vaex
Version linked to the paper
Vaex는 큰 표 형식의 데이터 세트를 시각화하고 탐색하기 위한 게으른 Out-of-Core DataFrame (Pandas와 유사)을 위한 고성능 Python 라이브러리입니다. 초당 10억 ( 10^9 )개 이상의 샘플/행에 대해 N차원 그리드 에서 평균, 합계, 개수, 표준 편차 등과 같은 통계를 계산합니다. 시각화는 히스토그램 , 밀도 플롯 및 3D 볼륨 렌더링을 사용하여 수행되므로 빅 데이터를 대화형으로 탐색할 수 있습니다. Vaex는 최고의 성능(메모리 낭비 없음)을 위해 메모리 매핑, 제로 메모리 복사 정책 및 지연 계산을 사용합니다.
핍으로:
$ pip install vaex
또는 콘다:
$ conda install -c conda-forge vaex
자세한 내용은 설명서를 참조하세요.
HDF5 및 Apache Arrow가 지원됩니다.

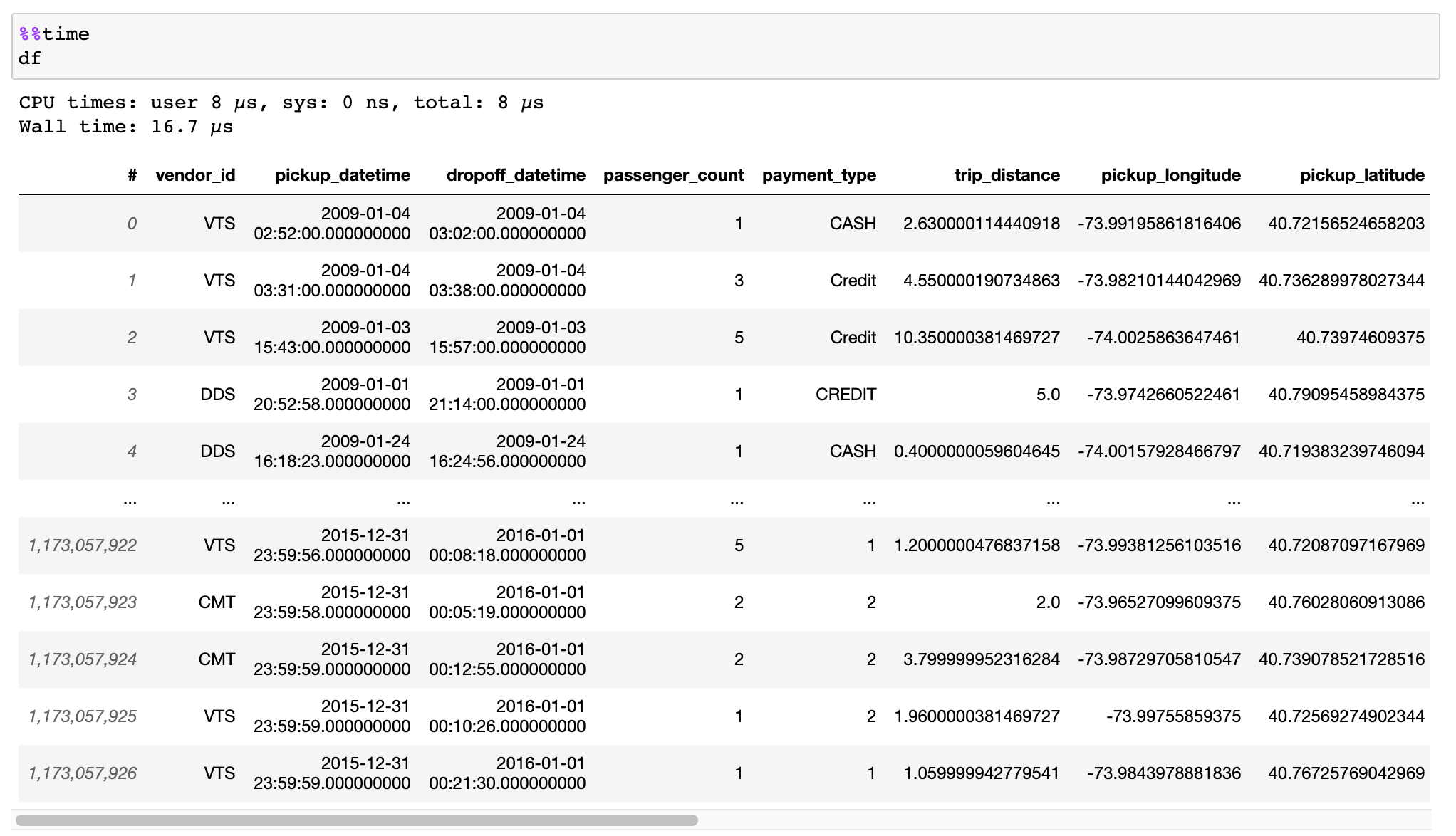
CSV 파일, Pandas DataFrames 또는 기타 소스의 데이터를 효율적으로 변환하는 방법에 대한 문서를 읽어보세요.
