No círculo da IA, o vencedor do Prêmio Turing, Yann Lecun, é um típico caso atípico.
Embora muitos especialistas técnicos acreditem firmemente que, ao longo do percurso técnico actual, a realização da AGI é apenas uma questão de tempo, Yann Lecun levantou repetidamente objecções.
Em debates acalorados com seus pares, ele disse mais de uma vez que o atual caminho da tecnologia dominante não pode nos levar à AGI, e mesmo o nível atual de IA não é tão bom quanto um gato.
Vencedor do Prêmio Turing, cientista-chefe de IA da Meta, professor da Universidade de Nova York, etc. Esses títulos deslumbrantes e grande experiência prática na linha de frente tornam impossível para qualquer um de nós ignorar os insights deste especialista em IA.

Então, o que Yann LeCun pensa sobre o futuro da IA? Num discurso público recente, ele mais uma vez elaborou o seu ponto de vista: a IA nunca poderá atingir uma inteligência próxima do nível humano, baseando-se apenas no treino de texto.
Algumas visualizações são as seguintes:
1. No futuro, as pessoas geralmente usarão óculos inteligentes ou outros tipos de dispositivos inteligentes. Esses dispositivos terão sistemas de assistente integrados para formar equipes virtuais pessoais inteligentes para melhorar a criatividade e a eficiência pessoais.
2. O objectivo dos sistemas inteligentes não é substituir os humanos, mas sim melhorar a inteligência humana para que as pessoas possam trabalhar de forma mais eficiente.
3. Até mesmo um gato de estimação tem um modelo em seu cérebro que é mais complexo do que qualquer sistema de IA pode construir.
4. O FAIR basicamente não se concentra mais em modelos linguísticos, mas avança em direção ao objetivo de longo prazo dos sistemas de IA da próxima geração.
5. Os sistemas de IA não podem alcançar uma inteligência de nível próximo do humano treinando apenas com dados de texto.
6. Yann Lecun sugeriu abandonar os modelos generativos, modelos probabilísticos, aprendizagem contrastiva e aprendizagem por reforço, e em vez disso adoptar a arquitectura JEPA e modelos baseados em energia, acreditando que estes métodos têm maior probabilidade de promover o desenvolvimento da IA.
7. Embora as máquinas acabem por ultrapassar a inteligência humana, elas serão controladas porque são orientadas por objectivos.
Curiosamente, houve um episódio antes do início do discurso.
Quando o anfitrião apresentou LeCun, ele o chamou de cientista-chefe de IA do Facebook AI Research Institute (FAIR) .
A este respeito, LeCun esclareceu antes do discurso que o “F” em FAIR já não representa o Facebook, mas significa “ Fundamental ”.
O texto original do discurso abaixo foi compilado pela APPSO e foi editado. Por fim, o link do vídeo original está anexado: https://www.youtube.com/watch?v=4DsCtgtQlZU
A IA não entende o mundo tão bem quanto o seu gato
Ok, então vou falar sobre IA em nível humano e como chegaremos lá e por que não chegaremos lá.
Primeiro, realmente precisamos de IA em nível humano.
Porque no futuro, uma delas é que a maioria de nós usará óculos inteligentes ou outros tipos de dispositivos. Estaremos conversando com esses dispositivos, e esses sistemas hospedarão assistentes, talvez mais de um, talvez um conjunto completo de assistentes.
Isso fará com que cada um de nós tenha essencialmente uma equipe virtual inteligente trabalhando para nós.
Portanto, todos se tornarão “chefes”, mas esses “funcionários” não são humanos reais. Precisamos de construir sistemas como este, basicamente para aumentar a inteligência humana e tornar as pessoas mais criativas e eficientes.

Mas, para isso, precisamos de máquinas que possam compreender o mundo, lembrar-se das coisas, ter intuição e bom senso, e raciocinar e planear ao mesmo nível que os humanos.
