이 실습에서는 MLE가 정규 분포와 어떻게 작동하는지 알아보기 위해 이전 강의에서 본 수학 공식을 실제로 적용해 보겠습니다.
당신은 다음을 할 수 있습니다:
참고: *증명을 포함한 모든 MLE 방정식의 자세한 파생 내용은 이 웹사이트에서 볼 수 있습니다. *
아래에서 Python을 사용한 MLE 및 분포 피팅의 예를 살펴보겠습니다. 여기서 scipy.stats.norm.fit 최대 가능성 추정을 사용하여 분포 매개변수를 계산합니다.
from scipy . stats import norm # for generating sample data and fitting distributions
import matplotlib . pyplot as plt
plt . style . use ( 'seaborn' )
import numpy as np sample = Nonestats.norm.fit(data) 를 사용하세요. param = None
#param[0], param[1]
# (0.08241224761452863, 1.002987490235812)x = np.linspace(-5,5,100) 를 사용하여 맞춤 매개변수로부터 PDF를 계산합니다. x = np . linspace ( - 5 , 5 , 100 )
# Generate the pdf from fitted parameters (fitted distribution)
fitted_pdf = None
# Generate the pdf without fitting (normal distribution non fitted)
normal_pdf = None # Your code here 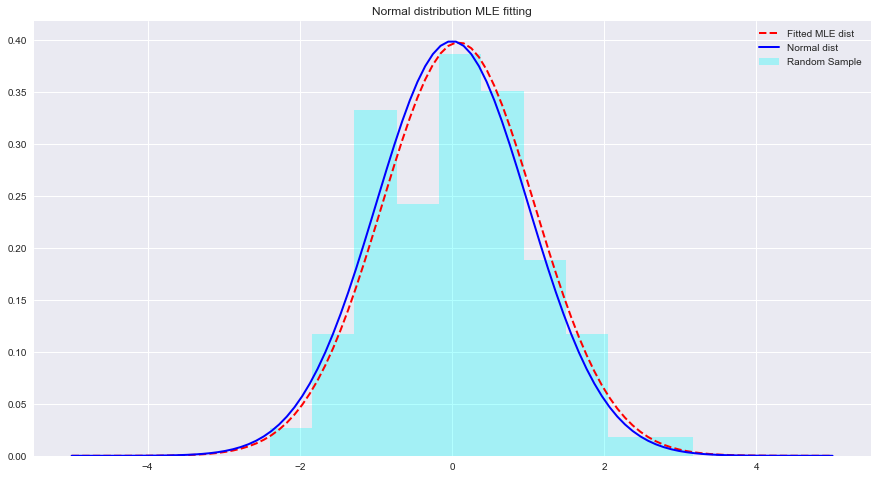
# Your comments/observations 이 짧은 실습에서는 가우스 맥락, 즉 기본 무작위 변수가 정규 분포를 따르는 베이지안 설정을 살펴보았습니다. 우리는 MLE가 예상 평균의 가능성을 최대화하여 정규 분포의 알려지지 않은 매개변수를 추정할 수 있다는 것을 배웠습니다. 예상 평균은 해당 매개변수 공간 내에서 적합하지 않은 정규 분포의 평균에 매우 가깝습니다. Naive Bayes Classifier를 사용하여 데이터 분포에 존재하는 여러 클래스의 평균을 추정할 때 이러한 추정이 어떻게 수행되는지 학습하는 방향으로 이러한 이해를 진행할 것입니다.


