Machine Learning Guide
1.0.0
참고: 이 편리한 확장 Markdown PDF를 사용하면 VSCode에서 이 마크다운 파일을 PDF로 쉽게 변환할 수 있습니다.

기계 학습/딥 러닝 프레임워크.
ML을 위한 학습 리소스
ML 프레임워크, 라이브러리 및 도구
알고리즘
PyTorch 개발
TensorFlow 개발
핵심 ML 개발
딥러닝 개발
강화 학습 개발
컴퓨터 비전 개발
자연어 처리(NLP) 개발
생물정보학
CUDA 개발
MATLAB 개발
C/C++ 개발
자바 개발
파이썬 개발
스칼라 개발
R 개발
줄리아 개발
맨 위로 돌아가기
머신 러닝은 프로그래밍할 필요 없이 데이터 모델에서 학습하고 시간이 지남에 따라 정확성을 향상시키는 알고리즘을 사용하여 앱을 구축하는 데 중점을 둔 인공 지능(AI)의 한 분야입니다.

맨 위로 돌아가기
Microsoft의 자연어 처리(NLP) 모범 사례
Microsoft의 자율주행 요리책
Azure 기계 학습 - 서비스로서의 ML | 마이크로소프트 애저
Azure Machine Learning 작업 영역에서 Jupyter Notebook을 실행하는 방법
기계 학습 및 인공 지능 | 아마존 웹 서비스
Amazon SageMaker 임시 인스턴스에서 Jupyter 노트북 예약
AI 및 머신러닝 | 구글 클라우드
Google Cloud에서 Apache Spark와 함께 Jupyter Notebook 사용
머신러닝 | 애플 개발자
인공 지능 및 자동 조종 장치 | 테슬라
메타 AI 도구 | 페이스북
PyTorch 튜토리얼
TensorFlow 튜토리얼
JupyterLab
Apple Silicon 기반 Core ML을 통한 안정적인 확산
맨 위로 돌아가기
Andrew Ng의 스탠포드 대학교 기계 학습 | 코세라
기계 학습(ML) 과정에 대한 AWS 교육 및 인증
Microsoft Azure용 기계 학습 장학금 프로그램 | 유다시티
Microsoft 인증: Azure 데이터 과학자 준회원
Microsoft 인증: Azure AI 엔지니어 어소시에이트
Azure Machine Learning 교육 및 배포
Google Cloud 교육을 통해 머신러닝 및 인공지능 학습
Google Cloud 머신러닝 단기집중과정
온라인 머신러닝 강좌 | 유데미
온라인 머신러닝 강좌 | 코세라
온라인 강좌 및 수업을 통해 기계 학습 배우기 | edX
맨 위로 돌아가기
기계 학습 소개(PDF)
인공 지능: 현대적인 접근 방식 - Stuart J. Russel 및 Peter Norvig
Ian Goodfellow, Yoshoua Bengio 및 Aaron Courville의 딥 러닝
Andriy Burkov가 쓴 백 페이지짜리 기계 학습 책
Tom M. Mitchell의 기계 학습
집단지성 프로그래밍: 스마트 웹 2.0 애플리케이션 구축 - Toby Segaran
기계 학습: 알고리즘 관점, 제2판
패턴 인식 및 기계 학습 - Christopher M. Bishop
Python을 사용한 자연어 처리 - Steven Bird, Ewan Klein 및 Edward Loper
Python 기계 학습: 초보자를 위한 기계 학습에 대한 기술적 접근 방식 작성자: Leonard Eddison
베이지안 추론과 기계 학습 - David Barber
완전 초보자를 위한 기계 학습: Oliver Theobald의 쉬운 영어 소개
Ben Wilson의 실제 머신 러닝
Scikit-Learn, Keras 및 TensorFlow를 사용한 실습 기계 학습: 지능형 시스템 구축을 위한 개념, 도구 및 기술 작성자: Aurélien Géron
Python을 사용한 기계 학습 소개: Andreas C. Müller 및 Sarah Guido의 데이터 과학자를 위한 가이드
해커를 위한 기계 학습: Drew Conway 및 John Myles White가 시작하는 데 도움이 되는 사례 연구 및 알고리즘
통계 학습의 요소: 데이터 마이닝, 추론 및 예측 - Trevor Hastie, Robert Tibshirani 및 Jerome Friedman
분산 기계 학습 패턴 - 도서(온라인에서 무료로 읽을 수 있음) + 코드
실제 기계 학습 [무료 장]
통계 학습 소개 - 책 + R 코드
통계 학습의 요소 - 도서
Think Bayes - 책 + Python 코드
대규모 데이터세트 마이닝
머신러닝과의 첫 만남
기계 학습 소개 - Alex Smola 및 SVN Vishwanathan
패턴 인식의 확률론적 이론
정보 검색 소개
예측: 원칙과 실천
기계 학습 소개 - Amnon Shashua
강화 학습
기계 학습
AI에 대한 탐구
데이터 과학을 위한 R 프로그래밍
데이터 마이닝 - 실용적인 기계 학습 도구 및 기술
TensorFlow를 사용한 머신러닝
기계 학습 시스템
기계 학습의 기초 - Mehryar Mohri, Afshin Rostamizadeh 및 Ameet Talwalkar
AI 기반 검색 - Trey Grainger, Doug Turnbull, Max Irwin -
기계 학습을 위한 앙상블 방법 - Gautam Kunapuli
실제 머신러닝 엔지니어링 - Ben Wilson
개인 정보 보호 기계 학습 - J. Morris Chang, Di Zhuang, G. Dumindu Samaraweera
자동화된 기계 학습 실행 - Qingquan Song, Haifeng Jin 및 Xia Hu
분산 기계 학습 패턴 - Yuan Tang
기계 학습 프로젝트 관리: 설계부터 배포까지 - Simon Thompson
인과적 기계 학습 - Robert Ness
베이지안 최적화 실행 - Quan Nguyen
심층적인 기계 학습 알고리즘) - Vadim Smolyakov
최적화 알고리즘 - Alaa Khamis
Guillaume Saupin의 실용적인 그라디언트 부스팅
맨 위로 돌아가기
맨 위로 돌아가기
TensorFlow는 머신러닝을 위한 엔드투엔드 오픈소스 플랫폼입니다. 연구자가 ML의 최첨단 기능을 활용하고 개발자가 ML 기반 애플리케이션을 쉽게 구축 및 배포할 수 있는 포괄적이고 유연한 도구, 라이브러리 및 커뮤니티 리소스 에코시스템을 갖추고 있습니다.
Keras는 Python으로 작성되었으며 TensorFlow, CNTK 또는 Theano 위에서 실행될 수 있는 고급 신경망 API입니다. 빠른 실험을 가능하게 하는 데 중점을 두고 개발되었습니다. TensorFlow, Microsoft Cognitive Toolkit, R, Theano 또는 PlaidML 위에서 실행될 수 있습니다.
PyTorch는 그래프, 포인트 클라우드, 매니폴드 등 불규칙한 입력 데이터에 대한 딥러닝을 위한 라이브러리입니다. 주로 Facebook의 AI 연구소에서 개발되었습니다.
Amazon SageMaker는 모든 개발자와 데이터 과학자에게 기계 학습(ML) 모델을 신속하게 구축, 교육 및 배포할 수 있는 기능을 제공하는 완전관리형 서비스입니다. SageMaker는 기계 학습 프로세스의 각 단계에서 어려운 작업을 제거하여 고품질 모델을 더 쉽게 개발할 수 있도록 해줍니다.
Azure Databricks는 데이터 과학 및 데이터 엔지니어링을 위해 설계된 빠르고 협업적인 Apache Spark 기반 빅 데이터 분석 서비스입니다. Azure Databricks는 몇 분 만에 Apache Spark 환경을 설정하고 대화형 작업 영역에서 공유 프로젝트에 대해 자동 크기 조정 및 공동 작업을 수행합니다. Azure Databricks는 Python, Scala, R, Java 및 SQL뿐만 아니라 TensorFlow, PyTorch 및 scikit-learn을 포함한 데이터 과학 프레임워크 및 라이브러리도 지원합니다.
CNTK(Microsoft Cognitive Toolkit)는 상용급 분산 딥 러닝을 위한 오픈 소스 도구 키트입니다. 이는 방향성 그래프를 통해 신경망을 일련의 계산 단계로 설명합니다. CNTK를 사용하면 사용자는 피드포워드 DNN, CNN(컨볼루션 신경망), RNN/LSTM(반복 신경망)과 같은 널리 사용되는 모델 유형을 쉽게 실현하고 결합할 수 있습니다. CNTK는 여러 GPU 및 서버에 걸쳐 자동 미분 및 병렬화를 통해 확률적 경사하강법(SGD, 오류 역전파) 학습을 구현합니다.
Apple CoreML은 기계 학습 모델을 앱에 통합하는 데 도움이 되는 프레임워크입니다. Core ML은 모든 모델에 대한 통합 표현을 제공합니다. 앱은 Core ML API와 사용자 데이터를 사용하여 사용자 기기에서 예측을 수행하고 모델을 교육하거나 미세 조정합니다. 모델은 훈련 데이터 세트에 기계 학습 알고리즘을 적용한 결과입니다. 모델을 사용하여 새로운 입력 데이터를 기반으로 예측을 합니다.