Embora você possa ter ouvido alguns proponentes dizerem que os sistemas atuais de IA não possuem esses recursos. Portanto, precisamos de tempo para aprender como modelar o mundo, para ter modelos mentais de como o mundo funciona.
Praticamente todos os animais possuem esse modelo. Seu gato deve ter um modelo mais complexo do que qualquer sistema de IA pode construir ou projetar.

Precisamos de um sistema que tenha uma memória persistente que os modelos de linguagem atuais (LLMs) não possuem, um sistema que possa planejar sequências complexas de ações que os sistemas atuais não podem realizar e um sistema que seja controlável e seguro.
Portanto, proporei uma arquitetura chamada IA orientada por objetivos. Escrevi um artigo de visão sobre isso há cerca de dois anos e publiquei-o. Muitas pessoas na FAIR estão trabalhando duro para tornar este plano uma realidade.
A FAIR trabalhou em mais projetos de aplicativos no passado, mas a Meta criou uma divisão de produtos chamada Generative AI (Gen AI) há um ano e meio para se concentrar em produtos de IA.
Eles realizam pesquisa e desenvolvimento aplicados, então agora o FAIR foi redirecionado para o objetivo de longo prazo dos sistemas de IA da próxima geração. Basicamente, não nos concentramos mais em modelos de linguagem.
O sucesso da IA, incluindo os grandes modelos de linguagem (LLMs) , e especialmente o sucesso de muitos outros sistemas ao longo dos últimos 5 ou 6 anos, depende de uma série de técnicas, incluindo, claro, a aprendizagem auto-supervisionada.

O núcleo da aprendizagem auto-supervisionada é treinar um sistema não para qualquer tarefa específica, mas tentar representar os dados de entrada de uma boa maneira. Uma maneira de conseguir isso é por meio da recuperação de danos e reconstrução.
Assim, você pode pegar um trecho de texto e corrompê-lo removendo algumas palavras ou alterando outras palavras. Este processo pode ser usado para texto, sequências de DNA, proteínas ou qualquer outra coisa, e até mesmo, até certo ponto, imagens. Em seguida, você treina uma enorme rede neural para reconstruir a entrada completa, a versão não corrompida.
Este é um modelo generativo porque tenta reconstruir o sinal original.
Então, a caixa vermelha é como uma função de custo, certo? Calcula a distância entre a entrada Y e a saída reconstruída y, e este é o parâmetro a ser minimizado durante o processo de aprendizagem. Neste processo, o sistema aprende uma representação interna da entrada, que pode ser utilizada para diversas tarefas subsequentes.
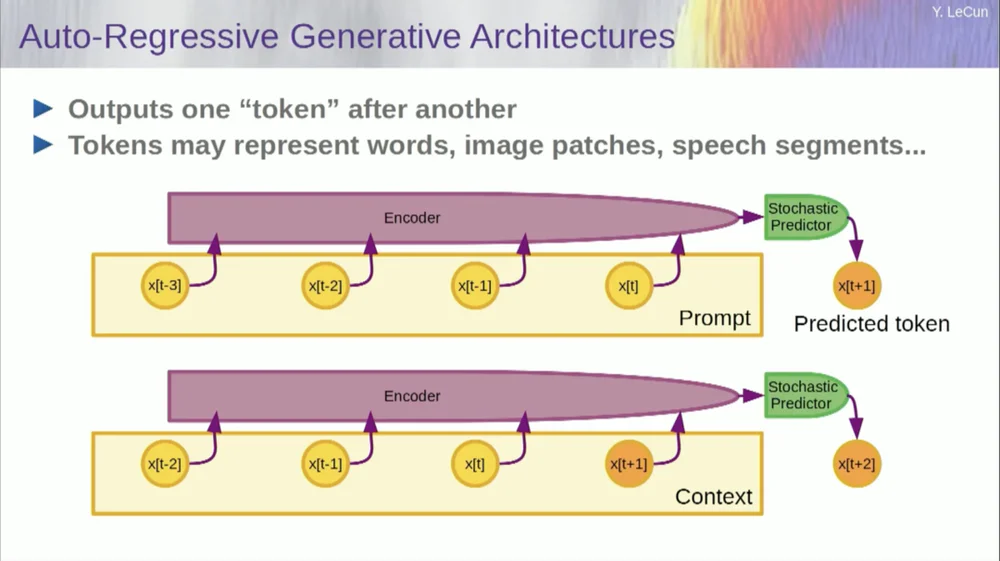
Claro, isso pode ser usado para prever palavras no texto, que é o que a previsão autorregressiva faz.
