build your local ragstack chatbot
1.0.0
Bem-vindo a este workshop para construir e implantar seu próprio Enterprise Co-Pilot usando Retrieval Augmented Generation com DataStax Enterprise v7, um inferenciador local e Mistral, um modelo de linguagem grande local e aberto.
Este repositório se concentra na segurança, mantendo seus dados confidenciais dentro do firewall!
Por que?
Ele aproveita o DataStax RAGStack, que é uma pilha selecionada do melhor software de código aberto para facilitar a implementação do padrão RAG em aplicativos prontos para produção que usam DataStax Enterprise, Astra Vector DB ou Apache Cassandra como armazenamento de vetores.
O que você aprenderá:
? Como aproveitar o DataStax RAGStack para uso pronto para produção dos seguintes componentes:
? Como usar o Ollama como mecanismo de inferência local
? Como usar o Mistral como um Large Language Model (LLM) local e aberto para chatbots no estilo de perguntas e respostas
? Como usar o Streamlit para implantar facilmente seu aplicativo incrível!
Os slides da apresentação podem ser encontrados AQUI
Este workshop pressupõe que você tenha acesso a:
Nas próximas etapas prepararemos o repositório, DataStax Enterprise, um Jupyter Notebook e o Ollama Inference Engine com Ollama.
Primeiramente, precisaremos clonar este repositório em seu laptop de desenvolvimento local.
Abra o repositório build-your-local-ragstack-chatbot
Clique em Use this template -> Ceate new repository da seguinte forma:
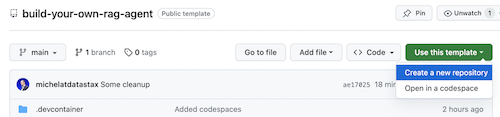
Agora selecione sua conta github e nomeie o novo repositório. O ideal é definir também a descrição. Clique em Create repository
Legal! Você acabou de criar uma cópia em sua própria conta Gihub!
cd para um diretório sensato (como /projects ou algo assim);git clone <url-to-your-repo>cd para o seu novo diretório!E você está pronto para o rock and roll! ?
É útil criar um ambiente virtual . Use o abaixo para configurá-lo:
python3 -m venv myenv
Em seguida, ative-o da seguinte forma:
source myenv/bin/activate # on Linux/Mac
myenvScriptsactivate.bat # on Windows
Agora você pode começar a instalar os pacotes necessários:
pip3 install -r requirements.txt
Execute o DSE 7 de qualquer uma destas duas maneiras em uma nova janela de terminal:
docker-compose up
Isso usa o arquivo docker-compose.yml na raiz deste repositório, que também iniciará convenientemente o Jupyter Interpreter.
O DataStax estará rodando em http://localhost:9042 e o Jupyter estará acessível navegando até http://localhost:8888
Existem vários mecanismos de inferência. Você pode optar pelo LM Studio, que possui uma interface de usuário agradável. Neste caderno, usaremos Ollama.
ollama run mistral em uma nova janela de terminalCaso tudo isso falhe, devido às limitações de RAM, você pode optar por usar o tinyllama como modelo.
Para iniciar este workshop, primeiro experimentaremos os conceitos do caderno fornecido. Presumimos que você executará a partir de um contêiner Jupyter Docker. Caso contrário, altere os nomes dos hosts de host.docker.internal para localhost .
Este caderno mostra as etapas a serem seguidas para usar o DataStax Enterprise Vector Store como um meio de tornar as interações LLM significativas e sem alucinações. A abordagem adotada aqui é a Geração Aumentada de Recuperação.
Você aprenderá:
Navegue até http://localhost:8888 e abra o notebook que está disponível na raiz chamado Build_Your_Own_RAG_Meetup.ipnb .
Neste workshop usaremos Streamlit, que é uma estrutura incrivelmente simples de usar para criar aplicações web front-end.
Para começar, vamos criar um aplicativo hello world da seguinte maneira:
import streamlit as st
# Draw a title and some markdown
st . markdown ( """# Your Enterprise Co-Pilot
Generative AI is considered to bring the next Industrial Revolution.
Why? Studies show a **37% efficiency boost** in day to day work activities!
### Security and safety
This Chatbot is safe to work with sensitive data. Why?
