ffhq dataset
1.0.0

Flickr-Faces-HQ(FFHQ)는 원래 GAN(Generative Adversarial Network)의 벤치마크로 만들어진 인간 얼굴의 고품질 이미지 데이터 세트입니다.
생성적 적대 신경망을 위한 스타일 기반 생성기 아키텍처
Tero Karras(NVIDIA), Samuli Laine(NVIDIA), Timo Aila(NVIDIA)
https://arxiv.org/abs/1812.04948
데이터 세트는 1024×1024 해상도의 70,000개의 고품질 PNG 이미지로 구성되어 있으며 연령, 민족 및 이미지 배경 측면에서 상당한 변화가 포함되어 있습니다. 또한 안경, 선글라스, 모자 등과 같은 액세서리에 대한 적용 범위도 좋습니다. 이미지는 Flickr에서 크롤링되어 해당 웹 사이트의 모든 편견을 상속하고 dlib를 사용하여 자동으로 정렬되고 잘립니다. 허용 라이센스가 있는 이미지만 수집되었습니다. 다양한 자동 필터를 사용하여 세트를 정리하고 마지막으로 Amazon Mechanical Turk를 사용하여 가끔 조각상, 그림 또는 사진 사진을 제거했습니다.
이 데이터 세트는 얼굴 인식 기술의 개발 또는 개선을 위한 것이 아니며 사용되어서도 안 됩니다. 비즈니스 문의 사항이 있는 경우 당사 웹사이트를 방문하여 NVIDIA 연구 라이선스 양식을 제출해 주세요.
개별 이미지는 Creative Commons BY 2.0, Creative Commons BY-NC 2.0, Public Domain Mark 1.0, Public Domain CC0 1.0 또는 US Government Works 라이센스에 따라 각 작성자가 Flickr에 게시했습니다. 이러한 모든 라이센스는 비상업적 목적으로 무료 사용, 재배포 및 개작을 허용합니다. 그러나 그 중 일부는 원본 작성자에게 적절한 출처를 표시하고 이미지에 적용된 변경 사항을 표시하도록 요구합니다. 각 이미지의 라이선스와 원저작자는 메타데이터에 표시됩니다.
데이터 세트 자체(JSON 메타데이터, 다운로드 스크립트 및 문서 포함)는 NVIDIA Corporation의 Creative Commons BY-NC-SA 4.0 라이선스에 따라 제공됩니다. (a) 우리 논문을 인용 하여 적절한 출처를 표시하고, (b) 변경 사항을 표시하고 , (c) 파생 저작물을 배포하는 한, 비상업적 목적으로 사용, 재배포 및 개작 할 수 있습니다. 동일한 라이센스하에 .
모든 데이터는 Google 드라이브에서 호스팅됩니다.
| 길 | 크기 | 파일 | 체재 | 설명 |
|---|---|---|---|---|
| ffhq-데이터세트 | 2.56TB | 210,014 | 메인 폴더 | |
| ├ ffhq-dataset-v2.json | 255MB | 1 | JSON | 저작권 정보, URL 등을 포함한 메타데이터 |
| ├ 이미지1024x1024 | 89.1GB | 70,000 | PNG | 1024×1024로 정렬되고 잘린 이미지 |
| ├ 썸네일128x128 | 1.95GB | 70,000 | PNG | 128×128의 썸네일 |
| ├ 야생 이미지 | 955GB | 70,000 | PNG | Flickr의 원본 이미지 |
| ├ 티레코드 | 273GB | 9 | tfrecords | StyleGAN 및 StyleGAN2의 다중 해상도 데이터 |
| └ 지퍼 | 1.28TB | 4 | 지퍼 | ZIP 아카이브로 각 폴더의 콘텐츠. |
상위 수준 통계:
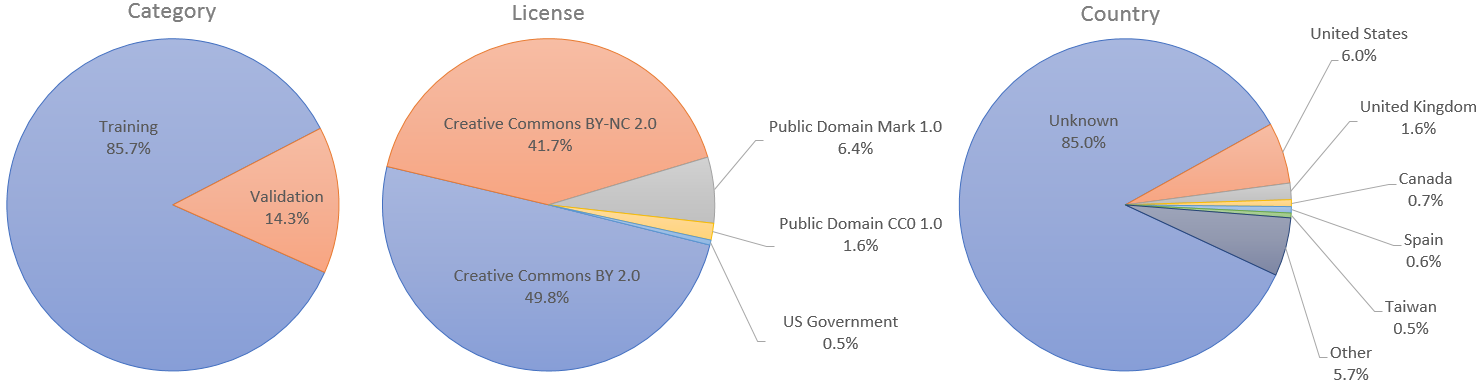
별도의 훈련 및 검증 세트가 필요한 사용 사례의 경우 처음 60,000개의 이미지를 훈련에 사용하고 나머지 10,000개는 검증에 사용하도록 지정했습니다. 그러나 StyleGAN 논문에서는 70,000개의 이미지를 모두 훈련에 사용했습니다.