Os modelos de linguagem são um caso especial disso, onde a arquitetura é projetada de tal forma que, ao prever um item, um token ou uma palavra, ela só pode olhar para os outros tokens à sua esquerda.
Não pode olhar para o futuro. Se você treinar um sistema corretamente, mostrar-lhe o texto e pedir-lhe para prever a próxima palavra ou o próximo token no texto, então você poderá usar o sistema para prever a próxima palavra. Então você adiciona a próxima palavra à entrada, prevê a segunda palavra e adiciona-a à entrada, prevê a terceira palavra.
Esta é uma previsão autorregressiva .
Isso é o que os LLMs fazem, não é um conceito novo, existe desde a época de Shannon , desde os anos 50, que foi há muito tempo, mas a mudança é que agora temos aquelas arquiteturas de redes neurais massivas, você pode treinar em grandes quantidades de dados e recursos parecerão emergir dele.
Mas este tipo de previsão autoregressiva tem algumas limitações importantes e não há aqui nenhum raciocínio real no sentido habitual.
Outra limitação é que isso só funciona para dados na forma de objetos discretos, símbolos, tokens, palavras, etc., basicamente coisas que podem ser discretizadas.
Ainda nos falta algo importante quando se trata de alcançar a inteligência de nível humano.
Não estou necessariamente falando de inteligência de nível humano aqui, mas até mesmo seu gato ou cachorro pode realizar alguns feitos incríveis que estão além do alcance dos atuais sistemas de IA.

Qualquer criança de 10 anos pode aprender a limpar a mesa e encher a máquina de lavar louça de uma só vez, certo? Não há necessidade de praticar ou algo assim, certo?
São necessárias cerca de 20 horas de prática para um jovem de 17 anos aprender a dirigir.
Ainda não temos carros autônomos de nível 5 e certamente não temos robôs domésticos capazes de limpar mesas e encher máquinas de lavar louça.
A IA nunca alcançará a inteligência próxima do nível humano treinando apenas em texto
Então, estamos realmente perdendo algo importante que, de outra forma, seríamos capazes de fazer essas coisas com sistemas de IA.
Continuamos encontrando algo chamado Paradoxo de Moravec , que diz que coisas que nos parecem triviais e nem mesmo consideradas inteligentes são na verdade muito difíceis de fazer com máquinas, e coisas como manipulação O pensamento abstrato complexo de alto nível, como a linguagem, parece ser muito simples para máquinas, e o mesmo se aplica a coisas como jogar xadrez e Go.
Talvez um dos motivos seja este.
Um modelo de linguagem grande (LLM) normalmente é treinado em 20 trilhões de tokens.
Um token equivale basicamente a três quartos de uma palavra, em média. Portanto, existem 1,5×10^13 palavras no total. Cada token tem cerca de 3B, normalmente, isso requer 6×1013 bytes.
Levaria cerca de algumas centenas de milhares de anos para qualquer um de nós ler isso, certo? Isto é basicamente todo o texto público na Internet combinado.

Mas pense numa criança de quatro anos que esteve acordada durante um total de 16.000 horas. Temos 2 milhões de fibras nervosas ópticas entrando em nosso cérebro. Cada fibra nervosa transmite dados a cerca de 1B por segundo, talvez meio byte por segundo. Algumas estimativas dizem que isso pode ser de 3 bilhões por segundo.
Não importa, é uma ordem de magnitude de qualquer maneira.