Apache OpenNLP는 자연어 텍스트 처리에 사용되는 기계 학습 기반 툴킷용 오픈 소스 라이브러리입니다. 명명된 엔터티 인식, 문장 감지, POS(품사) 태깅, 토큰화 기능 추출, 청킹, 구문 분석 및 상호 참조 해결과 같은 사용 사례를 위한 API를 제공합니다.
Apache Airflow는 워크플로를 프로그래밍 방식으로 작성, 예약 및 모니터링하기 위해 커뮤니티에서 만든 오픈 소스 워크플로 관리 플랫폼입니다. 설치하다. 원칙. 확장 가능. Airflow는 모듈식 아키텍처를 가지며 메시지 대기열을 사용하여 임의 수의 작업자를 조정합니다. 공기 흐름은 무한대로 확장될 준비가 되어 있습니다.
ONNX(Open Neural Network Exchange)는 AI 개발자가 프로젝트가 진행됨에 따라 올바른 도구를 선택할 수 있도록 지원하는 개방형 생태계입니다. ONNX는 딥 러닝과 기존 ML 모두 AI 모델을 위한 오픈 소스 형식을 제공합니다. 이는 확장 가능한 계산 그래프 모델뿐만 아니라 내장 연산자 및 표준 데이터 유형의 정의도 정의합니다.
Apache MXNet은 효율성과 유연성을 모두 고려하여 설계된 딥 러닝 프레임워크입니다. 이를 통해 기호 프로그래밍과 명령형 프로그래밍을 혼합하여 효율성과 생산성을 극대화할 수 있습니다. MXNet의 핵심에는 기호 작업과 명령형 작업을 즉시 자동으로 병렬화하는 동적 종속성 스케줄러가 포함되어 있습니다. 그 위에 있는 그래프 최적화 레이어는 기호 실행을 빠르고 메모리 효율적으로 만듭니다. MXNet은 휴대성이 뛰어나고 가벼우며 여러 GPU 및 여러 머신으로 효과적으로 확장됩니다. Python, R, Julia, Scala, Go, Javascript 등을 지원합니다.
AutoGluon은 애플리케이션에서 강력한 예측 성능을 쉽게 달성할 수 있도록 기계 학습 작업을 자동화하는 딥 러닝용 툴킷입니다. 단 몇 줄의 코드만으로 테이블 형식, 이미지 및 텍스트 데이터에 대한 정확도가 높은 딥 러닝 모델을 훈련하고 배포할 수 있습니다.
Anaconda는 사용자가 모델을 개발하고 훈련하고 배포할 수 있는 기계 학습 및 딥 러닝을 위한 매우 인기 있는 데이터 과학 플랫폼입니다.
PlaidML은 랩톱, 임베디드 장치 또는 사용 가능한 컴퓨팅 하드웨어가 제대로 지원되지 않거나 사용 가능한 소프트웨어 스택에 불쾌한 라이선스 제한이 있는 기타 장치에서 딥 러닝을 활성화하기 위한 고급 휴대용 텐서 컴파일러입니다.
OpenCV는 실시간 컴퓨터 비전 애플리케이션에 중점을 두고 고도로 최적화된 라이브러리입니다. C++, Python 및 Java 인터페이스는 Linux, MacOS, Windows, iOS 및 Android를 지원합니다.
Scikit-Learn은 SciPy, NumPy 및 matplotlib를 기반으로 구축된 기계 학습용 Python 모듈로, 널리 사용되는 많은 기계 학습 알고리즘의 강력하고 간단한 구현을 더 쉽게 적용할 수 있습니다.
Weka는 그래픽 사용자 인터페이스, 표준 터미널 애플리케이션 또는 Java API를 통해 액세스할 수 있는 오픈 소스 기계 학습 소프트웨어입니다. 교육, 연구 및 산업 응용 분야에 널리 사용되며 표준 기계 학습 작업을 위한 다양한 내장 도구가 포함되어 있으며 추가적으로 scikit-learn, R 및 Deeplearning4j와 같은 잘 알려진 도구 상자에 대한 투명한 액세스를 제공합니다.
Caffe는 표현, 속도 및 모듈성을 염두에 두고 만들어진 딥 러닝 프레임워크입니다. 이는 BAIR(Berkeley AI Research)/BVLC(Berkeley Vision and Learning Center) 및 커뮤니티 기여자들에 의해 개발되었습니다.
Theano는 NumPy와의 긴밀한 통합을 포함하여 다차원 배열과 관련된 수학적 표현식을 효율적으로 정의, 최적화 및 평가할 수 있는 Python 라이브러리입니다.
nGraph는 딥러닝을 위한 오픈 소스 C++ 라이브러리, 컴파일러 및 런타임입니다. nGraph 컴파일러는 딥 러닝 프레임워크를 사용하여 AI 워크로드 개발을 가속화하고 다양한 하드웨어 대상에 배포하는 것을 목표로 합니다. 이는 AI 개발자에게 자유로움, 성능 및 사용 편의성을 제공합니다.
NVIDIA cuDNN은 심층 신경망을 위한 GPU 가속 기본 요소 라이브러리입니다. cuDNN은 순방향 및 역방향 컨볼루션, 풀링, 정규화 및 활성화 레이어와 같은 표준 루틴에 대해 고도로 조정된 구현을 제공합니다. cuDNN은 Caffe2, Chainer, Keras, MATLAB, MxNet, PyTorch 및 TensorFlow를 포함하여 널리 사용되는 딥 러닝 프레임워크를 가속화합니다.
Huginn은 온라인에서 자동화된 작업을 수행하는 에이전트를 구축하기 위한 자체 호스팅 시스템입니다. 웹을 읽고, 이벤트를 감시하고, 사용자를 대신하여 조치를 취할 수 있습니다. Huginn의 에이전트는 이벤트를 생성하고 소비하여 방향성 그래프를 따라 전파합니다. 자체 서버에 있는 IFTTT 또는 Zapier의 해킹 가능한 버전이라고 생각하세요.
Netron은 신경망, 딥 러닝, 머신 러닝 모델을 위한 뷰어입니다. ONNX, TensorFlow Lite, Caffe, Keras, Darknet, PaddlePaddle, ncnn, MNN, Core ML, RKNN, MXNet, MindSpore Lite, TNN, Barracuda, Tengine, CNTK, TensorFlow.js, Caffe2 및 UFF를 지원합니다.
도파민은 강화 학습 알고리즘의 빠른 프로토타이핑을 위한 연구 프레임워크입니다.
DALI는 고도로 최적화된 빌딩 블록과 딥 러닝 훈련 및 추론 애플리케이션을 가속화하기 위한 데이터 처리용 실행 엔진을 포함하는 GPU 가속 라이브러리입니다.
MindSpore Lite는 모바일, 엣지 및 클라우드 시나리오에 사용할 수 있는 새로운 오픈 소스 딥 러닝 교육/추론 프레임워크입니다.
Darknet은 C 및 CUDA로 작성된 오픈 소스 신경망 프레임워크입니다. 빠르고 설치가 쉬우며 CPU 및 GPU 계산을 지원합니다.
PaddlePaddle은 사용하기 쉽고 효율적이며 유연하고 확장 가능한 딥 러닝 플랫폼으로, 원래 Baidu의 많은 제품에 딥 러닝을 적용할 목적으로 Baidu 과학자 및 엔지니어가 개발했습니다.
GoogleNotebookLM은 중요한 통찰력을 더 빠르게 얻기 위해 기존 콘텐츠와 결합된 언어 모델의 힘을 사용하는 실험적인 AI 도구입니다. 사실을 요약하고, 복잡한 아이디어를 설명하고, 선택한 소스를 기반으로 새로운 연결을 브레인스토밍할 수 있는 가상 연구 조교와 유사합니다.
Unilm은 작업, 언어 및 양식에 걸친 대규모 자체 감독 사전 교육입니다.
SK(Semantic Kernel)는 AI LLM(대형 언어 모델)을 기존 프로그래밍 언어와 통합할 수 있는 경량 SDK입니다. SK 확장 가능 프로그래밍 모델은 자연어 의미론적 기능, 기존 코드 기본 기능, 임베딩 기반 메모리를 결합하여 AI를 통해 새로운 잠재력을 발휘하고 애플리케이션에 가치를 추가합니다.
Pandas AI는 생성 인공 지능 기능을 Pandas에 통합하여 데이터 프레임을 대화형으로 만드는 Python 라이브러리입니다.
NCNN은 모바일 플랫폼에 최적화된 고성능 신경망 추론 프레임워크입니다.
MNN은 매우 빠르고 가벼운 딥 러닝 프레임워크로, Alibaba의 비즈니스 핵심 사용 사례를 통해 실전 테스트를 거쳤습니다.
MediaPipe는 다양한 플랫폼에서 엔드투엔드 성능을 발휘하도록 최적화되어 있습니다. 데모 보기 자세히 알아보기 복잡한 온디바이스 ML, 단순화 우리는 온디바이스 ML을 사용자 정의 가능하고, 프로덕션에 바로 사용할 수 있으며, 플랫폼 전반에 걸쳐 액세스할 수 있게 만드는 복잡성을 추상화했습니다.
MegEngine은 훈련과 추론을 모두 위한 통합 프레임워크라는 3가지 주요 기능을 갖춘 빠르고 확장 가능하며 사용자 친화적인 딥 러닝 프레임워크입니다.