데이터 세트 자체에 중복된 이미지가 없는지 명시적으로 확인했습니다. 그러나 동일한 이미지에서 여러 다른 얼굴을 추출한 경우 in-the-wild 폴더에 동일한 이미지의 여러 복사본이 포함될 수 있습니다.
Google Drive에서 직접 데이터를 가져오거나 제공된 다운로드 스크립트를 사용할 수 있습니다. 스크립트는 요청된 모든 파일을 자동으로 다운로드하고, 체크섬을 확인하고, 오류가 발생한 경우 각 파일을 여러 번 재시도하고, 여러 동시 연결을 사용하여 대역폭을 최대화함으로써 작업을 훨씬 쉽게 만듭니다.
> python download_ffhq.py -h
usage: download_ffhq.py [-h] [-j] [-s] [-i] [-t] [-w] [-r] [-a]
[--num_threads NUM] [--status_delay SEC]
[--timing_window LEN] [--chunk_size KB]
[--num_attempts NUM]
Download Flickr-Face-HQ (FFHQ) dataset to current working directory.
optional arguments:
-h, --help show this help message and exit
-j, --json download metadata as JSON (254 MB)
-s, --stats print statistics about the dataset
-i, --images download 1024x1024 images as PNG (89.1 GB)
-t, --thumbs download 128x128 thumbnails as PNG (1.95 GB)
-w, --wilds download in-the-wild images as PNG (955 GB)
-r, --tfrecords download multi-resolution TFRecords (273 GB)
-a, --align recreate 1024x1024 images from in-the-wild images
--num_threads NUM number of concurrent download threads (default: 32)
--status_delay SEC time between download status prints (default: 0.2)
--timing_window LEN samples for estimating download eta (default: 50)
--chunk_size KB chunk size for each download thread (default: 128)
--num_attempts NUM number of download attempts per file (default: 10)
--random-shift SHIFT standard deviation of random crop rectangle jitter
--retry-crops retry random shift if crop rectangle falls outside image (up to 1000
times)
--no-rotation keep the original orientation of images
--no-padding do not apply blur-padding outside and near the image borders
--source-dir DIR where to find already downloaded FFHQ source data
> python ..download_ffhq.py --json --images
Downloading JSON metadata...
100.00% done 2/2 files 0.25/0.25 GB 43.21 MB/s ETA: done
Parsing JSON metadata...
Downloading 70000 files...
| 100.00% done 70001/70001 files 89.19 GB/89.19 GB 59.87 MB/s ETA: done
이 스크립트는 또한 이미지를 정렬하고 자르는 데 사용한 자동화된 구성표의 참조 구현 역할도 합니다. python download_ffhq.py --wilds 사용하여 실제 이미지를 다운로드한 후에는 python download_ffhq.py --align 실행하여 메타데이터에 포함된 얼굴 랜드마크 위치를 사용하여 정렬된 1024×1024 이미지의 정확한 복제본을 재현할 수 있습니다. .
Alias-Free Generative Adversarial Networks 논문에 사용된 "정렬되지 않은 FFHQ" 데이터 세트를 재현하려면 다음 옵션을 사용하십시오.
python download_ffhq.py
--source-dir <path/to/downloaded/ffhq>
--align --no-rotation --random-shift 0.2 --no-padding --retry-crops
ffhq-dataset-v2.json 파일에는 각 이미지에 대한 다음 정보가 기계가 읽을 수 있는 형식으로 포함되어 있습니다.
