stumpy
v1.13.0

STUMPY는 행렬 프로파일이라는 것을 효율적으로 계산하는 강력하고 확장 가능한 Python 라이브러리입니다. 이는 "시계열 내의 모든 (녹색) 하위 시퀀스에 대해 자동으로 해당하는 가장 가까운 이웃(회색)을 식별합니다"라고 말하는 학술적 표현입니다.
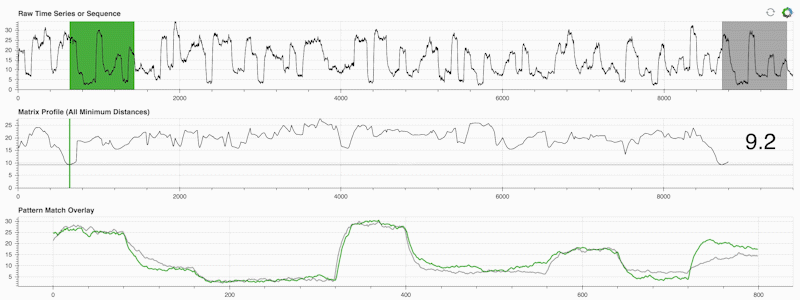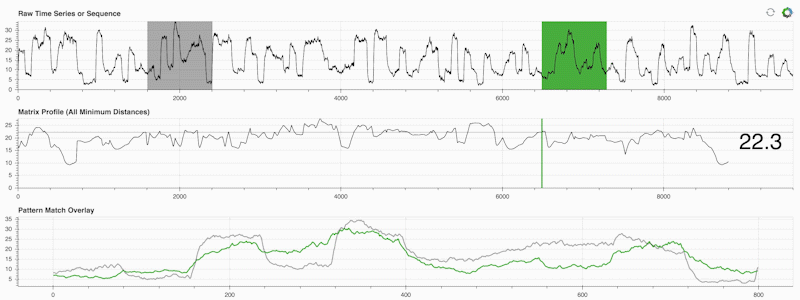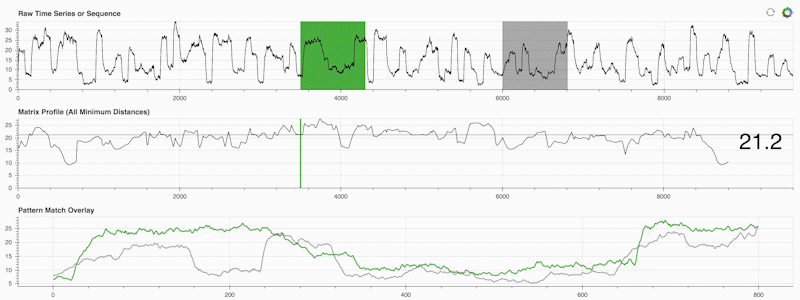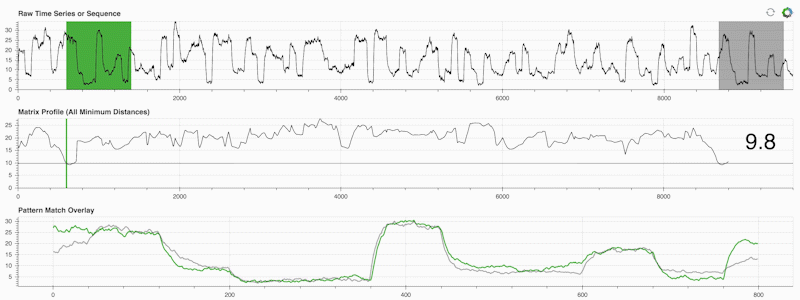
중요한 것은 매트릭스 프로필(위 중간 패널)을 계산한 후에는 다음과 같은 다양한 시계열 데이터 마이닝 작업에 사용할 수 있다는 것입니다.
귀하가 학자, 데이터 과학자, 소프트웨어 개발자 또는 시계열 애호가라면 STUMPY는 설치가 간단하며 우리의 목표는 귀하가 시계열 통찰력을 더 빨리 얻을 수 있도록 하는 것입니다. 자세한 내용은 설명서를 참조하세요.
사용 가능한 기능의 전체 목록은 API 문서를 참조하고, 보다 포괄적인 예제 사용 사례는 유익한 튜토리얼을 참조하세요. 아래에는 STUMPY 사용 방법을 빠르게 보여주는 코드 조각이 있습니다.