ML.NET은 다른 인기 있는 ML 프레임워크(TensorFlow, ONNX, Infer.NET 등)를 사용하고 이미지 분류와 같은 훨씬 더 많은 기계 학습 시나리오에 액세스할 수 있도록 확장 가능한 플랫폼으로 설계된 기계 학습 라이브러리입니다. 물체 감지 등.
Ludwig는 간단하고 유연한 데이터 기반 구성 시스템을 사용하여 기계 학습 파이프라인을 쉽게 정의할 수 있게 해주는 선언적 기계 학습 프레임워크입니다.
MMdnn은 딥 러닝(DL) 모델을 변환, 시각화 및 진단하는 포괄적인 크로스 프레임워크 도구입니다. "MM"은 모델 관리(Model Management)를 의미하고 "dnn"은 심층 신경망(Deep Neural Network)의 약어입니다. Caffe, Keras, MXNet, Tensorflow, CNTK, PyTorch Onnx 및 CoreML 간에 모델을 변환합니다.
Horovod는 TensorFlow, Keras, PyTorch 및 Apache MXNet을 위한 분산형 딥 러닝 교육 프레임워크입니다.
Vaex는 큰 표 형식의 데이터 세트를 시각화하고 탐색하기 위한 게으른 Out-of-Core DataFrame(Pandas와 유사)을 위한 고성능 Python 라이브러리입니다.
GluonTS는 PyTorch 및 MXNet을 기반으로 하는 딥 러닝 기반 모델에 중점을 둔 확률적 시계열 모델링을 위한 Python 패키지입니다.
MindsDB는 SQL을 사용하여 가장 강력한 데이터베이스 및 데이터 웨어하우스에 대한 기계 학습 워크플로를 지원하는 ML-SQL 서버입니다.
Jupyter Notebook은 라이브 코드, 방정식, 시각화 및 설명 텍스트가 포함된 문서를 만들고 공유할 수 있는 오픈 소스 웹 애플리케이션입니다. Jupyter는 데이터 정리 및 변환, 수치 시뮬레이션, 통계 모델링, 데이터 시각화, 데이터 과학 및 기계 학습을 수행하는 산업에서 널리 사용됩니다.
Apache Spark는 대규모 데이터 처리를 위한 통합 분석 엔진입니다. Scala, Java, Python, R의 고급 API와 데이터 분석을 위한 일반 계산 그래프를 지원하는 최적화된 엔진을 제공합니다. 또한 SQL 및 DataFrames용 Spark SQL, 기계 학습용 MLlib, 그래프 처리용 GraphX, 스트림 처리용 구조적 스트리밍을 비롯한 다양한 고급 도구 세트를 지원합니다.
SQL Server 및 Azure SQL용 Apache Spark 커넥터는 빅 데이터 분석에서 트랜잭션 데이터를 사용하고 임시 쿼리 또는 보고에 대한 결과를 유지할 수 있게 해주는 고성능 커넥터입니다. 커넥터를 사용하면 온프레미스 또는 클라우드의 모든 SQL 데이터베이스를 Spark 작업의 입력 데이터 원본 또는 출력 데이터 싱크로 사용할 수 있습니다.
Apache PredictionIO는 개발자, 데이터 과학자 및 최종 사용자를 위한 오픈 소스 기계 학습 프레임워크입니다. REST API를 통해 이벤트 수집, 알고리즘 배포, 평가, 예측 결과 쿼리를 지원합니다. Hadoop, HBase(및 기타 DB), Elasticsearch, Spark와 같은 확장 가능한 오픈 소스 서비스를 기반으로 하며 Lambda 아키텍처를 구현합니다.
Apache Kafka용 클러스터 관리자(CMAK)는 Apache Kafka 클러스터를 관리하기 위한 도구입니다.
BigDL은 Apache Spark용 분산 딥러닝 라이브러리입니다. BigDL을 사용하면 사용자는 기존 Spark 또는 Hadoop 클러스터 위에서 직접 실행할 수 있는 표준 Spark 프로그램으로 딥 러닝 애플리케이션을 작성할 수 있습니다.
Eclipse Deeplearning4J(DL4J)는 JVM 기반(Scala, Kotlin, Clojure 및 Groovy) 딥 러닝 애플리케이션의 모든 요구 사항을 지원하기 위한 프로젝트 세트입니다. 이는 원시 데이터로 시작하여 어디서든 어떤 형식이든 로드하고 전처리하여 다양한 단순 및 복잡한 딥 러닝 네트워크를 구축하고 조정하는 것을 의미합니다.
Tensorman은 System76에서 개발한 Tensorflow 컨테이너를 쉽게 관리하기 위한 유틸리티입니다. Tensorman을 사용하면 Tensorflow가 시스템의 나머지 부분과 격리된 환경에서 작동할 수 있습니다. 이 가상 환경은 기본 시스템과 독립적으로 작동할 수 있으므로 Docker 런타임을 지원하는 모든 버전의 Linux 배포판에서 모든 버전의 Tensorflow를 사용할 수 있습니다.
Numba는 Anaconda, Inc.가 후원하는 Python용 오픈 소스 NumPy 인식 최적화 컴파일러입니다. Numba는 LLVM 컴파일러 프로젝트를 사용하여 Python 구문에서 기계어 코드를 생성합니다. Numba는 많은 NumPy 함수를 포함하여 숫자 중심 Python의 대규모 하위 집합을 컴파일할 수 있습니다. 또한 Numba는 루프 자동 병렬화, GPU 가속 코드 생성, ufunc 및 C 콜백 생성을 지원합니다.
Chainer는 유연성을 목표로 하는 Python 기반의 딥러닝 프레임워크입니다. 실행별 정의 접근 방식(동적 계산 그래프)을 기반으로 하는 자동 차별화 API와 신경망을 구축하고 훈련하기 위한 객체 지향 고급 API를 제공합니다. 또한 고성능 훈련 및 추론을 위해 CuPy를 사용하는 CUDA/cuDNN을 지원합니다.
XGBoost는 매우 효율적이고 유연하며 이식 가능하도록 설계된 최적화된 분산 그래디언트 부스팅 라이브러리입니다. Gradient Boosting 프레임워크에서 기계 학습 알고리즘을 구현합니다. XGBoost는 빠르고 정확한 방법으로 많은 데이터 과학 문제를 해결하는 병렬 트리 부스팅(GBDT, GBM이라고도 함)을 제공합니다. AWS, GCE, Azure 및 Yarn 클러스터를 포함한 여러 시스템에 대한 분산 교육을 지원합니다. 또한 Flink, Spark 및 기타 클라우드 데이터 흐름 시스템과 통합될 수 있습니다.
cuML은 다른 RAPIDS 프로젝트와 호환되는 API를 공유하는 기계 학습 알고리즘과 수학적 기본 함수를 구현하는 라이브러리 모음입니다. cuML을 사용하면 데이터 과학자, 연구원 및 소프트웨어 엔지니어가 CUDA 프로그래밍의 세부 사항을 다루지 않고도 GPU에서 기존의 테이블 형식 ML 작업을 실행할 수 있습니다. 대부분의 경우 cuML의 Python API는 scikit-learn의 API와 일치합니다.
Emu는 이식성, 모듈성 및 성능에 중점을 둔 Rust용 GPGPU 라이브러리입니다. 이는 WebGPU를 CUDA처럼 느껴지도록 특정 기능을 제공하는 WebGPU에 대한 CUDA와 같은 컴퓨팅 특정 추상화입니다.
Scalene은 다른 Python 프로파일러가 하지 않거나 할 수 없는 여러 가지 작업을 수행하는 Python용 고성능 CPU, GPU 및 메모리 프로파일러입니다. 훨씬 더 자세한 정보를 제공하면서 다른 많은 프로파일러보다 훨씬 빠르게 실행됩니다.
MLpack은 C++로 작성되고 Armadillo 선형 대수 라이브러리, 축소 수치 최적화 라이브러리 및 Boost의 일부를 기반으로 구축된 빠르고 유연한 C++ 기계 학습 라이브러리입니다.
Netron은 신경망, 딥 러닝, 머신 러닝 모델을 위한 뷰어입니다. ONNX, TensorFlow Lite, Caffe, Keras, Darknet, PaddlePaddle, ncnn, MNN, Core ML, RKNN, MXNet, MindSpore Lite, TNN, Barracuda, Tengine, CNTK, TensorFlow.js, Caffe2 및 UFF를 지원합니다.
Lightning은 DIY 인프라, 비용 관리, 확장 등을 처리하지 않고도 PyTorch 모델을 구축 및 교육하고 Lightning 앱 템플릿을 사용하여 ML 수명 주기에 연결하는 도구입니다.
OpenNN은 기계 학습을 위한 오픈 소스 신경망 라이브러리입니다. 여기에는 많은 인공 지능 솔루션을 처리하기 위한 정교한 알고리즘과 유틸리티가 포함되어 있습니다.
H20은 복잡한 비즈니스 문제를 해결하고 이해하고 신뢰할 수 있는 결과로 새로운 아이디어의 발견을 가속화하는 AI 클라우드 플랫폼입니다.
