OneForAll
1.0.0
종이 : https://arxiv.org/abs/2310.00149
저자 : Hao Liu, Jiarui Feng, Lecheng Kong, Ningyue Liang, Dacheng Tao, Yixin Chen, Muhan Zhang
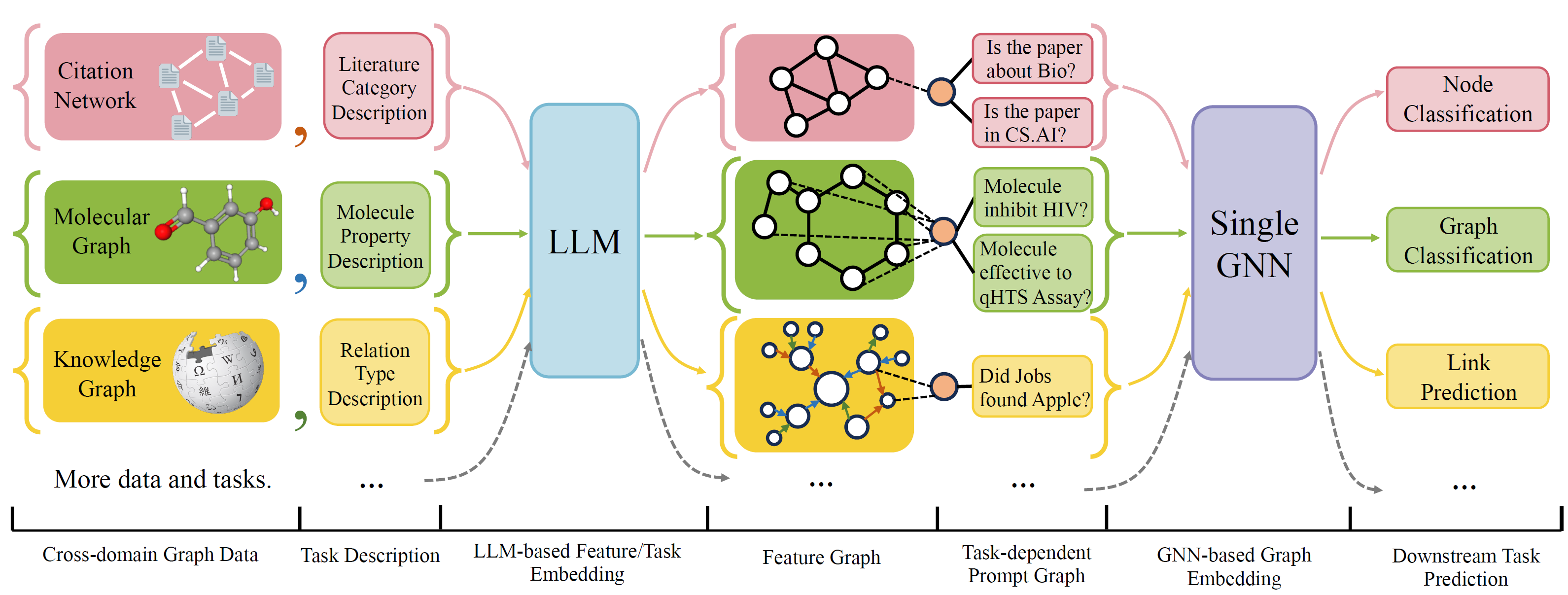
OFA는 단일 모델과 단일 매개 변수 세트로 광범위한 그래프 분류 작업을 해결할 수있는 일반적인 그래프 분류 프레임 워크입니다. 작업은 크로스 도메인 (예 : 인용 네트워크, 분자 그래프, ...) 및 크로스 작업 (예 : 소수의 샷, 제로 샷, 그래프 레벨, 노드 레브, ...)입니다.
자연 언어를 사용하여 모든 그래프를 설명하고 LLM을 사용하여 동일한 임베딩 공간에 모든 설명을 포함시켜 단일 모델을 사용하여 크로스 도메인 교육을 가능하게합니다.
OFA는 모든 작업 정보가 프롬프트 그래프로 변환된다는 프롬프트 패러다리엄을 제안합니다. 따라서 후속 모델은 모델 매개 변수와 아키텍처를 조정하지 않고도 작업 정보를 읽고 그에 따라 rehavent target을 예측할 수 있습니다. 따라서 단일 모델은 크로스 작업 일 수 있습니다.
