다. 이 모든 작업은 구성 파일에서 실행됩니다. 해당 예는 config/examples/generate.example.yaml 에서 찾을 수 있습니다. 간단한 정보는 예제의 주석에 있습니다.
LyCORIS 도구의 추출기를 기반으로 하지만 일부 QOL 기능과 LoRA(lierla) 지원이 추가되었습니다. 한 번의 실행으로 여러 유형의 추출을 수행할 수 있습니다. 이 모든 작업은 구성 파일에서 실행되며, config/examples/extract.example.yml 에서 해당 예를 찾을 수 있습니다. 해당 파일을 config 폴더에 복사하고 이름을 whatever_you_want.yml 로 바꾸세요. 그런 다음 원하는 대로 파일을 편집할 수 있습니다. 다음과 같이 호출하세요.
python3 run.py config/whatever_you_want.yml다른 곳에 보관하려는 경우 구성 파일의 전체 경로를 입력할 수도 있습니다.
python3 run.py " /home/user/whatever_you_want.yml "작동 방식에 대한 자세한 내용은 예제 구성 파일 자체에서 확인할 수 있습니다. LoRA와 LoCON은 모두 '고정', '임계값', '비율', '분위수' 추출을 지원합니다. 나중에 이것이 무엇을 의미하는지 업데이트하겠습니다. 대부분의 사람들은 전통적인 고정 차원 추출인 고정을 사용했습니다.
process 실행할 다양한 프로세스의 배열입니다. 몇 가지를 추가하고 믹스 앤 매치할 수 있습니다. LoRA 1개, LyCON 1개 등
<lora:my_lora:4.6> <lora:my_lora:1.0> 으로 변경하거나 동일한 효과를 원하는 대로 변경하세요. LoRA의 가중치를 재조정하는 도구입니다. LoCON에도 적용해야 하지만 테스트하지는 않았습니다. 이 모든 작업은 구성 파일에서 실행됩니다. 해당 예는 config/examples/mod_lora_scale.yml 에서 찾을 수 있습니다. 해당 파일을 config 폴더에 복사하고 이름을 whatever_you_want.yml 로 바꾸세요. 그런 다음 원하는 대로 파일을 편집할 수 있습니다. 다음과 같이 호출하세요.
python3 run.py config/whatever_you_want.yml다른 곳에 보관하려는 경우 구성 파일의 전체 경로를 입력할 수도 있습니다.
python3 run.py " /home/user/whatever_you_want.yml "작동 방식에 대한 자세한 내용은 예제 구성 파일 자체에서 확인할 수 있습니다. 이상적인 무게가 1.0인 경우는 거의 없으므로 모든 LoRA를 만들 때 유용하지만 이제 이를 수정할 수 있습니다. 슬라이더의 경우 -2에서 2 또는 -15에서 15까지의 이상한 스케일을 가질 수 있습니다. 이렇게 하면 모두 원하는 스케일을 갖도록 조정할 수 있습니다.
이것이 제가 Civitai에서 사용하는 대부분의 슬라이더를 훈련하는 방법입니다. 내 Civitai 프로필에서 확인할 수 있습니다. 이는 p1atdev/LECO 및 rohitgandikota/erasing의 작업을 기반으로 하지만 개념을 지우는 대신 슬라이더를 생성하도록 크게 수정되었습니다. 이에 대해 더 많은 계획이 있지만 현재로서는 매우 기능적입니다. 또한 사용하기가 매우 쉽습니다. config/examples/train_slider.example.yml 의 예제 구성 파일을 config 폴더에 복사하고 이름을 whatever_you_want.yml 로 바꾸세요. 그런 다음 원하는 대로 파일을 편집할 수 있습니다. 다음과 같이 호출하세요.
python3 run.py config/whatever_you_want.yml해당 예제 파일에는 더 많은 정보가 있습니다. 예제를 수정하지 않고 있는 그대로 실행하여 어떻게 작동하는지 확인할 수도 있습니다. 모든 동물을 개(neg) 또는 고양이(pos)로 바꾸는 슬라이더를 생성합니다. 다음과 같이 실행해 보세요.
python3 run.py config/examples/train_slider.example.yml그리고 아무것도 구성하지 않고도 어떻게 작동하는지 확인할 수 있습니다. 이 방법에는 데이터세트가 필요하지 않습니다. 곧 더 나은 튜토리얼을 게시하겠습니다.