Essa quantidade de dados é de aproximadamente 10 elevado à 14ª potência de bytes, que é quase a mesma ordem de magnitude do LLM. Assim, em quatro anos, uma criança de quatro anos viu tantos dados visuais quanto os maiores modelos de linguagem treinados em texto disponível publicamente em toda a Internet.
Usando os dados como ponto de partida, isso nos diz várias coisas.
Primeiro, isso nos diz que nunca alcançaremos uma inteligência próxima do nível humano simplesmente treinando em texto. Isso simplesmente não vai acontecer.
Em segundo lugar, a informação visual é muito redundante. Cada fibra do nervo óptico transmite 1B de informação por segundo, que já está comprimida de 100 para 1 em comparação com os fotorreceptores da sua retina.
Existem aproximadamente 60 milhões a 100 milhões de fotorreceptores em nossas retinas. Esses fotorreceptores são comprimidos em 1 milhão de fibras nervosas pelos neurônios na parte frontal da retina. Portanto, já existe uma compactação de 100 para 1. Então, quando chega ao cérebro, a informação se expande cerca de 50 vezes.
Então o que estou medindo são informações compactadas, mas ainda são muito redundantes. E redundância é, na verdade, o que a aprendizagem autossupervisionada exige. O aprendizado autossupervisionado só aprenderá coisas úteis com dados redundantes. Se os dados forem altamente compactados, o que significa que se tornam ruído aleatório, você não poderá aprender nada.
Você precisa de redundância para aprender qualquer coisa. Você precisa aprender a estrutura subjacente dos dados. Portanto, precisamos treinar o sistema para aprender o bom senso e a física assistindo a vídeos ou vivendo no mundo real.
A ordem das minhas palavras pode ser um pouco confusa. Quero principalmente dizer o que é essa arquitetura de inteligência artificial orientada por objetivos. É muito diferente dos LLMs ou neurônios feedforward porque o processo de inferência não passa apenas por uma série de camadas de uma rede neural, mas na verdade executa um algoritmo de otimização.
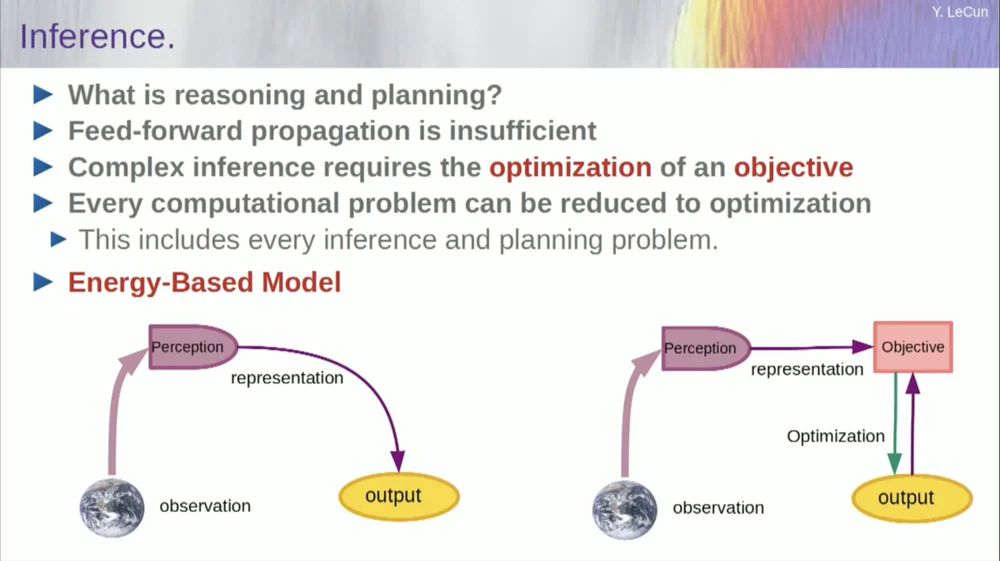
Conceitualmente, é assim.