Gensim은 주제 모델링, 문서 색인화 및 대규모 말뭉치와의 유사성 검색을 위한 Python 라이브러리입니다. 대상 독자는 자연어 처리(NLP) 및 정보 검색(IR) 커뮤니티입니다.
llama.cpp는 C/C++로 된 Facebook의 LLaMA 모델 포트입니다.
hmmlearn은 비지도 학습 및 Hidden Markov 모델 추론을 위한 알고리즘 세트입니다.
Nextjournal은 재현 가능한 연구를 위한 노트북입니다. Docker 컨테이너에 넣을 수 있는 모든 것을 실행합니다. 다중 언어 노트북, 자동 버전 관리 및 실시간 협업을 통해 작업 흐름을 개선하세요. GPU 지원을 포함한 주문형 프로비저닝으로 시간과 비용을 절약하세요.
IPython은 다음을 통해 대화형 컴퓨팅을 위한 풍부한 아키텍처를 제공합니다.
Veles는 현재 삼성이 개발한 신속한 딥러닝 애플리케이션 개발을 위한 분산 플랫폼입니다.
DyNet은 Carnegie Mellon University 및 기타 여러 대학에서 개발한 신경망 라이브러리입니다. 이는 C++(Python 바인딩 포함)로 작성되었으며 CPU 또는 GPU에서 실행될 때 효율적이고 모든 교육 인스턴스에 대해 변경되는 동적 구조가 있는 네트워크에서 잘 작동하도록 설계되었습니다. 이러한 종류의 네트워크는 자연어 처리 작업에서 특히 중요하며 DyNet은 구문 분석, 기계 번역, 형태학적 활용 및 기타 여러 응용 분야를 위한 최첨단 시스템을 구축하는 데 사용되었습니다.
Ray는 AI 및 Python 애플리케이션 확장을 위한 통합 프레임워크입니다. ML 워크로드를 가속화하기 위한 핵심 분산 런타임과 라이브러리 툴킷(Ray AIR)으로 구성됩니다.
Whisper.cpp는 OpenAI의 Whisper 자동 음성 인식(ASR) 모델의 고성능 추론입니다.
ChatGPT Plus는 귀하와 채팅하고, 후속 질문에 답하고, 잘못된 가정에 도전할 수 있는 대화형 AI인 ChatGPT를 위한 파일럿 구독 플랜( 월 $20 )입니다.
Auto-GPT는 자연어로 목표를 제시하고 이를 하위 작업으로 나누고 자동 루프에서 인터넷 및 기타 도구를 사용하여 목표를 달성하려고 시도할 수 있는 "AI 에이전트"입니다. OpenAI의 GPT-4 또는 GPT-3.5 API를 사용하며 자율 작업을 수행하기 위해 GPT-4를 사용하는 애플리케이션의 첫 번째 예 중 하나입니다.
mckaywrigley의 Chatbot UI는 Next.js, TypeScript 및 Tailwind CSS를 사용하여 Chatbot UI Lite를 기반으로 구축된 OpenAI의 채팅 모델을 위한 고급 챗봇 키트입니다. 이 버전의 ChatBot UI는 GPT-3.5 및 GPT-4 모델을 모두 지원합니다. 대화는 브라우저 내에 로컬로 저장됩니다. 데이터 손실을 방지하기 위해 대화를 내보내고 가져올 수 있습니다. 데모를 확인하세요.
mckaywrigley의 Chatbot UI Lite는 Next.js, TypeScript 및 Tailwind CSS를 사용하는 OpenAI의 채팅 모델을 위한 간단한 챗봇 스타터 키트입니다. 데모를 확인하세요.
MiniGPT-4는 고급 대형 언어 모델을 통한 향상된 비전 언어 이해입니다.
GPT4All은 LLaMa를 기반으로 한 코드, 스토리 및 대화를 포함한 방대한 양의 깔끔한 보조 데이터 컬렉션을 기반으로 훈련된 오픈 소스 챗봇 생태계입니다.
GPT4All UI는 GPT4All 챗봇과 상호작용하기 위한 채팅 UI를 제공하는 Flask 웹 애플리케이션입니다.
Alpaca.cpp는 장치에서 로컬로 빠른 ChatGPT와 유사한 모델입니다. 이는 LLaMA 기반 모델과 Stanford Alpaca의 공개 재현, 지침(ChatGPT 교육에 사용되는 RLHF와 유사)을 따르도록 기본 모델을 미세 조정하고 채팅 인터페이스를 추가하기 위해 llama.cpp에 대한 일련의 수정 사항을 결합합니다.
llama.cpp는 C/C++로 된 Facebook의 LLaMA 모델 포트입니다.
OpenPlayground는 장치에서 로컬로 ChatGPT와 유사한 모델을 실행하기 위한 놀이터입니다.
Vicuna는 LLaMA를 미세 조정하여 훈련된 오픈 소스 챗봇입니다. chatgpt의 90% 이상의 품질을 달성했으며 훈련 비용은 300달러입니다.
Yeagar ai는 AI 기반 에이전트를 쉽게 구축, 프로토타입 및 배포할 수 있도록 설계된 Langchain Agent 제작자입니다.
Vicuna는 공개 API를 통해 ShareGPT.com에서 수집한 약 70,000개의 사용자 공유 대화를 사용하여 LLaMA 기본 모델을 미세 조정하여 만들어졌습니다. 데이터 품질을 보장하기 위해 HTML을 다시 마크다운으로 변환하고 부적절하거나 품질이 낮은 샘플을 필터링합니다.
ShareGPT는 한 번의 클릭으로 가장 격렬한 ChatGPT 대화를 공유할 수 있는 장소입니다. 지금까지 198,404개의 대화가 공유되었습니다.
FastChat은 대규모 언어 모델 기반 챗봇을 교육, 제공 및 평가하기 위한 개방형 플랫폼입니다.
Haystack은 Transformer 모델 및 LLM(GPT-4, ChatGPT 등)을 사용하여 데이터와 상호 작용하는 오픈 소스 NLP 프레임워크입니다. 복잡한 의사 결정, 질문 답변, 의미 체계 검색, 텍스트 생성 애플리케이션 등을 신속하게 구축할 수 있는 프로덕션 준비 도구를 제공합니다.
StableLM(Stability AI Language Models)은 StableLM 언어 모델 시리즈이며 새로운 체크포인트로 지속적으로 업데이트됩니다.
Databricks의 Dolly는 상업적 사용이 허가된 Databricks 기계 학습 플랫폼에서 훈련된 명령을 따르는 대규모 언어 모델입니다.
GPTCach는 LLM 쿼리용 의미 체계 캐시를 생성하기 위한 라이브러리입니다.
AlaC는 인공 지능 인프라형 코드 생성기입니다.
Adrenaline은 코드베이스와 대화할 수 있는 도구입니다. 정적 분석, 벡터 검색 및 대규모 언어 모델을 기반으로 합니다.
OpenAssistant는 작업을 이해하고, 타사 시스템과 상호 작용하고, 이를 위해 동적으로 정보를 검색할 수 있는 채팅 기반 도우미입니다.
DoctorGPT는 애플리케이션 로그에서 문제를 모니터링하고 진단하는 경량의 독립형 바이너리입니다.
HttpGPT는 비동기 REST 요청을 통해 OpenAI의 GPT 기반 서비스(ChatGPT 및 DALL-E)와의 통합을 촉진하는 Unreal Engine 5 플러그인으로, 개발자가 이러한 서비스와 쉽게 통신할 수 있도록 해줍니다. 또한 Chat GPT 및 DALL-E 이미지 생성을 엔진에 직접 통합하는 편집기 도구도 포함되어 있습니다.
PaLM 2는 기계 학습 및 책임 있는 AI에 대한 Google의 획기적인 연구 유산을 기반으로 하는 차세대 대규모 언어 모델입니다. 여기에는 코드 및 수학, 분류 및 질문 답변, 번역 및 다국어 숙련도, 이전 최첨단 LLM보다 뛰어난 자연어 생성을 포함한 고급 추론 작업이 포함됩니다.
Med-PaLM은 의료 질문에 대한 고품질 답변을 제공하도록 설계된 LLM(대형 언어 모델)입니다. 이는 Google이 세심하게 선별한 의료 전문가 시연 세트를 통해 의료 분야에 맞게 조정한 Google의 대규모 언어 모델의 강력한 기능을 활용합니다.
Sec-PaLM은 조직의 안전을 책임지는 사람들을 돕는 능력을 가속화하는 대규모 언어 모델(LLM)입니다. 이러한 새로운 모델은 사람들에게 보안을 이해하고 관리할 수 있는 보다 자연스럽고 창의적인 방법을 제공할 뿐만 아니라
맨 위로 돌아가기
맨 위로 돌아가기
맨 위로 돌아가기
LocalAI는 자체 호스팅, 커뮤니티 기반, 로컬 OpenAI 호환 API입니다. GPU가 필요없는 소비자 등급 하드웨어에서 Openai Running LLM에 대한 드롭 인 교체. LLAMA, GPT4ALL, RWKV, WHOSPER, VICUNA, KOALA, GPT4ALL-J, CEREBRAS, FALCON, DOLLY, StarCoder 등 GGML 호환 모델을 실행하는 것은 API입니다.
llama.cpp는 C/C ++의 Facebook의 LLAMA 모델 포트입니다.
Ollama는 Llama 2 및 기타 대형 언어 모델로 현지에서 일어나서 달리기위한 도구입니다.