STUMP의 일반적인 사용법(1차원 시계열 데이터):
import stumpy
import numpy as np
if __name__ == "__main__" :
your_time_series = np . random . rand ( 10000 )
window_size = 50 # Approximately, how many data points might be found in a pattern
matrix_profile = stumpy . stump ( your_time_series , m = window_size )STUMPED를 통해 분산된 Dask를 사용한 1차원 시계열 데이터의 분산 사용:
import stumpy
import numpy as np
from dask . distributed import Client
if __name__ == "__main__" :
with Client () as dask_client :
your_time_series = np . random . rand ( 10000 )
window_size = 50 # Approximately, how many data points might be found in a pattern
matrix_profile = stumpy . stumped ( dask_client , your_time_series , m = window_size )GPU-STUMP를 사용한 1차원 시계열 데이터의 GPU 사용량:
import stumpy
import numpy as np
from numba import cuda
if __name__ == "__main__" :
your_time_series = np . random . rand ( 10000 )
window_size = 50 # Approximately, how many data points might be found in a pattern
all_gpu_devices = [ device . id for device in cuda . list_devices ()] # Get a list of all available GPU devices
matrix_profile = stumpy . gpu_stump ( your_time_series , m = window_size , device_id = all_gpu_devices )MSTUMP를 사용한 다차원 시계열 데이터:
import stumpy
import numpy as np
if __name__ == "__main__" :
your_time_series = np . random . rand ( 3 , 1000 ) # Each row represents data from a different dimension while each column represents data from the same dimension
window_size = 50 # Approximately, how many data points might be found in a pattern
matrix_profile , matrix_profile_indices = stumpy . mstump ( your_time_series , m = window_size )Dask Distributed MSTUMPED를 사용한 분산 다차원 시계열 데이터 분석:
import stumpy
import numpy as np
from dask . distributed import Client
if __name__ == "__main__" :
with Client () as dask_client :
your_time_series = np . random . rand ( 3 , 1000 ) # Each row represents data from a different dimension while each column represents data from the same dimension
window_size = 50 # Approximately, how many data points might be found in a pattern
matrix_profile , matrix_profile_indices = stumpy . mstumped ( dask_client , your_time_series , m = window_size )고정된 시계열 체인이 있는 시계열 체인(ATSC):
import stumpy
import numpy as np
if __name__ == "__main__" :
your_time_series = np . random . rand ( 10000 )
window_size = 50 # Approximately, how many data points might be found in a pattern
matrix_profile = stumpy . stump ( your_time_series , m = window_size )
left_matrix_profile_index = matrix_profile [:, 2 ]
right_matrix_profile_index = matrix_profile [:, 3 ]
idx = 10 # Subsequence index for which to retrieve the anchored time series chain for
anchored_chain = stumpy . atsc ( left_matrix_profile_index , right_matrix_profile_index , idx )
all_chain_set , longest_unanchored_chain = stumpy . allc ( left_matrix_profile_index , right_matrix_profile_index )FLUSS(Fast Low Cost Unipotent Semantic Segmentation)를 사용한 의미론적 분할:
import stumpy
import numpy as np
if __name__ == "__main__" :
your_time_series = np . random . rand ( 10000 )
window_size = 50 # Approximately, how many data points might be found in a pattern
matrix_profile = stumpy . stump ( your_time_series , m = window_size )
subseq_len = 50
correct_arc_curve , regime_locations = stumpy . fluss ( matrix_profile [:, 1 ],
L = subseq_len ,
n_regimes = 2 ,
excl_factor = 1
)지원되는 Python 및 NumPy 버전은 NEP 29 사용 중단 정책에 따라 결정됩니다.
Conda 설치(선호):
conda install -c conda-forge stumpynumpy, scipy 및 numba가 설치되어 있다고 가정하고 PyPI를 설치합니다.
python -m pip install stumpy소스에서 stumpy를 설치하려면 설명서의 지침을 참조하세요.
기본 알고리즘과 응용 프로그램을 완전히 이해하고 평가하려면 원본 출판물을 읽는 것이 중요합니다. STUMPY 사용 방법에 대한 더 자세한 예를 보려면 최신 문서를 참조하거나 실습 튜토리얼을 살펴보세요.
우리는 다양한 CPU 및 GPU 하드웨어 리소스와 함께 다양한 길이(예: np.random.rand(n) )로 무작위로 생성된 시계열 데이터에 대해 Numba JIT 컴파일 버전의 코드를 사용하여 정확한 행렬 프로파일을 계산하는 성능을 테스트했습니다.