메모리 매핑과 함께 S3의 지연 스트리밍이 지원됩니다.

기능 엔지니어링으로 메모리나 시간을 낭비하지 마세요. 필요할 때 데이터를 (느리게) 변환합니다.
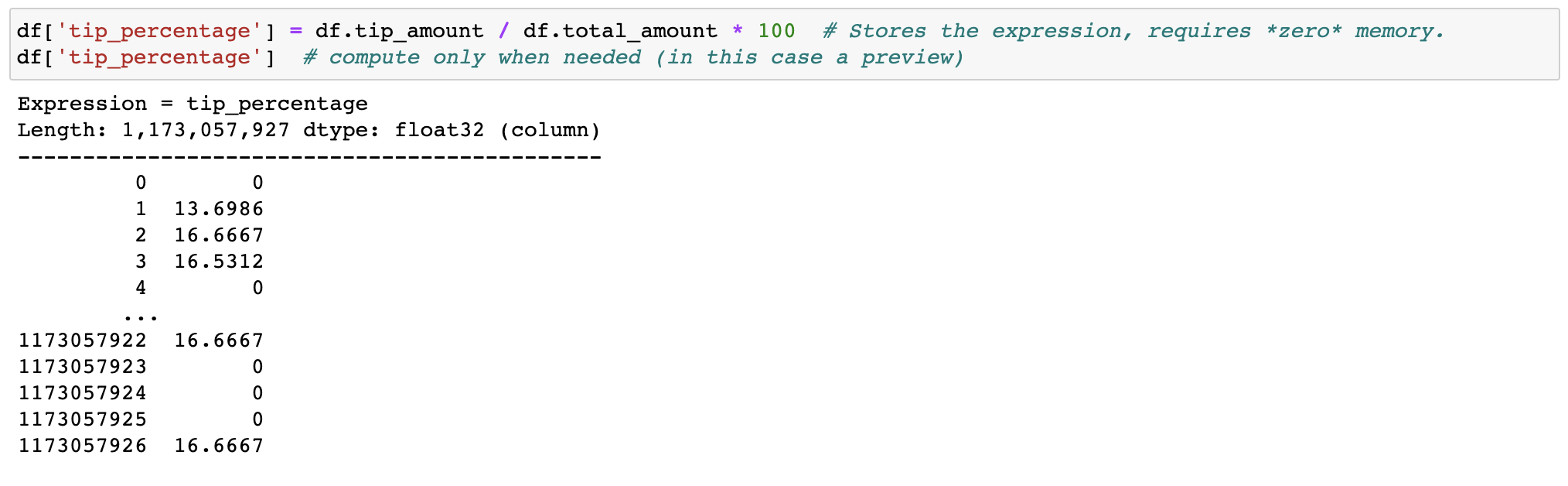
표현식을 필터링하고 평가하면 복사본을 만들어 메모리를 낭비하지 않습니다. 데이터는 디스크에 그대로 유지되며 필요할 때만 스트리밍됩니다. 클러스터가 필요하기 전에 시간을 지연시키십시오.