LocalAi는 자체 주최, 지역 사회 중심의 지역 개방형 API입니다. GPU가 필요없는 소비자 등급 하드웨어에서 Openai Running LLM에 대한 드롭 인 교체. LLAMA, GPT4ALL, RWKV, WHOSPER, VICUNA, KOALA, GPT4ALL-J, CEREBRAS, FALCON, DOLLY, StarCoder 등 GGML 호환 모델을 실행하는 것은 API입니다.
Serge는 llama.cpp를 통해 Alpaca와 채팅하기위한 웹 인터페이스입니다. 사용하기 쉬운 API와 함께 완전히 자체 주최 및 도커 화.
OpenLlm은 프로덕션에서 LLM (Large Language Models)을 운영하기위한 개방형 플랫폼입니다. LLM을 쉽게 미세 조정, 서빙, 배포 및 모니터링하십시오.
Llama-Gpt는 자체 주최, 오프라인 Chatgpt와 같은 챗봇입니다. Llama 2. 100% Private로 구동되며 장치를 떠나는 데이터가 없습니다.
LLAMA2 WebUI는 GPU 또는 CPU (Linux/Windows/Mac)의 Gradio UI를 사용하여 LLAMA 2를 로컬로 실행하는 도구입니다. 생성 에이전트/앱의 llama2-wrapper 로컬 LLAMA2 백엔드로 사용하십시오.
llama2.c는 Pytorch에서 LLAMA 2 LLM 아키텍처를 훈련시킨 다음 하나의 간단한 700 라인 C 파일 (run.c)으로 추론하는 도구입니다.
Alpaca.cpp는 장치에서 로컬에서 빠른 Chatgpt와 같은 모델입니다. Llama Foundation 모델과 Stanford Alpaca의 개방형 재생산을 결합하여 기본 모델을 미세 조정하여 지침 (Chatgpt를 훈련시키는 데 사용되는 RLHF와 유사함)과 LLAMA.CPP에 대한 일련의 수정 세트를 채팅 인터페이스를 추가합니다.
GPT4ALL은 LLAMA를 기반으로 한 코드, 스토리 및 대화를 포함한 클린 보조 데이터의 대규모 컬렉션에 대해 교육을받은 오픈 소스 챗봇의 생태계입니다.
Minigpt-4
Lollms Webui는 LLM (대형 언어 모델) 모델의 허브입니다. 광범위한 작업을 위해 다양한 LLM 모델에 액세스하고 활용하기 위해 사용자 친화적 인 인터페이스를 제공하는 것을 목표로합니다. 글쓰기, 코딩, 데이터 구성, 이미지 생성 또는 질문에 대한 답변에 대한 도움이 필요한지 여부.
LM Studio는 로컬 LLM을 발견, 다운로드 및 실행하는 도구입니다.
Gradio Web UI는 대형 언어 모델을위한 도구입니다. 트랜스포머, GPTQ, LLAMA.CPP (GGML/GGUF), LLAMA 모델을 지원합니다.
OpenPlayGroun
Vicuna는 Fine Tuning Llama로 교육을받은 오픈 소스 챗봇입니다. 그것은 90% 이상의 Chatgpt 품질을 달성하고 훈련하는 데 $ 300의 비용이 들었습니다.
YeaGar AI는 AI 기반 에이전트를 쉽게 구축, 프로토 타입 및 배포하는 데 도움이되도록 설계된 Langchain 에이전트 제작자입니다.
KoboldCPP는 GGML 모델을위한 사용하기 쉬운 AI 텍스트 생성 소프트웨어입니다. Concedo에서 배포 할 수있는 단일 자체로 Llama.cpp를 구축하고 다양한 Kobold API 엔드 포인트, 추가 형식 지원, 뒤로 호환성, 지속적인 스토리, 도구 편집, 메모리, 메모리, 세계 저장 정보, 저자의 메모, 문자 및 시나리오.
맨 위로 돌아가기
퍼지 로직은보다 고급 의사 결정 트리 처리와 규칙 기반 프로그래밍과의 통합을 더 잘 통합 할 수있는 휴리스틱 접근법입니다.
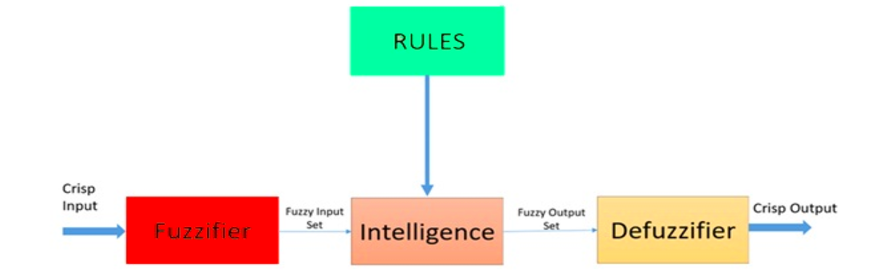
퍼지 논리 시스템의 아키텍처. 출처 : ResearchGate
SVM (Support Vector Machine)은 2 그룹 분류 문제에 분류 알고리즘을 사용하는 감독 된 기계 학습 모델입니다.

지지 벡터 머신 (SVM). 출처 : OpenClipart
신경망은 기계 학습의 하위 집합이며 딥 러닝 알고리즘의 핵심입니다. 이름/구조는 생물학적 뉴런/노드가 서로 신호를 보내는 과정을 복사하는 인간 뇌에서 영감을 얻습니다.
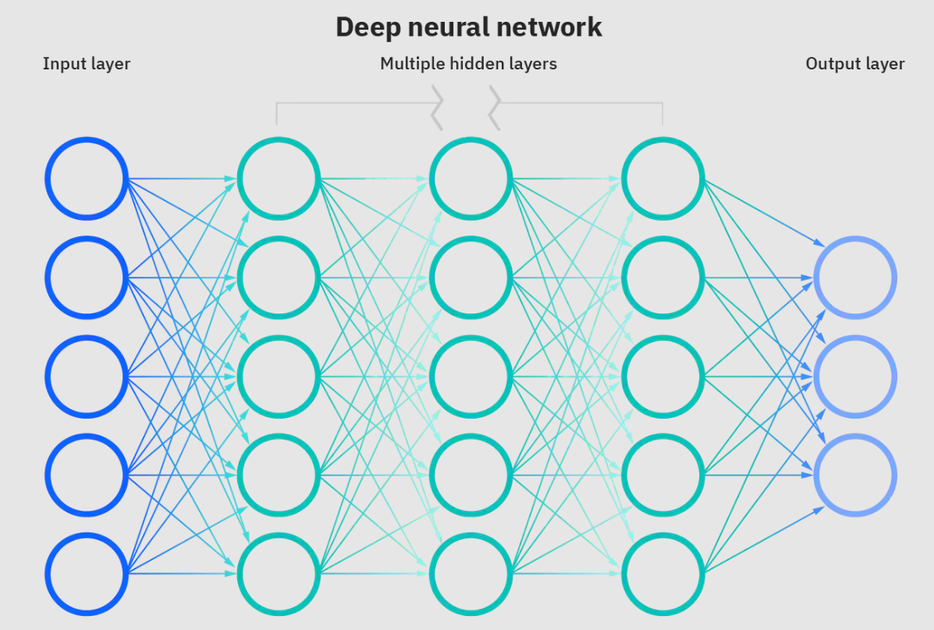
깊은 신경망. 출처 : IBM
Convolutional Neural Networks (R-CNN)는 이미지를 먼저 세그어링하여 잠재적 인 관련 경계 상자를 찾은 다음 감지 알고리즘을 실행하여 경계 박스에서 가장 가능성있는 객체를 찾는 객체 감지 알고리즘입니다.
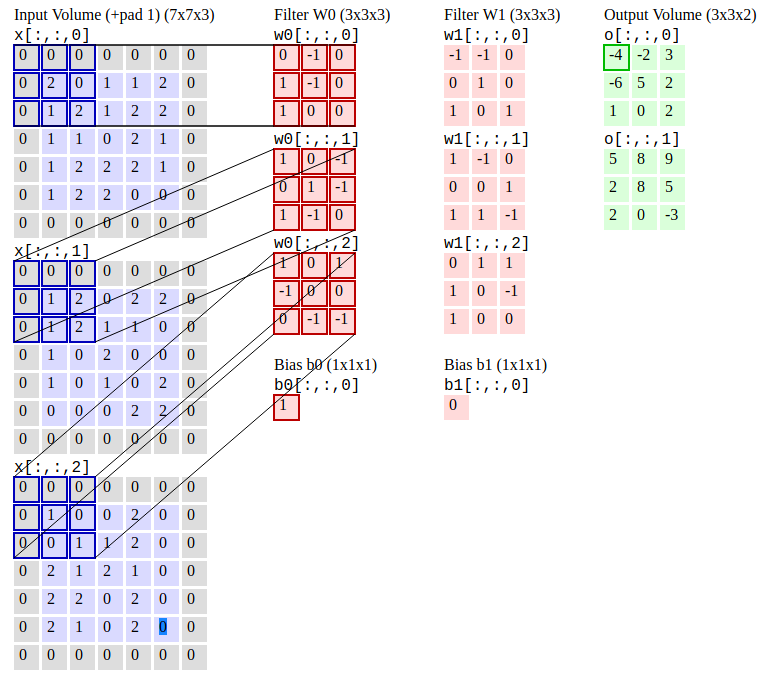
컨볼 루션 신경 네트워크. 출처 : CS231N
재발 성 신경망 (RNN)은 순차적 데이터 또는 시계열 데이터를 사용하는 인공 신경망의 한 유형입니다.