이제 사용자 정의 확장을 만들고 공유할 수 있습니다. 이는 이 프레임워크 내에서 실행되며 모든 내장 도구를 사용할 수 있습니다. 나는 아마도 이것을 앞으로 기본 개발 방법으로 사용할 것이므로 이 기본 저장소에 계속해서 더 많은 기능을 추가하고 추가하지 않을 것입니다. 모든 것을 모듈화하기 위해 기존 기능도 많이 마이그레이션할 것입니다. 모델 병합 확장을 만드는 방법을 보여주는 extensions 폴더에 예제 확장이 있습니다. 모든 코드는 문서화되어 있어 시작하기에 충분할 것입니다. 확장을 만들려면 해당 예제를 복사하고 필요한 모든 항목을 바꾸십시오.
extensions 폴더에 있습니다. 원하는 만큼 많은 모델을 병합할 수 있는 완전한 기능의 모델 병합입니다. 이는 확장을 만드는 방법에 대한 좋은 예이지만 대부분의 합병은 한 번에 하나의 모델만 수행할 수 있고 이 모델은 원하는 만큼 많은 모델을 사용할 수 있기 때문에 매우 유용한 기능이기도 합니다. 거기에 예시 구성 파일이 있습니다. 이를 config 폴더에 복사하고 이름을 whatever_you_want.yml 로 바꾸세요. 다른 구성 파일처럼 사용하세요.
이것은 작동하지만 다른 사람이 사용할 준비가 되어 있지 않으므로 예제 구성이 없습니다. 나는 아직도 그것에 대해 노력하고 있습니다. 준비되면 업데이트하겠습니다. 이미지 확대 작업에 사용했던 기준에 따라 많은 기능을 추가하고 있습니다. 비평가(판별자), 콘텐츠 손실, 스타일 손실 등이 있습니다. 모르는 경우 안정적인 확산을 위한 VAE(예, MSE 및 SDXL도 마찬가지)는 작은 얼굴에서는 끔찍하며 SD를 방해합니다. 이 문제를 해결하겠습니다. 나중에 더 나은 예제와 함께 이에 대해 더 자세히 게시할 예정이지만 여기에는 다양한 VAE를 사용한 빠른 실행 테스트가 있습니다. 그냥 들어갔다가 나왔어요. 여기에 표시된 것보다 작은 얼굴에서는 훨씬 더 나쁩니다.
extensions 폴더의 예를 확인하세요. 위에서 이에 대해 자세히 읽어보세요.SD를 더욱 모듈화하기 위한 또 다른 대규모 리팩터링입니다.
배치 이미지 생성 스크립트 작성
주요 변경 사항 및 업데이트. 새로운 LoRA 크기 조정 도구, 자세한 내용은 위에서 확인하세요. 자동1111이 기본 모델이 무엇인지 알 수 있도록 더 나은 메타데이터를 추가했습니다. 몇 가지 실험과 수많은 업데이트가 추가되었습니다. 아직은 불안정한 상태이므로 큰 변화가 없기를 바랍니다.
불행하게도 모든 변경 사항이 포함된 적절한 변경 로그를 작성하기에는 너무 게으른 편입니다.
슬라이더에 SDXL 트레이닝을 추가했는데.. 제대로 작동하지 않습니다. 슬라이더 훈련은 무조건적(부정적 프롬프트)이 출력에 해당 개념을 원하지 않는다는 것을 의미한다는 것을 이해하는 모델의 능력에 의존합니다. SDXL은 어떤 이유로든 이를 이해하지 못하므로 모델 내에서 개념을 분리하기가 어렵습니다. 시간이 지남에 따라 커뮤니티에서 이 문제를 해결할 수 있는 방법을 찾을 것이라고 확신하지만 현재로서는 제대로 작동하지 않을 것입니다. "모델에 텍스트 인코더를 1~2개 더 추가하고 완전히 분리된 확산 네트워크를 몇 개 더 추가하면 문제를 해결할 수 있지 않을까?"라고 생각하시는 분이 계시다면? 아뇨. 안돼요. 실험적인 새 논문을 추가하지 않고도 약간의 훈련만 필요합니다. KISS 교장.
슬라이더 트레이너에 "앵커"를 추가했습니다. 이를 통해 정규화 도구로 사용될 프롬프트를 설정할 수 있습니다. 높은 가중치에서 분산 일관성을 강제하도록 네트워크 승수를 설정할 수 있습니다.