{
"0": { # Image index
"category": "training", # Training or validation
"metadata": { # Info about the original Flickr photo:
"photo_url": "https://www.flickr.com/photos/...", # - Flickr URL
"photo_title": "DSCF0899.JPG", # - File name
"author": "Jeremy Frumkin", # - Author
"country": "", # - Country where the photo was taken
"license": "Attribution-NonCommercial License", # - License name
"license_url": "https://creativecommons.org/...", # - License detail URL
"date_uploaded": "2007-08-16", # - Date when the photo was uploaded to Flickr
"date_crawled": "2018-10-10" # - Date when the photo was crawled from Flickr
},
"image": { # Info about the aligned 1024x1024 image:
"file_url": "https://drive.google.com/...", # - Google Drive URL
"file_path": "images1024x1024/00000/00000.png", # - Google Drive path
"file_size": 1488194, # - Size of the PNG file in bytes
"file_md5": "ddeaeea6ce59569643715759d537fd1b", # - MD5 checksum of the PNG file
"pixel_size": [1024, 1024], # - Image dimensions
"pixel_md5": "47238b44dfb87644460cbdcc4607e289", # - MD5 checksum of the raw pixel data
"face_landmarks": [...] # - 68 face landmarks reported by dlib
},
"thumbnail": { # Info about the 128x128 thumbnail:
"file_url": "https://drive.google.com/...", # - Google Drive URL
"file_path": "thumbnails128x128/00000/00000.png", # - Google Drive path
"file_size": 29050, # - Size of the PNG file in bytes
"file_md5": "bd3e40b2ba20f76b55dc282907b89cd1", # - MD5 checksum of the PNG file
"pixel_size": [128, 128], # - Image dimensions
"pixel_md5": "38d7e93eb9a796d0e65f8c64de8ba161" # - MD5 checksum of the raw pixel data
},
"in_the_wild": { # Info about the in-the-wild image:
"file_url": "https://drive.google.com/...", # - Google Drive URL
"file_path": "in-the-wild-images/00000/00000.png", # - Google Drive path
"file_size": 3991569, # - Size of the PNG file in bytes
"file_md5": "1dc0287e73e485efb0516a80ce9d42b4", # - MD5 checksum of the PNG file
"pixel_size": [2016, 1512], # - Image dimensions
"pixel_md5": "86b3470c42e33235d76b979161fb2327", # - MD5 checksum of the raw pixel data
"face_rect": [667, 410, 1438, 1181], # - Axis-aligned rectangle of the face region
"face_landmarks": [...], # - 68 face landmarks reported by dlib
"face_quad": [...] # - Aligned quad of the face region
}
},
...
}
심도 있는 토론과 유용한 의견을 주신 Jaakko Lehtinen, David Luebke, Tuomas Kynkäänniemi에게 감사드립니다. 컴퓨팅 인프라와 코드 릴리스에 대한 도움을 주신 Janne Hellsten, Tero Kuosmanen 및 Pekka Jänis.
또한 처음에 데이터를 수집할 수 있도록 자동 얼굴 감지 및 정렬 작업을 수행한 Vahid Kazemi와 Josephine Sullivan에게 감사드립니다.
회귀 트리 앙상블을 사용한 1밀리초 얼굴 정렬
바히드 카제미, 조세핀 설리반
진행 CVPR 2014
https://www.cv-foundation.org/openaccess/content_cvpr_2014/papers/Kazemi_One_Millisecond_Face_2014_CVPR_paper.pdf
데이터를 수집할 때, 우리가 아는 한, 해당 작가가 무료로 사용하고 재배포할 수 있는 사진만 포함하도록 주의했습니다. 즉, 우리는 자신의 사진이 포함되는 것을 원하지 않는 개인의 개인정보를 보호하기 위해 최선을 다하고 있습니다.
귀하의 사진이 Flickr-Faces-HQ 데이터 세트에 포함되어 있는지 확인하려면 이 링크를 클릭하여 Flickr 사용자 이름으로 데이터 세트를 검색하십시오.
Flickr-Faces-HQ 데이터 세트에서 사진을 제거하려면:
no_cv 태그를 지정하여 컴퓨터 비전 연구에 사용되는 것을 원하지 않음을 나타냅니다.None (모든 권리 보유) 또는 NoDerivs 가 포함된 크리에이티브 커먼즈 라이센스로 변경하여 사진이 재배포되는 것을 원하지 않음을 나타냅니다.