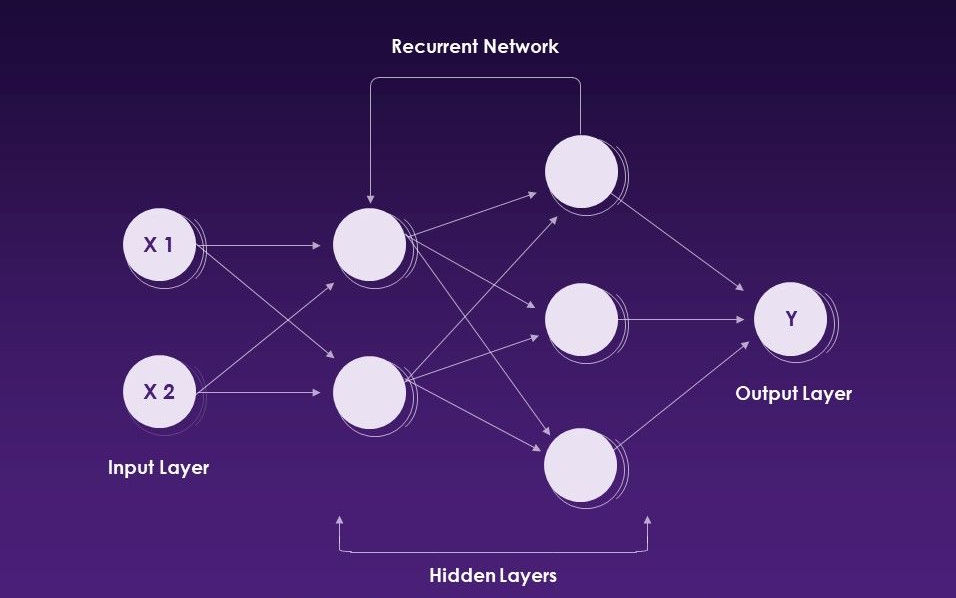
재발 성 신경망. 출처 : Slideteam
다층 퍼셉트론 (MLP)은 임계 값 활성화를 갖는 다중 층의 퍼셉트론으로 구성된 다층 신경망이다.
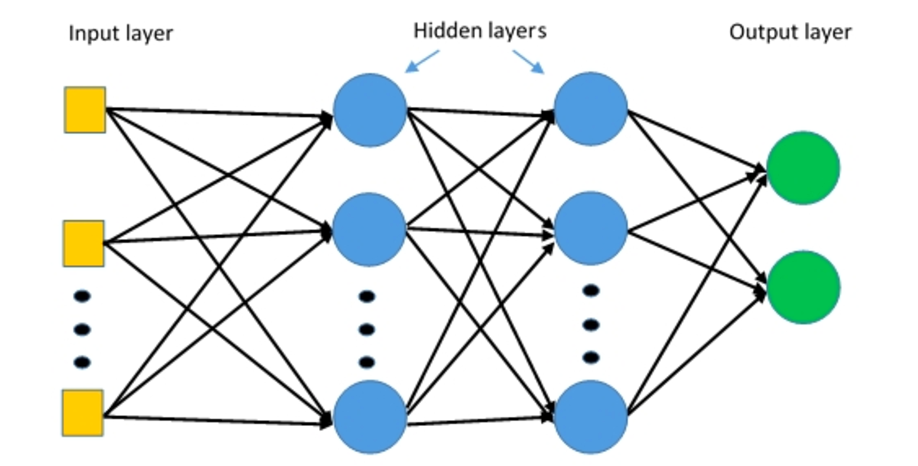
다층 퍼셉트론. 출처 : Deepai
Random Forest는 일반적으로 사용되는 머신 러닝 알고리즘으로 여러 의사 결정 트리의 출력을 결합하여 단일 결과에 도달합니다. 숲의 의사 결정 트리는 샘플링과 예측 선택을 위해 가지 치기 할 수 없습니다. 분류 및 회귀 문제를 모두 처리함에 따라 사용의 용이성과 유연성은 채택을 촉진했습니다.
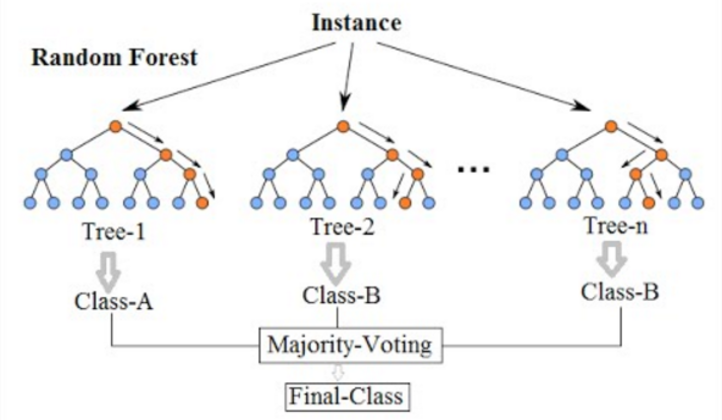
임의의 숲. 출처: 위키미디어
의사 결정 트리는 분류 및 회귀를위한 트리 구조 모델입니다.
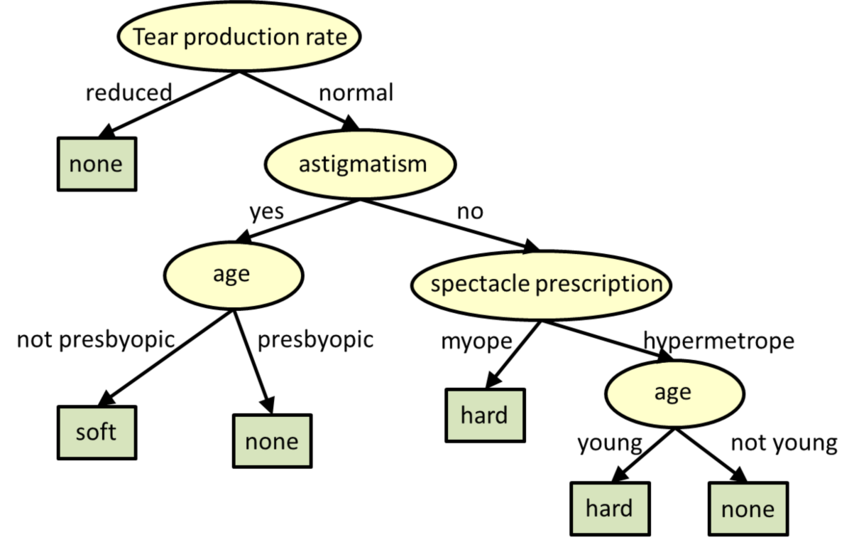
** 의사 결정 트리. 출처 : CMU
Naive Bayes는 해결 된 Calssification 문제를 사용하는 머신 러닝 알고리즘입니다. 그것은 특징들 사이에 강력한 독립 가정을 가진 베이 에스 정리를 적용하는 것을 기반으로합니다.

베이즈의 정리. 출처 : Mathisfun
맨 위로 돌아가기

Pytorch는 컴퓨터 비전 및 자연어 처리와 같은 응용 프로그램에 사용되는 연구에서 생산으로의 경로를 가속화하는 오픈 소스 딥 러닝 프레임 워크입니다. Pytorch는 Facebook의 AI Research Lab에서 개발했습니다.
Pytorch를 시작합니다
Pytorch 문서
Pytorch 토론 포럼
최고의 Pytorch 코스 온라인 | 코세라
최고의 Pytorch 코스 온라인 | 유데미
온라인 코스 및 수업으로 Pytorch를 배우십시오 | edX
Pytorch 기초 - 학습 | 마이크로소프트 문서
Pytorch로 딥 러닝에 소개 | 유다시티
Visual Studio Code의 Pytorch 개발
Azure의 Pytorch- Pytorch와의 딥 러닝 | 마이크로소프트 애저
Pytorch -Azure Databricks | 마이크로소프트 문서
Pytorch와의 딥 러닝 | 아마존 웹 서비스 (AWS)
Google Cloud에서 Pytorch를 시작합니다
Pytorch Mobile은 iOS 및 Android 모바일 장치 용 교육에서 배포까지 엔드 투 엔드 ML 워크 플로입니다.
Torchscript는 Pytorch 코드에서 직렬화 가능하고 최적화 가능한 모델을 작성하는 방법입니다. 이를 통해 Python 프로세스에서 모든 TorchScript 프로그램을 저장하고 Python 의존성이없는 프로세스에로드 할 수 있습니다.
Torchserve는 Pytorch 모델을 제공하는 유연하고 사용하기 쉬운 도구입니다.
Keras는 Python으로 작성되었으며 Tensorflow, CNTK 또는 Theano 위에서 실행할 수있는 고급 신경망 API로 빠른 실험을 가능하게하는 데 중점을두고 개발되었습니다. Tensorflow, Microsoft Cognitive Toolkit, R, Theano 또는 Plaidml 위에서 실행할 수 있습니다.