Um processo feedforward é aquele em que as observações passam por um sistema perceptual. Por exemplo, se você tiver uma série de camadas de rede neural e produzir uma saída, então, para qualquer entrada única, você poderá ter apenas uma saída, mas em muitos casos, para uma percepção, pode haver múltiplas interpretações de saída possíveis. Você precisa de um processo de mapeamento que não apenas calcule a funcionalidade, mas que forneça várias saídas para uma única entrada. A única maneira de conseguir isso é através de funções implícitas.
Basicamente, a caixa vermelha no lado direito desta estrutura de meta representa uma função que basicamente mede a compatibilidade entre uma entrada e sua saída proposta e, em seguida, calcula a saída encontrando o valor de saída que é mais compatível com a entrada. Você pode imaginar que esse objetivo é algum tipo de função energética e está minimizando essa energia com a produção como uma variável.
Você pode ter várias soluções e alguma maneira de lidar com essas múltiplas soluções. Isto é verdade para o sistema perceptivo humano. Se você tiver múltiplas interpretações de uma percepção específica, seu cérebro alternará automaticamente entre essas interpretações. Portanto, há algumas evidências de que esse tipo de coisa acontece.
Mas deixe-me voltar à arquitetura. Portanto, aproveite este princípio de raciocínio por otimização. Aqui estão as suposições, por assim dizer, sobre o modo como a mente humana funciona. Você faz observações no mundo. O sistema perceptivo dá uma ideia do estado atual do mundo. Mas é claro que isso apenas lhe dá uma ideia do estado do mundo que você pode perceber atualmente.
Você pode ter algumas ideias lembradas sobre o estado do resto do mundo. Isto pode ser combinado com o conteúdo da memória e alimentar um modelo do mundo.
O que é um modelo? Um modelo de mundo é um modelo mental de como você se comporta no mundo, então você pode imaginar uma sequência de ações que pode realizar, e seu modelo de mundo lhe permitirá prever o impacto dessas sequências de ações no mundo.
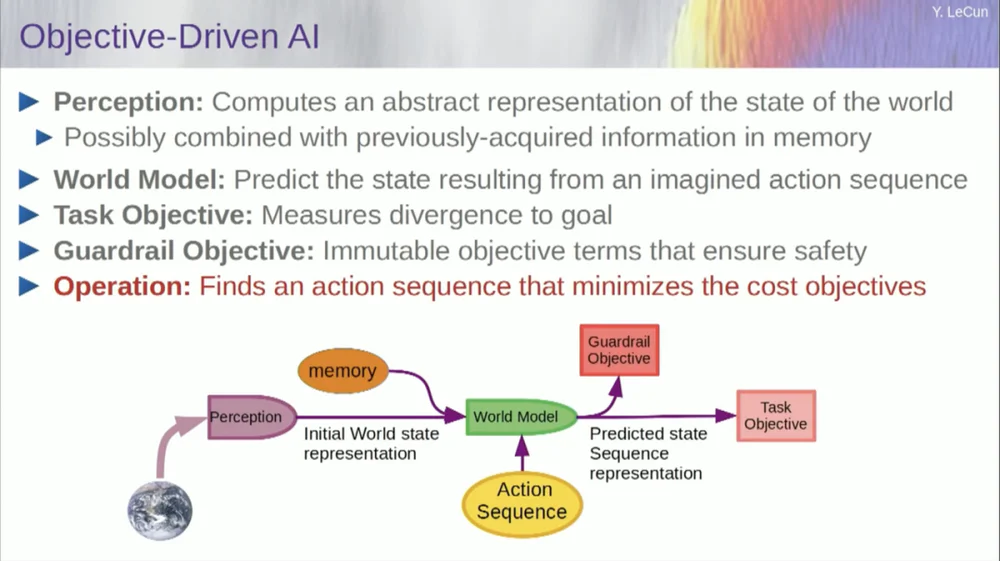
Portanto, a caixa verde representa o modelo mundial no qual você alimenta uma sequência hipotética de ações que prevê qual será o estado final do mundo, ou toda a trajetória que você prevê que acontecerá no mundo.