OFA는 다른 소스 및 도메인에서 그래프 데이터 세트 목록을 선별하고 체계적인 찢어짐 프로토콜을 사용하여 그래프의 노드/에지를 설명했습니다. 우리는 OGB, Gimlet, Moleculenet, Graphllm 및 Villmow를 포함한 이전 작품에 감사드립니다.
Oneforall은 주요 개정을 거쳤으며, 여기서 코드를 정리하고 몇 가지보고 된 버그를 수정했습니다. 주요 업데이트는 다음과 같습니다.
이전에 저장소를 사용한 경우 이전 생성 된 기능/텍스트 파일을 가져 와서 삭제하고 재생하십시오. 불편을 드려 죄송합니다.
Conda를 사용하여 프로젝트 요구 사항을 설치하려면 :
conda env create -f environment.yml
수집 된 모든 데이터 세트에서 공동 엔드 투 엔드 실험의 경우 실행하십시오
python run_cdm.py --override e2e_all_config.yaml
모든 인수는 공간 분리 된 값에 의해 변경 될 수 있습니다.
python run_cdm.py --override e2e_all_config.yaml num_layers 7 batch_size 512 dropout 0.15 JK none
사용자는 ./e2e_all_config.yaml 에서 task_names 변수를 수정하여 교육 중에 포함되는 데이터 세트를 제어 할 수 있습니다. task_names , d_multiple 및 d_min_ratio 의 길이는 동일해야합니다. 또한 쉼표로 분리 된 값으로 명령 줄 인수에 지정할 수 있습니다.
예를 들어
python run_cdm.py task_names cora_link,arxiv d_multiple 1,1 d_min_ratio 1,1
OFA-IND는 지정할 수 있습니다
python run_cdm.py task_names cora_link d_multiple 1 d_min_ratio 1
소수 및 제로 샷 실험을 실행합니다
python run_cdm.py --override lr_all_config.yaml
각 작업에 대한 구성을 정의하며 각 작업 구성에는 여러 데이터 세트 구성이 포함되어 있습니다.
작업 구성은 ./configs/task_config.yaml 에 저장됩니다. 작업은 일반적으로 여러 데이터 세트 스플릿 (반드시 동일한 데이터 세트가 필요하지 않음)으로 구성됩니다. 예를 들어, 정기적 인 엔드 투 엔드 CORA 노드 분류 작업은 CORA 데이터 세트의 트레인 분할을 트레인 데이터 세트로, 유효한 데이터 세트 중 하나로 CORA 데이터 세트의 유효한 분할 및 마찬가지로 테스트 분할을 위해 분할됩니다. CORA의 트레인 분할을 유효성 검사/테스트 데이터 세트 중 하나로 지정하여 더 많은 검증/테스트를 가질 수도 있습니다. 구체적으로 작업 구성은 모양입니다
arxiv :
eval_pool_mode : mean
dataset : arxiv # dataset name
eval_set_constructs :
- stage : train # a task should have one and only one train stage dataset
split_name : train
- stage : valid
split_name : valid
dataset : cora # replace the default dataset for zero-shot tasks
- stage : valid
split_name : valid
- stage : test
split_name : test
- stage : test
split_name : train # test the train split 데이터 세트 구성은 ./configs/task_config.yaml 에 저장됩니다. 데이터 세트 구성은 데이터 세트 구성 방법을 정의합니다. 구체적으로,
arxiv :
task_level : e2e_node
preprocess : null # name of the preprocess function defined in task_constructor.py
construct : ConstructNodeCls # name of the dataset construction function defined in task_constructor.py
args : # additional arguments to construct function
walk_length : null
single_prompt_edge : True
eval_metric : acc # evaluation metric
eval_func : classification_func # evaluation function that process model output and batch to input to evaluator
eval_mode : max # evaluation mode (min/max)
dataset_name : arxiv # name of the OFAPygDataset
dataset_splitter : ArxivSplitter # splitting function defined in task_constructor.py
process_label_func : process_pth_label # name of process label function that transform original label to the binary labels
num_classes : 40 CORA/PubMed/Arxiv와 같은 데이터 세트를 구현하는 경우 데이터의 디렉토리를 데이터/Single_Graph/$ Customized_Data $ 아래에서 $ Customized_Data $와 디렉토리에서 Gen_Data.py를 구현하는 것이 좋습니다. Data/Cora/Gen_Data를 사용할 수 있습니다. PY 예로.