ONNX 런타임은 크로스 플랫폼, 고성능 ML 추론 및 훈련 가속기입니다. Pytorch 및 Tensorflow/Keras와 같은 딥 러닝 프레임 워크의 모델과 Scikit-Learn, LightGBM, Xgboost 등과 같은 클래식 머신 러닝 라이브러리의 모델을 지원합니다.
Kornia는 일반적인 CV (컴퓨터 비전) 문제를 해결하기위한 일련의 루틴 및 차별화 가능한 모듈로 구성된 차별화 가능한 컴퓨터 비전 라이브러리입니다.
Pytorch-NLP는 파이썬의 자연 언어 처리 (NLP)를위한 라이브러리입니다. 최신 연구를 염두에두고 구축되었으며 첫날부터 빠른 프로토 타이핑을 지원하도록 설계되었습니다. Pytorch-NLP에는 미리 훈련 된 임베딩, 샘플러, 데이터 세트 로더, 메트릭, 신경망 모듈 및 텍스트 인코더가 제공됩니다.
Ignite는 Pytorch의 신경 네트워크를 유연하고 투명하게 훈련하고 평가하는 데 도움이되는 고급 라이브러리입니다.
Hummingbird는 훈련 된 전통적인 ML 모델을 텐서 계산으로 컴파일하기위한 도서관입니다. 이를 통해 사용자는 신경망 네트워크 프레임 워크 (예 : Pytorch)를 완벽하게 활용하여 기존 ML 모델을 가속화 할 수 있습니다.
딥 그래프 라이브러리 (DGL)는 Pytorch 및 기타 프레임 워크 위에 그래프 신경망 모델 패밀리를 쉽게 구현할 수 있도록 제작 된 Python 패키지입니다.
Tensorly는 텐서 학습을 간단하게 만드는 것을 목표로하는 파이썬의 텐서 방법과 깊은 텐서화 된 신경망을위한 높은 수준의 API입니다.
Gpytorch는 확장 가능하고 유연한 가우스 프로세스 모델을 만들기 위해 설계된 Pytorch를 사용하여 구현 된 가우스 프로세스 라이브러리입니다.
Poutyne은 Pytorch의 케라 같은 프레임 워크이며 신경망을 훈련시키는 데 필요한 많은 보일러 플래팅 코드를 처리합니다.
Forte는 복합 가능한 구성 요소, 편리한 데이터 인터페이스 및 크로스 작업 상호 작용을 갖춘 NLP 파이프 라인을 구축하기위한 툴킷입니다.
Torchmetrics는 분산되고 확장 가능한 Pytorch 응용 프로그램을위한 머신 러닝 메트릭입니다.
Captum은 Pytorch에 구축 된 모델 해석 가능성을위한 오픈 소스, 확장 가능한 라이브러리입니다.
Transformer는 Pytorch, Tensorflow 및 Jax를위한 최첨단 자연 언어 처리입니다.
Hydra는 우아하게 복잡한 응용 프로그램을 구성하기위한 프레임 워크입니다.
Accelerate는 멀티 GPU, TPU, Mixed-Precision과 함께 Pytorch 모델을 훈련하고 사용하는 간단한 방법입니다.
Ray는 분산 응용 프로그램을 구축하고 실행하기위한 빠르고 간단한 프레임 워크입니다.
Parlai는 많은 작업에서 대화 모델을 공유, 교육 및 평가하기위한 통합 플랫폼입니다.
Pytorchvideo는 비디오 이해 연구를위한 딥 러닝 라이브러리입니다. 다양한 비디오 중심 모델, 데이터 세트, 교육 파이프 라인 등을 호스팅합니다.
Opacus는 차등 프라이버시로 Pytorch 모델을 훈련시킬 수있는 라이브러리입니다.
Pytorch Lightning은 Pytorch를위한 Keras와 같은 ML 라이브러리입니다. 그것은 당신에게 핵심 훈련과 검증 논리를 남기고 나머지를 자동화합니다.
Pytorch 기하학적 시간은 Pytorch 기하학을위한 시간적 (동적) 확장 라이브러리입니다.
Pytorch Geometric은 그래프, 포인트 클라우드 및 매니 폴드와 같은 불규칙한 입력 데이터에 대한 딥 러닝을위한 라이브러리입니다.
Raster Vision은 위성 및 항공 이미지에서 딥 러닝을위한 오픈 소스 프레임 워크입니다.
Crypten은 ML을 보존하는 개인 정보를위한 프레임 워크입니다. 그 목표는 ML 실무자가 안전한 컴퓨팅 기술을 이용할 수 있도록하는 것입니다.
Optuna는 하이퍼 파라미터 검색을 자동화하기위한 오픈 소스 하이퍼 파라미터 최적화 프레임 워크입니다.
Pyro는 Python으로 작성되고 백엔드에서 Pytorch가 지원하는 보편적 인 확률 론적 프로그래밍 언어 (PPL)입니다.
ALLUMentionations는 분류, 세분화, 객체 감지 및 포즈 추정과 같은 다양한 CV 작업을위한 빠르고 확장 가능한 이미지 증강 라이브러리입니다.
Skorch는 Pytorch를위한 고급 라이브러리로 전체 Scikit-Learn 호환성을 제공합니다.
MMF는 Facebook AI Research (Fair)의 비전 및 언어 다중 모드 연구를위한 모듈 식 프레임 워크입니다.
AdaptDL은 자원 적응 적 딥 러닝 교육 및 스케줄링 프레임 워크입니다.
Polyaxon은 대규모 딥 러닝 애플리케이션을 구축, 교육 및 모니터링하는 플랫폼입니다.
Textbrewer는 자연어 처리를위한 Pytorch 기반 지식 증류 툴킷입니다.
Advertorch는 적대적 견고성 연구를위한 도구 상자입니다. 여기에는 적대 예를 생성하고 공격에 대한 방어를위한 모듈이 포함되어 있습니다.
NEMO는 대화 AI를위한 AA 툴킷입니다.
ClinicAdl은 알츠하이머 병의 재현 가능한 분류를위한 틀입니다.
안정적인 기준 3 (SB3)은 Pytorch에서 강화 학습 알고리즘의 신뢰할 수있는 구현 세트입니다.
Torchio는 Pytorch로 작성된 딥 러닝 응용 프로그램에서 효율적으로 읽고, 전 프로세스, 샘플, 증강 및 쓸 수있는 일련의 도구입니다.
Pysyft는 암호화 된 개인 정보 보호 딥 러닝을위한 파이썬 라이브러리입니다.
Flair는 최첨단 자연 언어 처리 (NLP)를위한 매우 간단한 프레임 워크입니다.
Glow는 다양한 하드웨어 플랫폼에서 딥 러닝 프레임 워크의 성능을 가속화하는 ML 컴파일러입니다.
FairScale은 하나 또는 여러 기계/노드에 대한 고성능 및 대규모 교육을위한 Pytorch Extension 라이브러리입니다.
Monai는 의료 이미징 교육 워크 플로우를 개발하기위한 도메인 최적화 된 기본 기능을 제공하는 딥 러닝 프레임 워크입니다.
PFRL은 Pytorch를 사용하여 Python의 다양한 최첨단 심층 강화 알고리즘을 구현하는 심층 강화 학습 라이브러리입니다.
Einops는 읽을 수 있고 신뢰할 수있는 코드를위한 유연하고 강력한 텐서 작업입니다.
Pytorch3D는 Pytorch를 사용한 3D 컴퓨터 비전 연구를위한 효율적이고 재사용 가능한 구성 요소를 제공하는 딥 러닝 라이브러리입니다.
Ensemble Pytorch는 Pytorch가 딥 러닝 모델의 성능과 견고성을 향상시키기위한 통합 앙상블 프레임 워크입니다.
가볍게 자체 감독 학습을위한 컴퓨터 비전 프레임 워크입니다.
Higher는 자의적으로 복잡한 그라디언트 기반 메타 학습 알고리즘과 Vanilla Pytorch와 함께 중첩 된 최적화 루프의 구현을 용이하게하는 라이브러리입니다.
Horovod는 딥 러닝 프레임 워크를위한 분산 교육 라이브러리입니다. Horovod는 분산 된 DL을 빠르고 쉽게 사용하기를 목표로합니다.
Pennylane은 양자 ML, 자동 차별화 및 하이브리드 양자 클래식 계산의 최적화를위한 라이브러리입니다.
DetCerron2는 객체 감지 및 세분화를위한 Fair의 차세대 플랫폼입니다.
Fastai는 현대 모범 사례를 사용하여 빠르고 정확한 신경망을 단순화하는 도서관입니다.
맨 위로 돌아가기

TensorFlow는 머신러닝을 위한 엔드투엔드 오픈소스 플랫폼입니다. 이 회사는 공동적이고 유연한 도구, 라이브러리 및 커뮤니티 리소스의 생태계를 보유하고있어 연구원들이 ML의 최첨단을 밀고 개발자가 ML 전원 응용 프로그램을 쉽게 구축하고 배포 할 수 있도록합니다.