Você combina isso com um conjunto de funções objetivo. Um dos objetivos é medir o quão bem o objetivo foi alcançado, se a tarefa foi concluída, e talvez um conjunto de outros objetivos que sirvam como margens de segurança, medindo basicamente até que ponto a trajetória seguida ou a ação tomada não representa perigo para o robô. ou pessoas ao redor da máquina, etc., espere.
Então agora o processo de raciocínio (ainda não falei sobre aprendizagem) é apenas raciocínio e consiste em encontrar sequências de ações que minimizem esses objetivos, encontrar sequências de ações que minimizem esses objetivos. Este é o processo de raciocínio.
Portanto, não é apenas um processo feedforward. Você poderia fazer isso procurando opções discretas, mas isso não é eficiente. Uma abordagem melhor é garantir que todas essas caixas sejam diferenciáveis, você pode retropropagar o gradiente através delas e então atualizar a sequência de ações por meio da descida do gradiente.

Agora, esta ideia não é realmente nova e já existe há mais de 60 anos, talvez até mais tempo. Primeiro, deixe-me falar sobre as vantagens de usar um modelo mundial para esse tipo de raciocínio. A vantagem é que você pode concluir novas tarefas sem necessidade de aprendizado.
Fazemos isso de vez em quando. Quando nos deparamos com uma situação nova, pensamos sobre ela, imaginamos as consequências de nossas ações, e então tomamos uma sequência de ações que atingirão nosso objetivo (seja ele qual for) . Não precisamos aprender para realizar essa tarefa. , podemos planejar. Então isso é basicamente planejamento.
Você pode resumir a maioria das formas de raciocínio à otimização. Portanto, o processo de inferência por meio da otimização é inerentemente mais poderoso do que simplesmente percorrer múltiplas camadas de uma rede neural. Como eu disse, essa ideia de raciocínio por meio da otimização existe há mais de 60 anos.
No campo da teoria de controle ótimo, isso é chamado de controle preditivo de modelo.
Você tem um modelo de sistema que deseja controlar, como um foguete, avião ou robô. Você pode imaginar usar seu modelo de mundo para calcular os efeitos de uma série de comandos de controle.
Aí você otimiza essa sequência para que o movimento atinja os resultados desejados. Todo o planejamento de movimento na robótica clássica é feito dessa maneira, e isso não é novidade. A novidade aqui é que aprenderemos um modelo do mundo e o sistema perceptivo extrairá uma representação abstrata apropriada.
Agora, antes de entrar em um exemplo de como executar este sistema, você pode construir um sistema geral de IA com todos estes componentes: um modelo mundial, uma função de custo que pode ser configurada para a tarefa em questão, um módulo de otimização (ou seja, otimizar verdadeiramente, encontrar o módulo fornecido que determina a sequência ideal de ações para o modelo mundial) , memória de curto prazo, sistema perceptual, etc.
