demo ai app
1.0.0
데이터를 사용하여 앱에서 AI를 사용하는 방법을 시연하기 위한 Ion으로 구축된 샘플 영화 앱 — movie.sst.dev
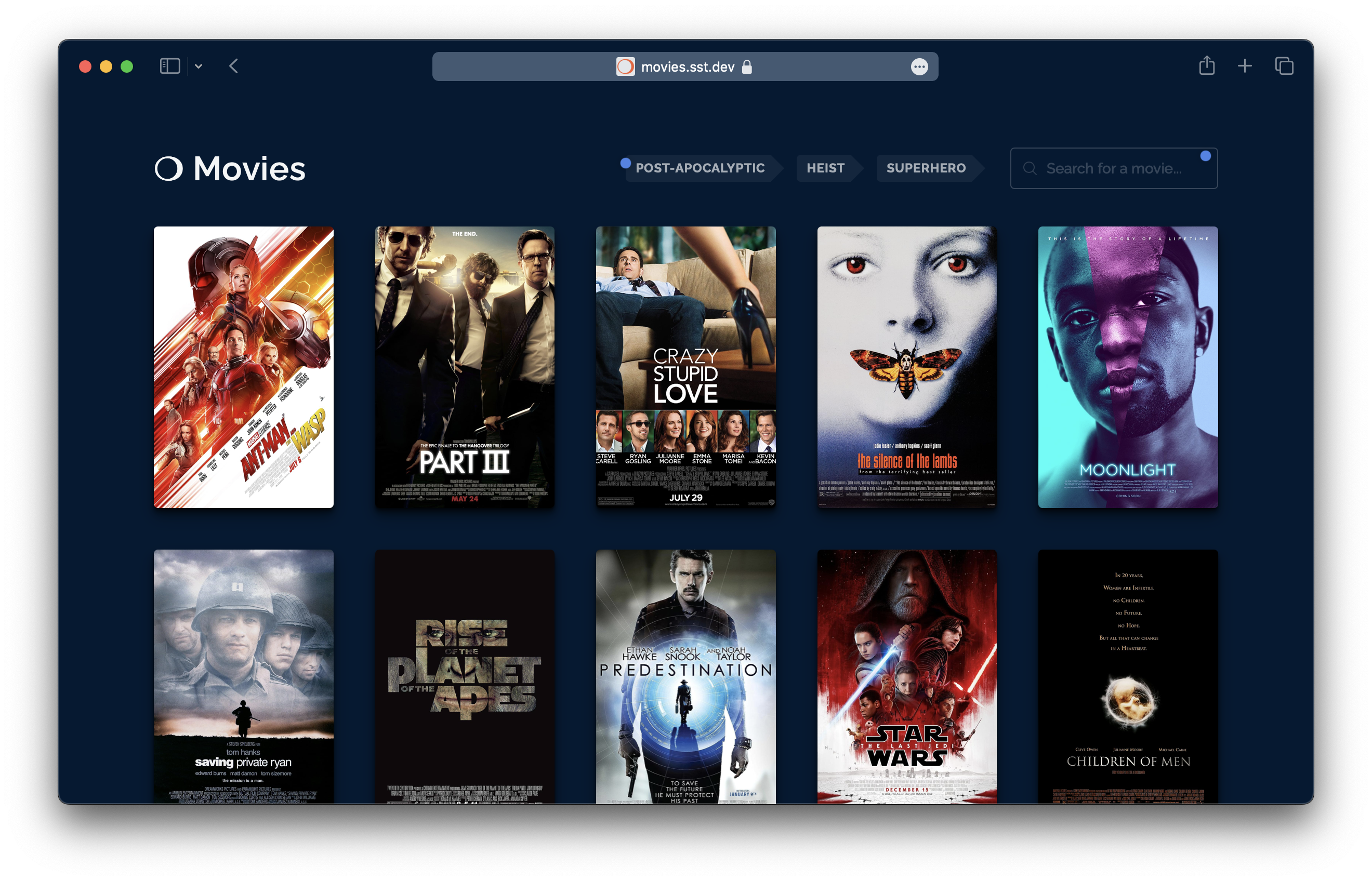
이 앱의 영화 데이터베이스에는 약 700편의 인기 영화가 포함되어 있습니다. 검색해서 관련 영화도 확인할 수 있고, 일부 영화에는 태그도 붙어있습니다.
현재까지 대부분의 AI 데모에는 일종의 채팅이 포함되어 있습니다. 이는 유용하지만 대부분의 앱에는 적용되지 않습니다. 또한 인프라 외부에 데이터를 저장하는 것도 포함됩니다.
이 데모에서는 사용자가 이해할 수 있는 방식으로 인프라에서 AI 관련 기능을 사용할 수 있는 방법을 보여줍니다.
다음 AI 기능은 새로운 Vector 구성 요소를 통해 구동됩니다.
Vector 구성 요소는 Amazon Bedrock을 기반으로 하며 데이터에 AI를 쉽게 사용할 수 있게 해주는 몇 가지 기능을 제공합니다.
ingest : 일부 텍스트를 가져와서 특정 모델로 임베딩을 생성하고 이를 RDS에서 제공하는 벡터 데이터베이스에 저장합니다. 또한 데이터에 태그를 지정하기 위해 일부 메타데이터를 사용합니다.retrieve : 프롬프트와 선택적으로 필터링할 메타데이터를 가져옵니다. 0 - 1 점수로 일치하는 결과를 반환합니다. 현재 임베딩은 titan-embed-text-v1 , titan-embed-image-v1 및 text-embedding-ada-002 사용하여 생성할 수 있습니다.
Ion은 이전 CDK 기반 엔진에 비해 몇 가지 고유한 장점을 지닌 SST용 실험적인 새 엔진입니다. 이 저장소에서 실제로 볼 수 있는 몇 가지 사항은 다음과 같습니다.
sst bind next build 없이 연결된 리소스에 액세스할 수 있습니다. 이 데모는 IMDB에서 영화 데이터를 수집하고, 임베딩을 생성하고, 이를 벡터 데이터베이스에 저장하는 방식으로 작동합니다. 그런 다음 Next.js 앱은 Vector 데이터베이스에서 데이터를 검색합니다.
샘플 앱은 sst.config.ts 에 정의된 4개의 간단한 구성 요소 로 구성됩니다.
Discord에서 SST 커뮤니티에 가입하고 Twitter에서 우리를 팔로우하세요.