원시 결과는 아래 표에 시간:분:초.밀리초로 표시되며 일정한 창 크기는 m = 50입니다. 보고된 런타임에는 호스트에서 모든 호스트로 데이터를 이동하는 데 걸리는 시간이 포함됩니다. GPU 장치. 모든 런타임을 보려면 표의 오른쪽으로 스크롤해야 할 수도 있습니다.
| 나 | n = 2 나는 | GPU-스톰프 | 그루터기.2 | 그루터기.16 | 난처하다.128 | 난처하다.256 | GPU-스텀프.1 | GPU-스텀프.2 | GPU-스텀프.DGX1 | GPU-스텀프.DGX2 |
|---|---|---|---|---|---|---|---|---|---|---|
| 6 | 64 | 00:00:10.00 | 00:00:00.00 | 00:00:00.00 | 00:00:05.77 | 00:00:06.08 | 00:00:00.03 | 00:00:01.63 | NaN | NaN |
| 7 | 128 | 00:00:10.00 | 00:00:00.00 | 00:00:00.00 | 00:00:05.93 | 00:00:07.29 | 00:00:00.04 | 00:00:01.66 | NaN | NaN |
| 8 | 256 | 00:00:10.00 | 00:00:00.00 | 00:00:00.01 | 00:00:05.95 | 00:00:07.59 | 00:00:00.08 | 00:00:01.69 | 00:00:06.68 | 00:00:25.68 |
| 9 | 512 | 00:00:10.00 | 00:00:00.00 | 00:00:00.02 | 00:00:05.97 | 00:00:07.47 | 00:00:00.13 | 00:00:01.66 | 00:00:06.59 | 00:00:27.66 |
| 10 | 1024 | 00:00:10.00 | 00:00:00.02 | 00:00:00.04 | 00:00:05.69 | 00:00:07.64 | 00:00:00.24 | 00:00:01.72 | 00:00:06.70 | 00:00:30.49 |
| 11 | 2048년 | NaN | 00:00:00.05 | 00:00:00.09 | 00:00:05.60 | 00:00:07.83 | 00:00:00.53 | 00:00:01.88 | 00:00:06.87 | 00:00:31.09 |
| 12 | 4096 | NaN | 00:00:00.22 | 00:00:00.19 | 00:00:06.26 | 00:00:07.90 | 00:00:01.04 | 00:00:02.19 | 00:00:06.91 | 00:00:33.93 |
| 13 | 8192 | NaN | 00:00:00.50 | 00:00:00.41 | 00:00:06.29 | 00:00:07.73 | 00:00:01.97 | 00:00:02.49 | 00:00:06.61 | 00:00:33.81 |
| 14 | 16384 | NaN | 00:00:01.79 | 00:00:00.99 | 00:00:06.24 | 00:00:08.18 | 00:00:03.69 | 00:00:03.29 | 00:00:07.36 | 00:00:35.23 |
| 15 | 32768 | NaN | 00:00:06.17 | 00:00:02.39 | 00:00:06.48 | 00:00:08.29 | 00:00:07.45 | 00:00:04.93 | 00:00:07.02 | 00:00:36.09 |
| 16 | 65536 | NaN | 00:00:22.94 | 00:00:06.42 | 00:00:07.33 | 00:00:09.01 | 00:00:14.89 | 00:00:08.12 | 00:00:08.10 | 00:00:36.54 |
| 17 | 131072 | 00:00:10.00 | 00:01:29.27 | 00:00:19.52 | 00:00:09.75 | 00:00:10.53 | 00:00:29.97 | 00:00:15.42 | 00:00:09.45 | 00:00:37.33 |
| 18 | 262144 | 00:00:18.00 | 00:05:56.50 | 00:01:08.44 | 00:00:33.38 | 00:00:24.07 | 00:00:59.62 | 00:00:27.41 | 00:00:13.18 | 00:00:39.30 |
| 19 | 524288 | 00:00:46.00 | 00:25:34.58 | 00:03:56.82 | 00:01:35.27 | 00:03:43.66 | 00:01:56.67 | 00:00:54.05 | 00:00:19.65 | 00:00:41.45 |
| 20 | 1048576 | 00:02:30.00 | 01:51:13.43 | 00:19:54.75 | 00:04:37.15 | 00:03:01.16 | 00:05:06.48 | 00:02:24.73 | 00:00:32.95 | 00:00:46.14 |