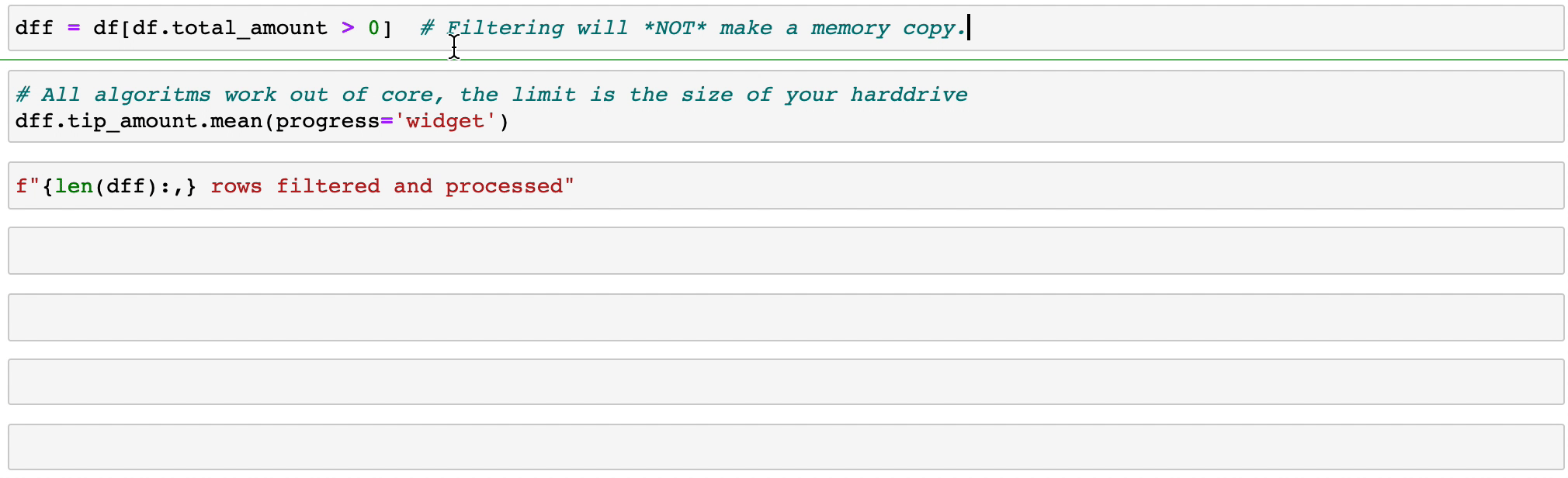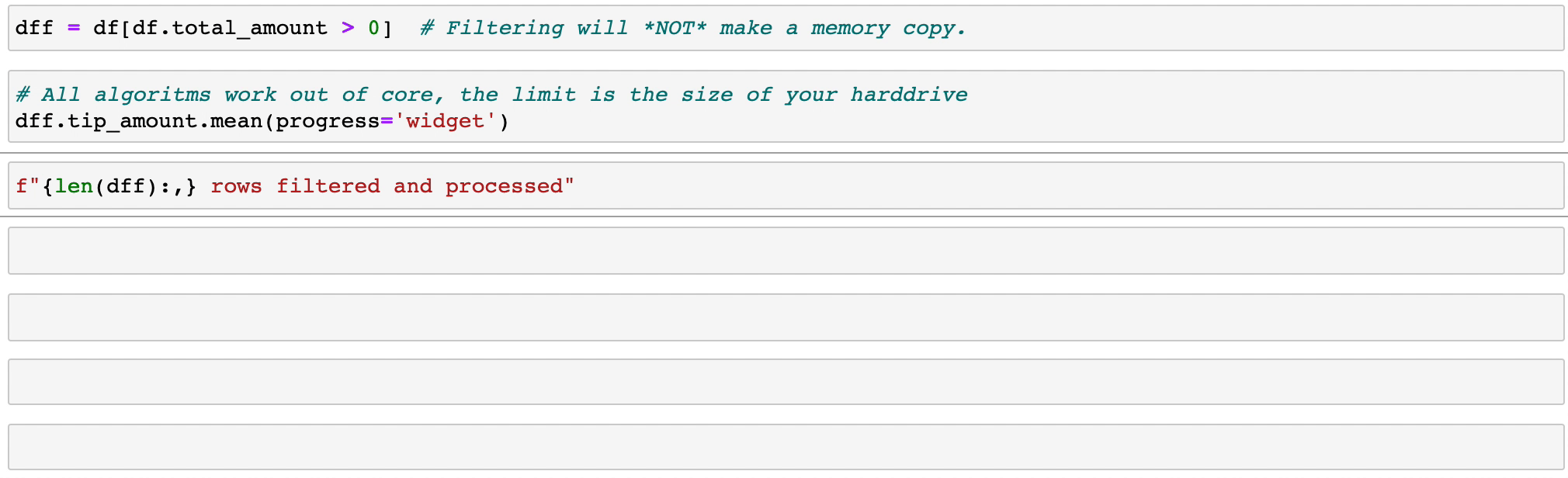