- First of all it makes use of [Ollama, a local inference engine](https://ollama.com);
- On top of the inference engine, we're running [Mistral, a local and open Large Language Model (LLM)](https://mistral.ai/);
- Also the LLM does not contain any sensitive or enterprise data, as there is no way to secure it in a LLM;
- Instead, your sensitive data is stored securely within the firewall inside [DataStax Enterprise v7 Vector Database](https://www.datastax.com/blog/get-started-with-the-datastax-enterprise-7-0-developer-vector-search-preview);
- And lastly, the chains are built on [RAGStack](https://www.datastax.com/products/ragstack), an enterprise version of Langchain and LLamaIndex, supported by [DataStax](https://www.datastax.com/).""" )
st . divider () O primeiro passo é importar o pacote streamlit. Em seguida, chamamos st.markdown para escrever um título e, por último, escrevemos algum conteúdo para a página web.
Para iniciar este aplicativo localmente, você precisará instalar a dependência streamlit da seguinte maneira (o que já deve ser feito como parte dos pré-requisitos):
pip install streamlitAgora execute o aplicativo:
streamlit run app_1.pyIsso iniciará o servidor de aplicativos e o levará à página da web que acabou de criar.
Simples, não é? ?
Nesta etapa começaremos a preparar o aplicativo para permitir a interação do chatbot com um usuário. Usaremos os seguintes componentes Streamlit: 1. 2. st.chat_input para que um usuário permita inserir uma pergunta 2. st.chat_message('human') para desenhar a entrada do usuário 3. st.chat_message('assistant') para desenhar a resposta do chatbot
Isso resulta no seguinte código:
# Draw the chat input box
if question := st . chat_input ( "What's up?" ):
# Draw the user's question
with st . chat_message ( 'human' ):
st . markdown ( question )
# Generate the answer
answer = f"""You asked: { question } """
# Draw the bot's answer
with st . chat_message ( 'assistant' ):
st . markdown ( answer ) Experimente usando app_2.py e comece da seguinte maneira.
Se o seu aplicativo anterior ainda estiver em execução, basta eliminá-lo pressionando ctrl-c antes.
streamlit run app_2.pyAgora digite uma pergunta e digite outra novamente. Você verá que apenas a última pergunta é mantida.
Por que???
Isso ocorre porque o Streamlit redesenhará a tela inteira repetidamente com base na entrada mais recente. Como não estamos lembrando das perguntas, apenas a última é exibida.
Nesta etapa faremos questão de acompanhar as perguntas e respostas para que a cada redesenho o histórico seja mostrado.
Para fazer isso, seguiremos os próximos passos:
st.session_state chamado messagesst.session_state chamado messagesfor message in st.session_state.messages Essa abordagem funciona porque session_state tem estado em todas as execuções do Streamlit.
Confira o código completo em app_3.py.
Como você verá, usamos um dicionário para armazenar tanto a role (que pode ser Humana quanto a IA) e a question ou answer . Acompanhar a função é importante, pois isso desenhará a imagem correta no navegador.
Execute-o com:
streamlit run app_3.pyAgora adicione várias perguntas e você verá que elas serão redesenhadas na tela sempre que o Streamlit for executado novamente. ?
Aqui faremos um link para o trabalho que fizemos usando o Jupyter Notebook e integraremos a pergunta com uma chamada para o Mistral Chat Model.
Lembra que o Streamlit executa novamente o código sempre que um usuário interage? Por isso, usaremos o cache de dados e recursos no Streamlit para que a conexão seja configurada apenas uma vez. Usaremos @st.cache_data() e @st.cache_resource() para definir o cache. cache_data é normalmente usado para estruturas de dados. cache_resource é usado principalmente para recursos como bancos de dados.
Isso resulta no código a seguir para configurar o modelo de prompt e bate-papo:
# Cache prompt for future runs
@ st . cache_data ()
def load_prompt ():
template = """You're a helpful AI assistent tasked to answer the user's questions.
You're friendly and you answer extensively with multiple sentences. You prefer to use bulletpoints to summarize.