| 21 | 2097152 | 00:09:15.00 | 09:25:47.64 | 03:05:07.64 | 00:13:36.51 | 00:08:47.47 | 00:20:27.94 | 00:09:41.43 | 00:01:06.51 | 00:01:02.67 |
| 22 | 4194304 | NaN | 36:12:23.74 | 10:37:51.21 | 00:55:44.43 | 00:32:06.70 | 01:21:12.33 | 00:38:30.86 | 00:04:03.26 | 00:02:23.47 |
| 23 | 8388608 | NaN | 143:16:09.94 | 38:42:51.42 | 03:33:30.53 | 02:00:49.37 | 05:11:44.45 | 02:33:14.60 | 00:15:46.26 | 00:08:03.76 |
| 24 | 16777216 | NaN | NaN | NaN | 14:39:11.99 | 07:13:47.12 | 20:43:03.80 | 09:48:43.42 | 01:00:24.06 | 00:29:07.84 |
| NaN | 17729800 | 09:16:12.00 | NaN | NaN | 15:31:31.75 | 07:18:42.54 | 23:09:22.43 | 10:54:08.64 | 01:07:35.39 | 00:32:51.55 |
| 25 | 33554432 | NaN | NaN | NaN | 56:03:46.81 | 26:27:41.29 | 83:29:21.06 | 39:17:43.82 | 03:59:32.79 | 01:54:56.52 |
| 26 | 67108864 | NaN | NaN | NaN | 211:17:37.60 | 106:40:17.17 | 328:58:04.68 | 157:18:30.50 | 15:42:15.94 | 07:18:52.91 |
| NaN | 100000000 | 291:07:12.00 | NaN | NaN | NaN | 234:51:35.39 | NaN | NaN | 35:03:44.61 | 16:22:40.81 |
| 27 | 134217728 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 64:41:55.09 | 29:13:48.12 |
GPU-STOMP: 이 결과는 원본 Matrix Profile II 문서인 NVIDIA Tesla K80(2개의 GPU 포함)에서 재현되었으며 비교할 성능 벤치마크 역할을 합니다.
STUMP.2: 총 2개의 CPU로 실행된 stumpy.stump - Dask가 없는 단일 서버에서 Numba와 병렬화된 2x Intel(R) Xeon(R) CPU E5-2650 v4 @ 2.20GHz 프로세서.
STUMP.16: 총 16개의 CPU로 실행된 stumpy.stump - Dask가 없는 단일 서버에서 Numba와 병렬화된 16x Intel(R) Xeon(R) CPU E5-2650 v4 @ 2.20GHz 프로세서.
STUMPED.128: 총 128개 CPU로 실행된 stumpy.stumped - 8x Intel(R) Xeon(R) CPU E5-2650 v4 @ 2.20GHz 프로세서 x 16개 서버, Numba와 병렬화되고 Dask Distributed로 배포됩니다.
STUMPED.256: 총 256개 CPU로 실행된 stumpy.stumped - 8x Intel(R) Xeon(R) CPU E5-2650 v4 @ 2.20GHz 프로세서 x 32개 서버, Numba와 병렬화되고 Dask Distributed로 배포됩니다.
GPU-STUMP.1: stumpy.gpu_stump는 1x NVIDIA GeForce GTX 1080 Ti GPU, 블록당 512개 스레드, 200W 전력 제한으로 실행되고 Numba를 사용하여 CUDA로 컴파일되었으며 Python 다중 처리로 병렬화되었습니다.
GPU-STUMP.2: stumpy.gpu_stump는 2x NVIDIA GeForce GTX 1080 Ti GPU, 블록당 512개 스레드, 200W 전력 제한으로 실행되고 Numba를 사용하여 CUDA로 컴파일되었으며 Python 다중 처리로 병렬화되었습니다.
GPU-STUMP.DGX1: stumpy.gpu_stump는 8x NVIDIA Tesla V100, 블록당 512개의 스레드로 실행되고 Numba를 사용하여 CUDA로 컴파일되었으며 Python 다중 처리로 병렬화되었습니다.
GPU-STUMP.DGX2: stumpy.gpu_stump는 16x NVIDIA Tesla V100, 블록당 512개의 스레드로 실행되고 Numba를 사용하여 CUDA로 컴파일되었으며 Python 다중 처리로 병렬화되었습니다.
테스트는 tests 디렉터리에 작성되고 PyTest를 사용하여 처리되며 코드 적용 범위 분석을 위해 coverage.py 필요합니다. 테스트는 다음을 사용하여 실행할 수 있습니다.