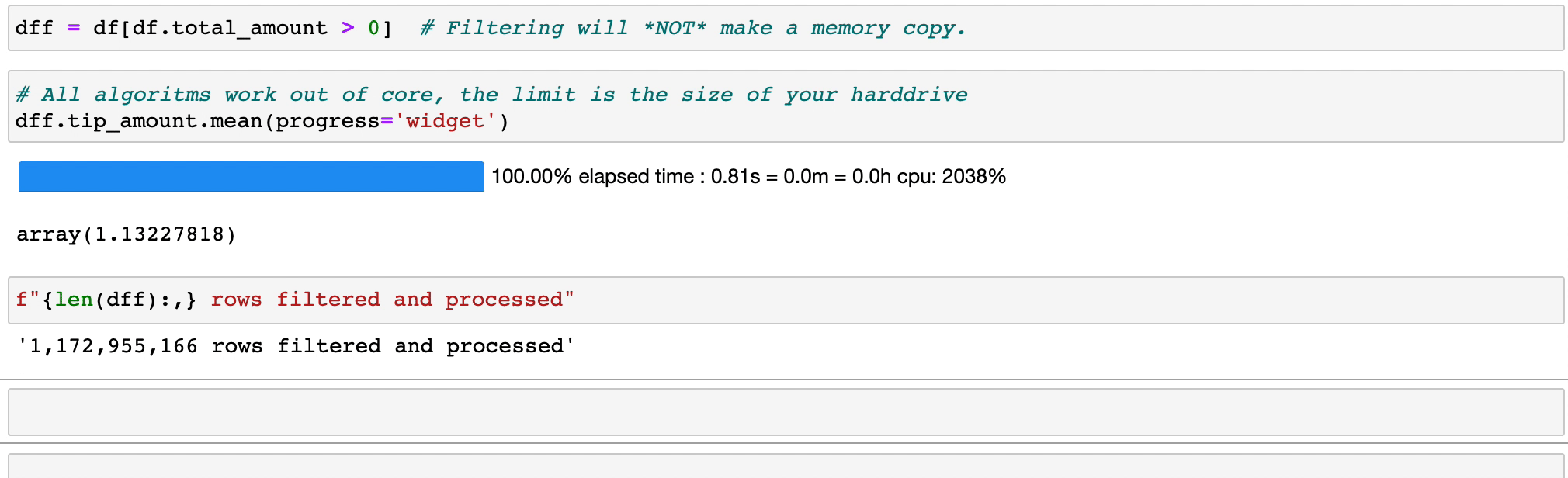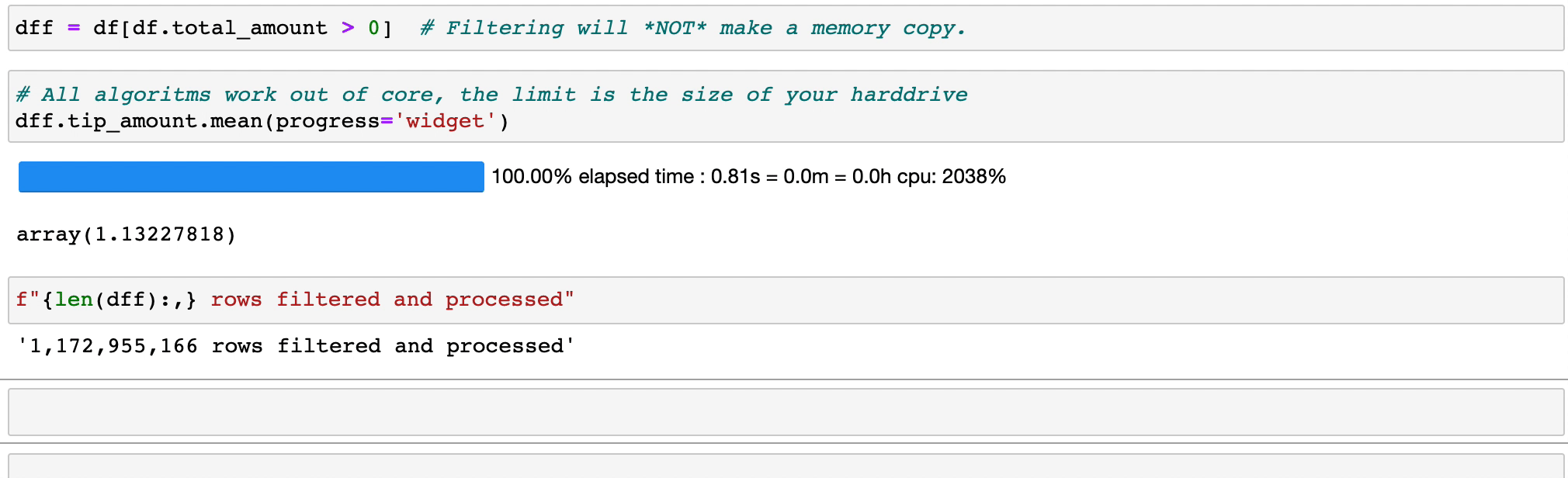