데이터가 구성되면 여기에 데이터 세트 이름을 등록하고 여기와 같은 스플리터를 구현해야합니다. 제로 샷/소수의 작업을 수행하는 경우 여기에서 제로 샷/몇 샷 분할을 생성 할 수 있습니다.
마지막으로 configs/data_config.yaml에 구성 항목을 등록하십시오. 예를 들어, 엔드 투 엔드 노드 분류의 경우
$data_name$ :
<< : *E2E-node
dataset_name : $data_name$
dataset_splitter : $splitter$
process_label_func : ... # usually processs_pth_label should work
num_classes : $number of classes$Process_Label_Func는 대상 레이블을 바이너리 레이블로 변환하고 작업이 Zero-Shot/File-Shot 인 경우 클래스 내부를 변환합니다. 여기서 클래스 노드 수가 고정되지 않은 경우. avalailable process_label_func의 목록이 여기에 있습니다. 모든 클래스 임베딩 및 올바른 레이블이 필요합니다. 출력은 튜플입니다.
더 많은 유연성을 원한다면 사용자 정의 된 데이터 세트를 추가하려면 ofapygdataset의 사용자 정의 서브 클래스를 구현해야합니다. 템플릿은 다음과 같습니다.
class CustomizedOFADataset ( OFAPygDataset ):
def gen_data ( self ):
"""
Returns a tuple of the following format
(data, text, extra)
data: a list of Pyg Data, if you only have a one large graph, you should still wrap it with the list.
text: a list of list of texts. e.g. [node_text, edge_text, label_text] this is will be converted to pooled vector representation.
extra: any extra data (e.g. split information) you want to save.
"""
def add_text_emb ( self , data_list , text_emb ):
"""
This function assigns generated embedding to member variables of the graph
data_list: data list returned in self.gen_data.
text_emb: list of torch text tensor corresponding to the returned text in self.gen_data. text_emb[0] = llm_encode(text[0])
"""
data_list [ 0 ]. node_text_feat = ... # corresponding node features
data_list [ 0 ]. edge_text_feat = ... # corresponding edge features
data_list [ 0 ]. class_node_text_feat = ... # class node features
data_list [ 0 ]. prompt_edge_text_feat = ... # edge features used in prompt node
data_list [ 0 ]. noi_node_text_feat = ... # noi node features, refer to the paper for the definition
return self . collate ( data_list )
def get_idx_split ( self ):
"""
Return the split information required to split the dataset, this optional, you can further split the dataset in task_constructor.py
"""
def get_task_map ( self ):
"""
Because a dataset can have multiple different tasks that requires different prompt/class text embedding. This function returns a task map that maps a task name to the desired text embedding. Specifically, a task map is of the following format.
prompt_text_map = {task_name1: {"noi_node_text_feat": ["noi_node_text_feat", [$Index in data[0].noi_node_text_feat$]],
"class_node_text_feat": ["class_node_text_feat",
[$Index in data[0].class_node_text_feat$]],
"prompt_edge_text_feat": ["prompt_edge_text_feat", [$Index in data[0].prompt_edge_text_feat$]]},
task_name2: similar to task_name 1}
Please refer to examples in data/ for details.
"""
return self . side_data [ - 1 ]
def get_edge_list ( self , mode = "e2e" ):
"""
Defines how to construct prompt graph
f2n: noi nodes to noi prompt node
n2f: noi prompt node to noi nodes
n2c: noi prompt node to class nodes
c2n: class nodes to noi prompt node
For different task/mode you might want to use different prompt graph construction, you can do so by returning a dictionary. For example
{"f2n":[1,0], "n2c":[2,0]} means you only want f2n and n2c edges, f2n edges have edge type 1, and its text embedding feature is data[0].prompt_edge_text_feat[0]
"""
if mode == "e2e_link" :
return { "f2n" : [ 1 , 0 ], "n2f" : [ 3 , 0 ], "n2c" : [ 2 , 0 ], "c2n" : [ 4 , 0 ]}
elif mode == "lr_link" :
return { "f2n" : [ 1 , 0 ], "n2f" : [ 3 , 0 ]}

