Coqui-AI/TTS의 XTTS 모듈에 대한 사용자 정의 Comfyui 노드!
영어 (en), 스페인어 (ES), 프랑스어 (FR), 독일어 (DE), 이탈리아 (IT), 포르투갈어 (PT), 폴란드 (PL), 터키 (TR), 러시아어 (RU), 네덜란드 (NL), 체코 (CS), 아랍어 (AR), 중국어 (ZH-CN), 일본 (JA), 헝가리 (HU), 한국 (KO) 힌디어 (HI)
우리는 코드베이스의 불법적 인 사용에 대한 책임을지지 않습니다.
srt 파일이 지원되었습니다srt 의 Finetune 및 추론에서 지원되었습니다. Linux의 Commandline에서 ffmpeg 작동하는지 확인하십시오.
apt update
apt install ffmpeg
Windows의 경우 Winetui별로 ffmpeg 자동으로 설치할 수 있습니다
그 다음에!
git clone https://github.com/AIFSH/ComfyUI-XTTS.git
cd ComfyUI-XTTS
pip install -r requirements.txt
weights HuggingFace에서 자동으로 다운로드됩니다. 인터넷이 HuggingFace를 첨부하거나 HF-Mirror를 따라야 할 수 있습니다.
또는 가중치 파일을 다운로드하고 압축을 풀고, pretrained_models 의 전체 폴더를 ComfyUI-XTTS 디렉토리에 넣습니다.
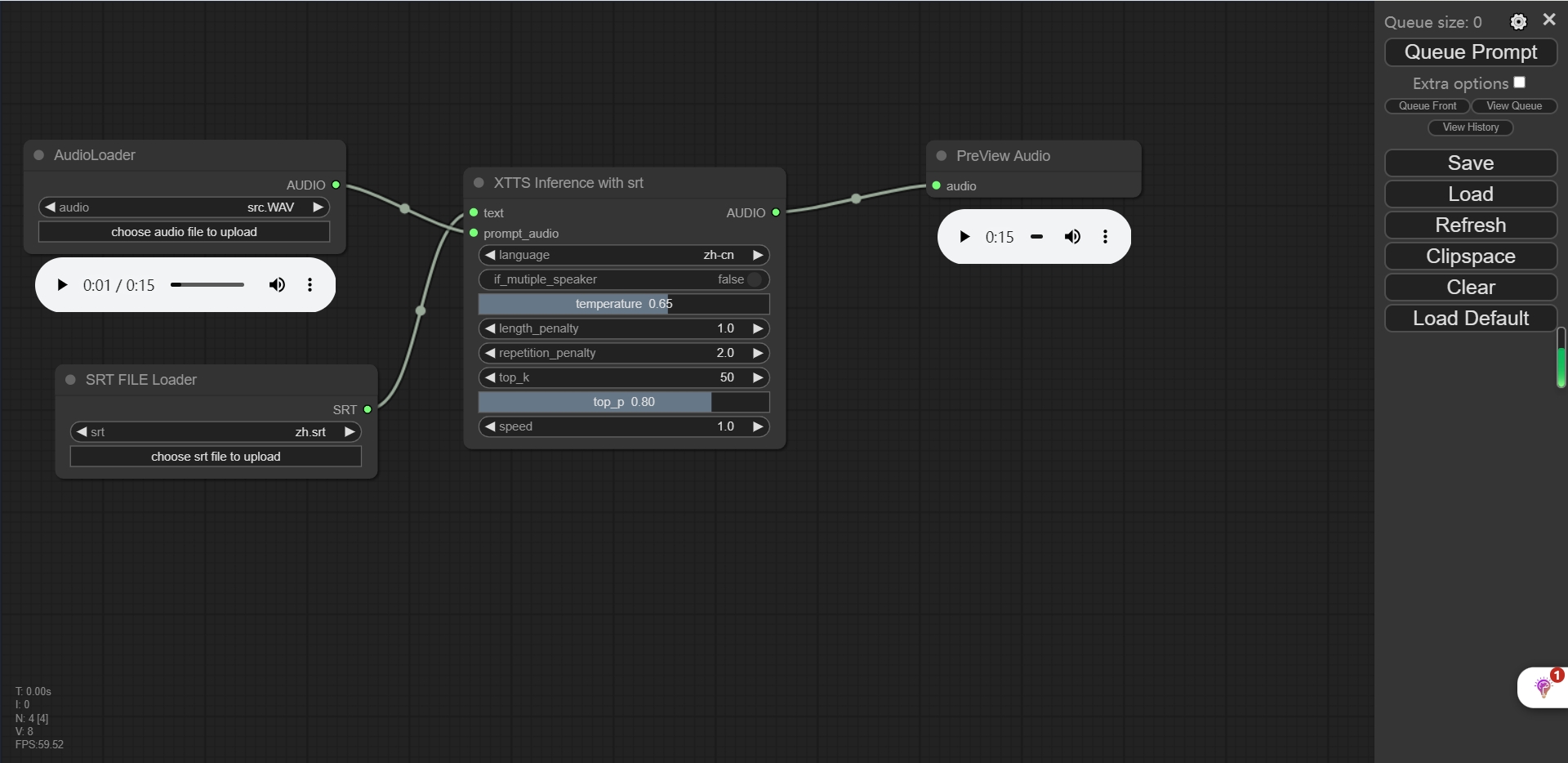
데모
temperature :자가 회귀 모델의 소프트 메이스 온도.
length_penalty : 자동 회귀 디코더에 적용되는 길이의 페널티는 더 많은 테어 출력을 생성합니다.
repetition_penalty : 디코딩 중에 자동 회귀 디코더가 반복되는 것을 방지하는 페널티는 긴 침묵 또는 "UHHHHHHS"등을 줄일 수 있습니다.
top_k : 더 낮은 값은 디코더가 더 많은 "가능성"(일명 보링) 출력을 생성한다는 것을 의미합니다.
top_p : 더 낮은 값은 디코더가 더 많은 "가능성"(일명 보링) 출력을 생성한다는 것을 의미합니다.
speed : 생성 된 오디오의 속도는 1.0입니다.


coqui-ai/tts