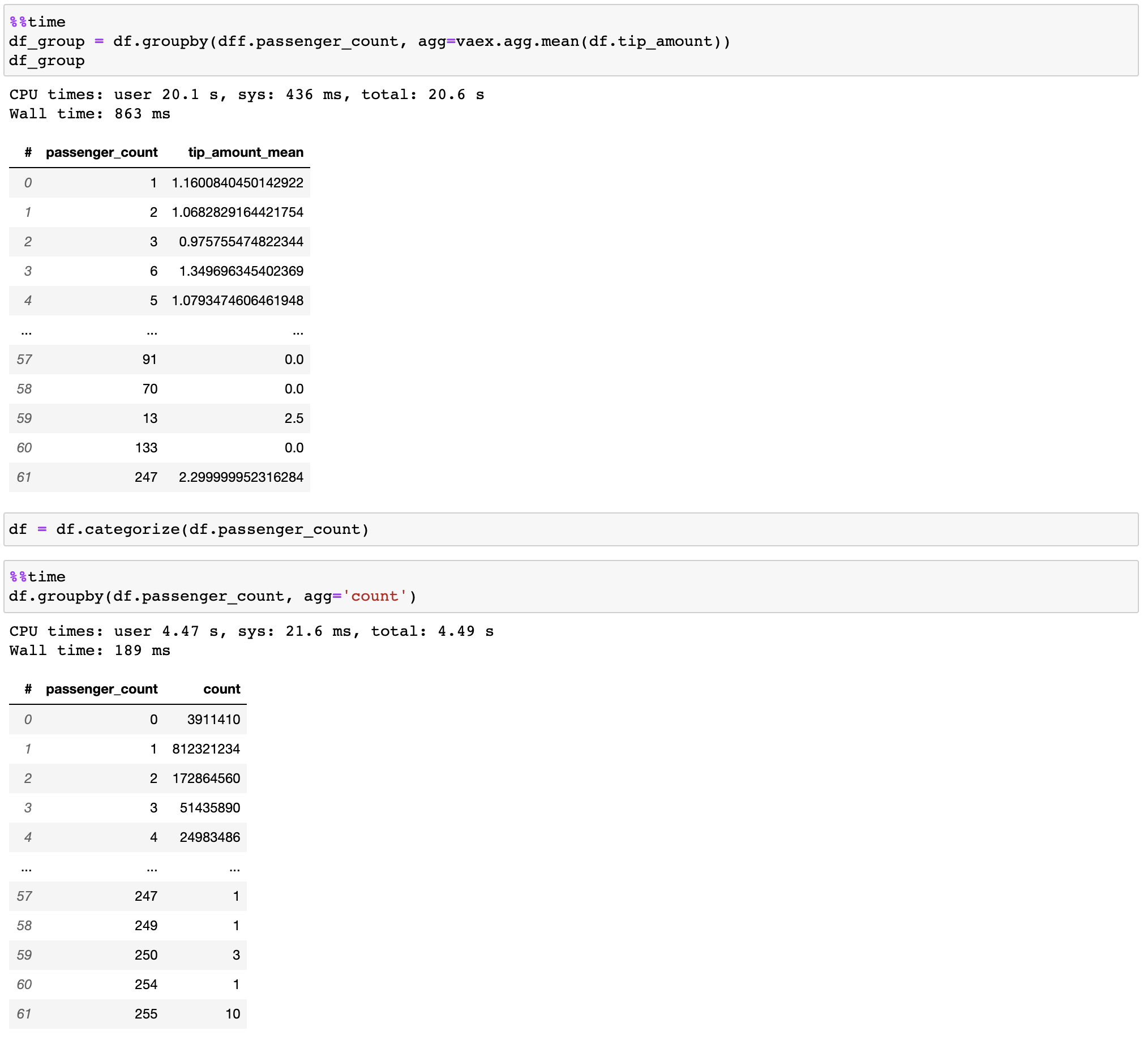
Vaex는 특히 카테고리(>10억/초)를 사용할 때 병렬화된 고성능 groupby 작업을 구현합니다.