./test.shSTUMPY는 Python 3.9+를 지원하며 유니코드 변수 이름/식별자의 사용으로 인해 Python 2.x와 호환되지 않습니다. 종속성이 작기 때문에 STUMPY는 이전 버전의 Python에서 작동할 수 있지만 이는 지원 범위를 벗어나므로 최신 버전의 Python으로 업그레이드하는 것이 좋습니다.
먼저, Github의 토론과 이슈를 확인하여 귀하의 질문에 이미 답변이 있는지 확인하세요. 해결 방법이 없는 경우 자유롭게 새로운 토론이나 문제를 제기하면 작성자가 합리적으로 시기적절한 방식으로 답변을 시도할 것입니다.
우리는 어떤 형태로든 기여를 환영합니다! 문서, 특히 확장 튜토리얼에 대한 지원은 언제나 환영합니다. 기여하려면 프로젝트를 포크하고 변경한 후 끌어오기 요청을 제출하세요. 우리는 귀하와 관련된 모든 문제를 해결하고 귀하의 코드를 메인 브랜치에 병합하기 위해 최선을 다할 것입니다.
이 코드베이스를 과학 출판물에 사용했고 이를 인용하고 싶다면 Journal of Open Source Software 기사를 사용하세요.
SM법률, (2019). STUMPY: 시계열 데이터 마이닝을 위한 강력하고 확장 가능한 Python 라이브러리 . 오픈 소스 소프트웨어 저널, 4(39), 1504.
@article { law2019stumpy ,
author = { Law, Sean M. } ,
title = { {STUMPY: A Powerful and Scalable Python Library for Time Series Data Mining} } ,
journal = { {The Journal of Open Source Software} } ,
volume = { 4 } ,
number = { 39 } ,
pages = { 1504 } ,
year = { 2019 }
}예, Chin-Chia Michael 외. (2016) 매트릭스 프로필 I: 시계열에 대한 모든 쌍 유사성 조인: 모티프, 불일치 및 셰이프릿을 포함하는 통합 보기. ICDM:1317-1322. 링크
주(Zhu), 얀(Yan) 등. (2016) 매트릭스 프로필 II: 시계열 모티프 및 조인에 대한 1억 개의 장벽을 깨기 위해 새로운 알고리즘 및 GPU 활용. ICDM:739-748. 링크
예, Chin-Chia Michael 외. (2017) 매트릭스 프로필 VI: 의미 있는 다차원 모티브 발견. ICDM:565-574. 링크
주(Zhu), 얀(Yan) 등. (2017) 매트릭스 프로필 VII: 시계열 체인: 시계열 데이터 마이닝을 위한 새로운 기본 요소. ICDM:695-704. 링크
Gharghabi, Shaghayegh 등. (2017) 매트릭스 프로필 VIII: 초인적 성능 수준의 도메인 불가지론적 온라인 의미론적 분할. ICDM:117-126. 링크
주(Zhu), 얀(Yan) 등. (2017) 새로운 알고리즘과 GPU를 활용하여 시계열 모티프 및 조인에 대한 10조 쌍 비교 장벽을 깨뜨림. 카이스:203-236. 링크
주(Zhu), 얀(Yan) 등. (2018) 매트릭스 프로필 XI: SCRIMP++: 대화형 속도로 시계열 모티브 발견. ICDM:837-846. 링크
예, Chin-Chia Michael 외. (2018) 시계열 조인, 모티프, 불일치 및 셰이프릿: 매트릭스 프로필을 활용하는 통합 보기. 데이터 Min Knowl 디스크:83-123. 링크
Gharghabi, Shaghyegh 등. (2018) "매트릭스 프로필 XII: MPdist: 더욱 까다로운 시나리오에서 데이터 마이닝을 허용하는 새로운 시계열 거리 측정." ICDM:965-970. 링크
짐머만, 재커리, 그 외 여러분. (2019) 매트릭스 프로필 XIV: 하루 이상으로 100경 쌍 비교를 깨기 위해 GPU를 사용한 시계열 모티프 검색 확장. SoCC '19:74-86. 링크
Akbarinia, Reza 및 Betrand Cloez. (2019) 다양한 거리 함수를 사용한 효율적인 행렬 프로파일 계산. arXiv:1901.05708. 링크
Kamgar, Kaveh 등. (2019) 매트릭스 프로파일 XV: 시계열 합의 모티브를 활용하여 시계열 세트에서 구조 찾기. ICDM:1156-1161. 링크