Tensorflow로 시작합니다
TensorFlow 튜토리얼
Tensorflow 개발자 인증서 | 텐서플로우
텐서 플로 커뮤니티
텐서 플로우 모델 및 데이터 세트
텐서 플로우 클라우드
기계 학습 교육 | 텐서플로우
온라인 최고의 텐서 플로우 코스 | 코세라
온라인 최고의 텐서 플로우 코스 | 유데미
Tensorflow를 사용한 딥 러닝 | 유데미
Tensorflow를 사용한 딥 러닝 | edX
딥 러닝을위한 텐서 플로우에 대한 소개 | 유다시티
텐서 플로우에 대한 소개 : 머신 러닝 충돌 코스 | Google 개발자
Tensorflow 모델 훈련 및 배포 -Azure Machine Learning
Python 및 Tensorflow를 사용하여 Azure 기능에 머신 러닝 모델을 적용 | 마이크로소프트 애저
Tensorflow를 사용한 딥 러닝 | 아마존 웹 서비스 (AWS)
Tensorflow -Amazon Emr | AWS 문서
Tensorflow Enterprise | 구글 클라우드
Tensorflow Lite는 모바일 및 IoT 장치에 머신 러닝 모델을 배포하기위한 오픈 소스 딥 러닝 프레임 워크입니다.
TensorFlow.js는 JavaScript에서 ML 모델을 개발하거나 실행하고 ML을 브라우저 클라이언트 측면에서 직접, Node.js를 통해 서버 측에서 직접 ML을 사용할 수있는 JavaScript 라이브러리입니다. Raspberry Pi의 Node.js를 통한 장치.
Tensorflow_macos는 Apple의 ML Compute 프레임 워크를 사용하여 MACOS 11.0+ 가속 된 MACOS 11.0+ 용 MAC 최적화 버전의 TensorFlow 및 Tensorflow Addon입니다.
Google 공동 작업은 무료 Jupyter 노트북 환경으로 설정이 필요하지 않고 클라우드에서 완전히 실행되므로 한 번의 클릭으로 브라우저에서 텐서 플로우 코드를 실행할 수 있습니다.
What-IF 도구는 모델 이해, 디버깅 및 공정성에 유용한 머신 러닝 모델의 코드없는 프로브를위한 도구입니다. Tensorboard 및 Jupyter 또는 Colab 노트북으로 제공됩니다.
Tensorboard는 Tensorflow 프로그램을 이해, 디버그 및 최적화 할 수있는 시각화 도구 제품군입니다.
Keras는 Python으로 작성되었으며 Tensorflow, CNTK 또는 Theano 위에서 실행할 수있는 고급 신경망 API로 빠른 실험을 가능하게하는 데 중점을두고 개발되었습니다. Tensorflow, Microsoft Cognitive Toolkit, R, Theano 또는 Plaidml 위에서 실행할 수 있습니다.
XLA (가속 선형 대수)는 텐서 플로 계산을 최적화하는 선형 대수에 대한 도메인 별 컴파일러입니다. 결과는 서버 및 모바일 플랫폼의 속도, 메모리 사용 및 이식성이 향상됩니다.
ML Perf는 ML 소프트웨어 프레임 워크, ML 하드웨어 가속기 및 ML 클라우드 플랫폼의 성능을 측정하기위한 광범위한 ML 벤치 마크 제품군입니다.
Tensorflow Playground는 브라우저의 신경망을 사용하여 땜질하는 개발 환경입니다.
TPU Research Cloud (TRC)는 연구원이 다음 연구 혁신의 물결을 가속화 할 수 있도록 1,000 개 이상의 클라우드 TPU 클러스터에 대한 액세스를 신청할 수있는 프로그램입니다.
MLIR은 새로운 중간 표현 및 컴파일러 프레임 워크입니다.
격자는 상식적인 형상 제약 조건을 갖춘 유연하고 제어되고 해석 가능한 ML 솔루션을위한 라이브러리입니다.
Tensorflow Hub는 재사용 가능한 기계 학습을위한 라이브러리입니다. 최소한의 코드로 최신 훈련 된 모델을 다운로드하여 재사용하십시오.
Tensorflow Cloud는 로컬 환경을 Google 클라우드에 연결하는 라이브러리입니다.
TensorFlow 모델 최적화 툴킷은 배포 및 실행을위한 ML 모델을 최적화하기위한 도구 제품군입니다.
Tensorflow 추천자는 추천 시스템 모델을 구축하기위한 라이브러리입니다.
Tensorflow 텍스트는 텍스트 및 NLP 관련 클래스 및 OPS 모음으로 Tensorflow 2와 함께 사용할 수 있습니다.
Tensorflow 그래픽은 카메라, 조명 및 재료부터 렌더러에 이르기까지 컴퓨터 그래픽 기능 라이브러리입니다.
Tensorflow Federated는 기계 학습 및 분산 데이터에 대한 기타 계산을위한 오픈 소스 프레임 워크입니다.
Tensorflow 확률은 확률 적 추론 및 통계 분석을위한 라이브러리입니다.
Tensor2tensor는 딥 러닝을보다 접근하기 쉽고 ML 연구를 가속화하도록 설계된 딥 러닝 모델 및 데이터 세트 라이브러리입니다.
Tensorflow Privacy는 차별화 된 개인 정보를 갖춘 기계 학습 모델을위한 Tensorflow Optimizers의 구현을 포함하는 Python 라이브러리입니다.
Tensorflow Ranking은 Tensorflow 플랫폼의 LTR (Learning-to Rank) 기술을위한 라이브러리입니다.
텐서 플로우 에이전트는 텐서 플로우에서 강화 학습을위한 라이브러리입니다.
Tensorflow Addons는 잘 확립 된 API 패턴을 준수하는 기여의 저장소이지만 SIG Addons가 유지 관리하는 코어 텐서 플로우에서는 사용할 수없는 새로운 기능을 구현합니다. Tensorflow는 기본적으로 많은 연산자, 레이어, 메트릭, 손실 및 최적화를 지원합니다.
Tensorflow I/O는 SIG IO가 관리하는 데이터 세트, 스트리밍 및 파일 시스템 확장입니다.
Tensorflow Quantum은 하이브리드 양자 클래식 ML 모델의 빠른 프로토 타이핑을위한 양자 머신 러닝 라이브러리입니다.
도파민은 강화 학습 알고리즘의 빠른 프로토 타이핑을위한 연구 프레임 워크입니다.
TRFL은 DeepMind가 만든 강화 학습 빌딩 블록을위한 도서관입니다.
Mesh Tensorflow는 분산 딥 러닝을위한 언어로, 광범위한 분산 텐서 계산을 지정할 수 있습니다.
RaggedTensors는 텍스트 (단어, 문장, 문자) 및 가변 길이의 배치를 포함하여 불균일 한 모양으로 데이터를 쉽게 저장하고 조작 할 수있는 API입니다.
Unicode Ops는 Tensorflow에서 유니 코드 텍스트 작업을 지원하는 API입니다.
Magenta는 예술과 음악을 만드는 과정에서 기계 학습의 역할을 탐구하는 연구 프로젝트입니다.
Nucleus는 Sam 및 VCF와 같은 공통 유전체학 파일 형식의 데이터를 쉽게 읽고 쓰고 쓰고 분석 할 수 있도록 설계된 Python 및 C ++ 코드 라이브러리입니다.
Sonnet은 신경망을 구성하기위한 DeepMind의 라이브러리입니다.
신경 구조 학습은 피처 입력 외에도 구조화 된 신호를 활용하여 신경망을 훈련시키는 학습 프레임 워크입니다.
Model Remediation은 기본 성능 바이어스로 인한 사용자 피해를 줄이거 나 제거하는 방식으로 모델을 만들고 훈련시키는 데 도움이되는 라이브러리입니다.
공정성 지표는 이진 및 멀티 클래스 분류기에 대한 일반적으로 식별 된 공정성 지표를 쉽게 계산할 수있는 라이브러리입니다.
Decision Forests는 분류, 회귀 및 순위를 위해 의사 결정 숲을 사용하는 모델 교육, 서비스 및 해석을위한 최첨단 알고리즘입니다.
맨 위로 돌아가기

Core ML은 기계 학습 모델을 Apple 장치 (iOS, WatchOS, MacOS 및 TVOS 포함)에서 실행중인 앱에 통합하기위한 Apple 프레임 워크입니다. Core ML은 심층 신경망 (Convolutional 및 Reburrent), 부스팅이 장착 된 트리 앙상블 및 일반화 된 선형 모델을 포함한 광범위한 ML 방법 세트에 대한 공개 파일 형식 (.mlmodel)을 소개합니다. 이 형식의 모델은 Xcode를 통해 앱에 직접 통합 될 수 있습니다.
핵심 ML 소개
핵심 ML 모델을 앱에 통합합니다
핵심 ML 모델
핵심 ML API 참조
핵심 ML 사양
Core ML의 Apple 개발자 포럼
최고 핵심 ML 코스 온라인 | 유데미
최고 핵심 ML 코스 온라인 | 코세라
Core ML |를위한 IBM WATSON 서비스 IBM
IBM Maximo Visual 검사를 사용하여 핵심 ML 자산 생성 | IBM
Core ML 도구는 핵심 ML 모델 변환, 편집 및 검증을위한 지원 도구가 포함 된 프로젝트입니다.
ML 작성 MAC에서 기계 학습 모델을 교육하는 새로운 방법을 제공하는 도구입니다. 강력한 핵심 ML 모델을 생성하면서 모델 교육에서 복잡성을 취합니다.
Tensorflow_macos는 Tensorfl의 Mac에서 최적화 된 버전입니다