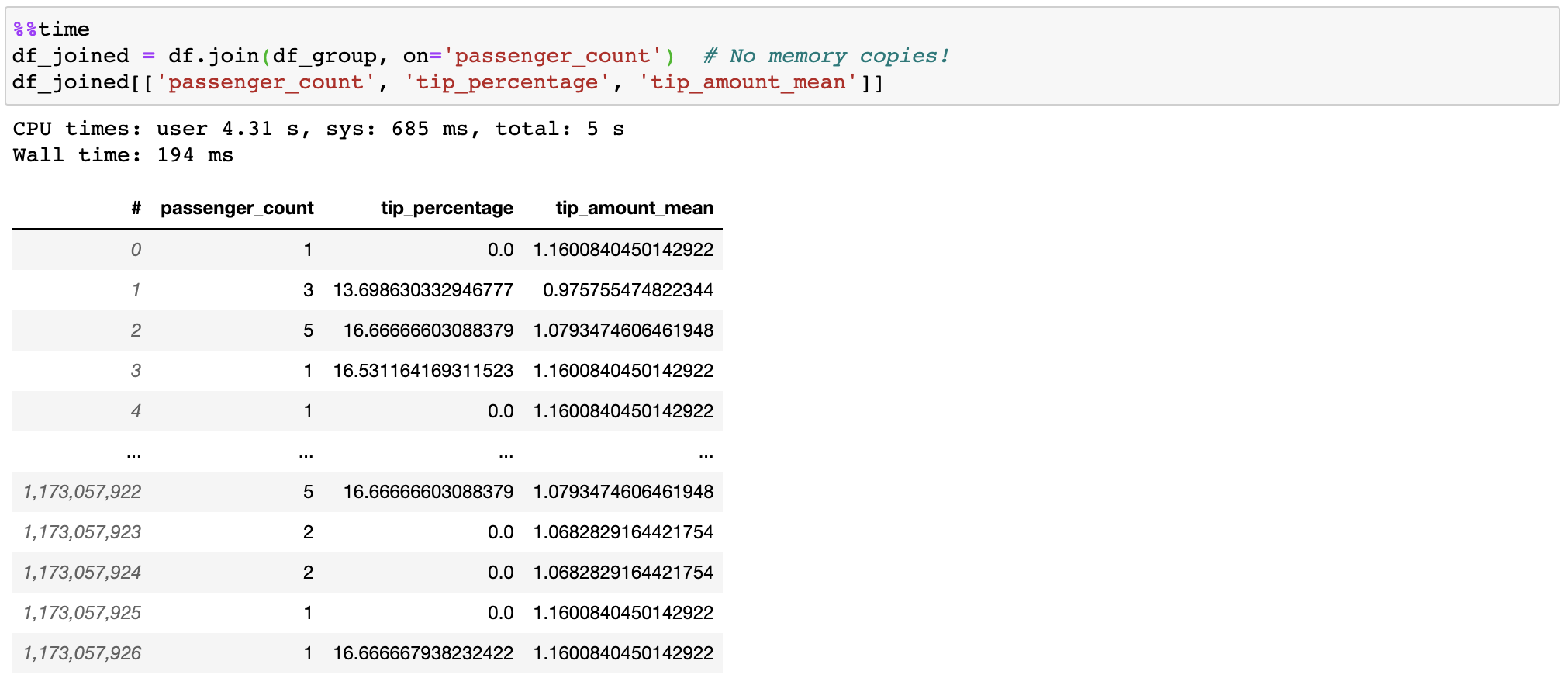
Vaex는 조인 시 '오른쪽' 테이블을 복사/구체화하지 않아 기가바이트의 메모리를 절약합니다. 10억 개의 행을 1초 미만으로 조인하면 꽤 빠릅니다!
기여 페이지를 참조하세요.
Slack 채널에서 토론에 참여하세요!
조항
튜토리얼을 따라해보세요
최근 강연을 시청해 보세요:
데이터 과학 솔루션, 교육 또는 기업 지원에 대해서는 https://vaex.io/에 문의하세요.