QUESTION:
{question}
YOUR ANSWER:"""
return ChatPromptTemplate . from_messages ([( "system" , template )])
prompt = load_prompt ()
# Cache Mistral Chat Model for future runs
@ st . cache_resource ()
def load_chat_model ():
# parameters for ollama see: https://api.python.langchain.com/en/latest/chat_models/langchain_community.chat_models.ollama.ChatOllama.html
# num_ctx is the context window size
return ChatOllama (
model = "mistral:latest" ,
num_ctx = 18192 ,
base_url = st . secrets [ 'OLLAMA_ENDPOINT' ]
)
chat_model = load_chat_model ()Em vez da resposta estática que usamos nos exemplos anteriores, passaremos agora a chamar a Chain:
# Generate the answer by calling Mistral's Chat Model
inputs = RunnableMap ({
'question' : lambda x : x [ 'question' ]
})
chain = inputs | prompt | chat_model
response = chain . invoke ({ 'question' : question })
answer = response . contentConfira o código completo em app_4.py.
Antes de continuarmos, temos que fornecer OLLAMA_ENDPOINT em ./streamlit/secrets.toml . Há um exemplo fornecido em secrets.toml.example :
# Ollama/Mistral Endpoint
OLLAMA_ENDPOINT = " http://localhost:11434 "Para iniciar este aplicativo localmente, você precisará instalar o RAGStack que contém uma versão estável do LangChain e todas as dependências (o que já deve ser feito como parte dos pré-requisitos):
pip install ragstackAgora execute o aplicativo:
streamlit run app_4.pyAgora você pode iniciar sua interação de perguntas e respostas com o Chatbot. É claro que como não há integração com o DataStax Enterprise Vector Store, não haverá respostas contextualizadas. Como ainda não há streaming integrado, dê ao agente um pouco de tempo para dar a resposta completa de uma vez.
Vamos começar com a pergunta:
What does Daniel Radcliffe get when he turns 18?
Como você verá, receberá uma resposta muito genérica sem as informações disponíveis nos dados da CNN.
Agora as coisas ficam realmente interessantes! Nesta etapa iremos integrar o DataStax Enterprise Vector Store para fornecer contexto em tempo real para o modelo de chat. Etapas tomadas para implementar a geração aumentada de recuperação:
Reutilizaremos os dados da CNN que inserimos graças ao notebook.
Para habilitar isso, primeiro precisamos configurar uma conexão com o DataStax Enterprise Vector Store:
# Cache the DataStax Enterprise Vector Store for future runs
@ st . cache_resource ( show_spinner = 'Connecting to Datastax Enterprise v7 with Vector Support' )
def load_vector_store ():
# Connect to DSE
cluster = Cluster (
[ st . secrets [ 'DSE_ENDPOINT' ]]
)
session = cluster . connect ()
# Connect to the Vector Store
vector_store = Cassandra (
session = session ,
embedding = HuggingFaceEmbeddings (),
keyspace = st . secrets [ 'DSE_KEYSPACE' ],
table_name = st . secrets [ 'DSE_TABLE' ]
)
return vector_store
vector_store = load_vector_store ()
# Cache the Retriever for future runs
@ st . cache_resource ( show_spinner = 'Getting retriever' )
def load_retriever ():
# Get the retriever for the Chat Model
retriever = vector_store . as_retriever (
search_kwargs = { "k" : 5 }
)
return retriever
retriever = load_retriever ()A única outra coisa que precisamos fazer é alterar a Chain para incluir uma chamada para a Vector Store:
# Generate the answer by calling Mistral's Chat Model
inputs = RunnableMap ({
'context' : lambda x : retriever . get_relevant_documents ( x [ 'question' ]),
'question' : lambda x : x [ 'question' ]
})Confira o código completo em app_5.py.
Antes de continuarmos, temos que fornecer DSE_ENDPOINT , DSE_KEYSPACE e DSE_TABLE em ./streamlit/secrets.toml . Há um exemplo fornecido em secrets.toml.example :
# DataStax Enterprise Endpoint
DSE_ENDPOINT = " localhost "
DSE_KEYSPACE = " default_keyspace "
DSE_TABLE = " dse_vector_table "E execute o aplicativo:
streamlit run app_5.pyVamos novamente fazer a pergunta:
What does Daniel Radcliffe get when he turns 18?
Como você verá, agora você receberá uma resposta bastante contextual, pois a Vector Store fornece dados relevantes da CNN para o modelo de chat.
Que legal seria ver a resposta aparecer na tela à medida que é gerada! Bem, isso é fácil.
Primeiro de tudo, criaremos um Streaming Call Back Handler que é chamado a cada nova geração de token da seguinte forma:
# Streaming call back handler for responses
class StreamHandler ( BaseCallbackHandler ):
def __init__ ( self , container , initial_text = "" ):
self . container = container
self . text = initial_text
def on_llm_new_token ( self , token : str , ** kwargs ):
self . text += token
self . container . markdown ( self . text + "▌" )A seguir explicamos o modelo de chat para tornar usuário do StreamHandler:
response = chain . invoke ({ 'question' : question }, config = { 'callbacks' : [ StreamHandler ( response_placeholder )]}) O response_placeholer no código acima define o local onde os tokens precisam ser escritos. Podemos criar esse espaço callint st.empty() da seguinte maneira:
# UI placeholder to start filling with agent response
with st . chat_message ( 'assistant' ):
response_placeholder = st . empty ()Confira o código completo em app_6.py.
E execute o aplicativo:
streamlit run app_6.pyAgora você verá que a resposta será escrita em tempo real na janela do navegador.
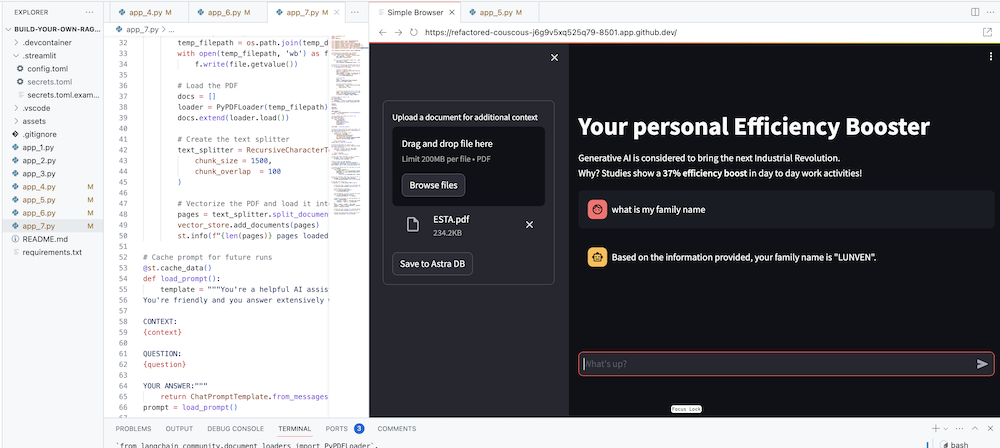
O objetivo final, claro, é adicionar o contexto da sua própria empresa ao agente. Para fazer isso, adicionaremos uma caixa de upload que permite fazer upload de arquivos PDF que serão usados para fornecer uma resposta significativa e contextual!
Primeiro precisamos de um formulário de upload que seja simples de criar com Streamlit:
# Include the upload form for new data to be Vectorized
with st . sidebar :
with st . form ( 'upload' ):
uploaded_file = st . file_uploader ( 'Upload a document for additional context' , type = [ 'pdf' ])
submitted = st . form_submit_button ( 'Save to DataStax Enterprise' )
if submitted :
vectorize_text ( uploaded_file )Agora precisamos de uma função para carregar o PDF e ingeri-lo no DataStax Enterprise enquanto vetoriza o conteúdo.
# Function for Vectorizing uploaded data into DataStax Enterprise
def vectorize_text ( uploaded_file , vector_store ):
if uploaded_file is not None :
# Write to temporary file
temp_dir = tempfile . TemporaryDirectory ()
file = uploaded_file
temp_filepath = os . path . join ( temp_dir . name , file . name )
with open ( temp_filepath , 'wb' ) as f :
f . write ( file . getvalue ())
# Load the PDF
docs = []
loader = PyPDFLoader ( temp_filepath )
docs . extend ( loader . load ())
# Create the text splitter
text_splitter = RecursiveCharacterTextSplitter (
chunk_size = 1500 ,
chunk_overlap = 100
)
# Vectorize the PDF and load it into the DataStax Enterprise Vector Store
pages = text_splitter . split_documents ( docs )
vector_store . add_documents ( pages )
st . info ( f" { len ( pages ) } pages loaded." )Confira o código completo em app_7.py.
Para iniciar este aplicativo localmente, você precisará instalar a dependência do PyPDF da seguinte maneira (o que já deve ser feito como parte dos pré-requisitos):
pip install pypdfE execute o aplicativo:
streamlit run app_7.pyAgora carregue um documento PDF (quanto mais, melhor) que seja relevante para você e comece a fazer perguntas sobre ele. Você verá que as respostas serão relevantes, significativas e contextuais! ? Veja a mágica acontecer!