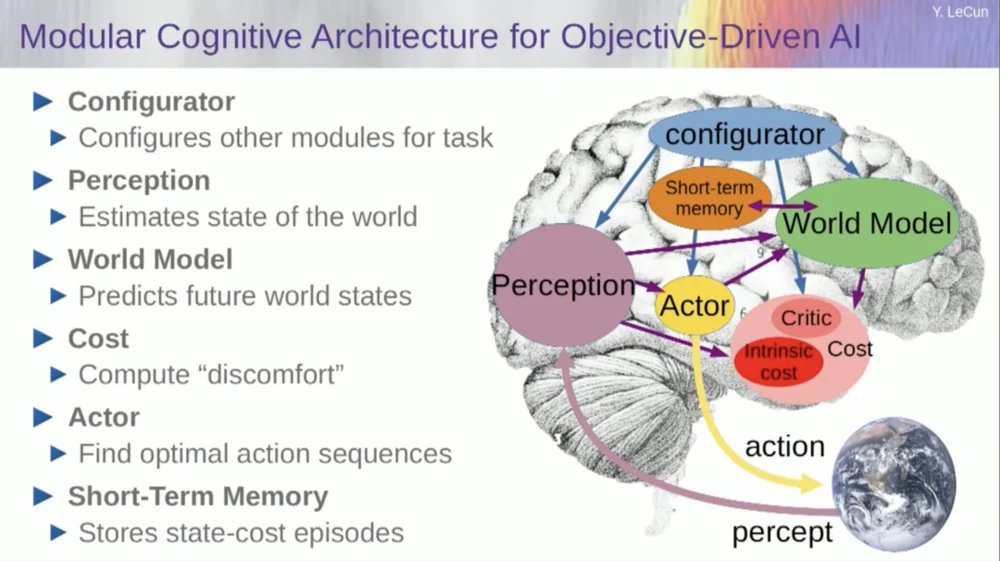
Então, como isso funciona? Se a sua ação não é uma ação única, mas uma sequência de ações, e o seu modelo mundial é na verdade um sistema que lhe diz, dado o estado mundial no tempo T e ações possíveis, prever o estado mundial no tempo T+1.
Você deseja prever qual efeito uma sequência de duas ações terá nesta situação. Você pode executar seu modelo de mundo várias vezes para conseguir isso.
Obtenha a representação inicial do estado mundial, insira a suposição de zero para a ação, use o modelo para prever o próximo estado, depois execute a ação um, calcule o próximo estado, calcule o custo e, em seguida, use retropropagação e métodos de otimização baseados em gradiente para descubra o que minimizará o custo de duas ações. Este é o controle preditivo do modelo.
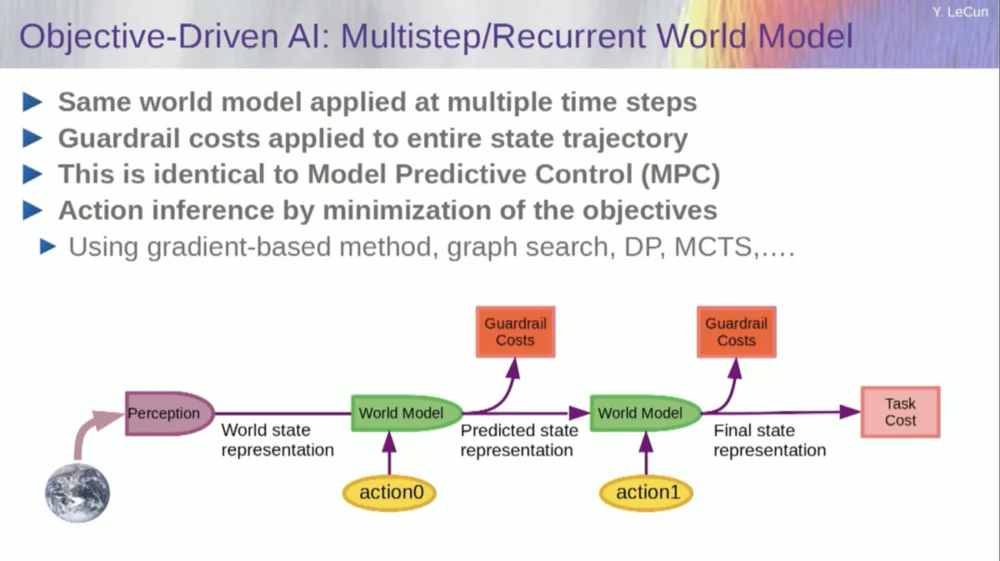
Agora, o mundo não é completamente determinístico, então você tem que usar variáveis latentes para ajustar o seu modelo do mundo. Variáveis latentes são basicamente variáveis que podem ser trocadas dentro de um conjunto de dados ou extraídas de uma distribuição, e representam a troca de um modelo do mundo entre múltiplas previsões que são compatíveis com as observações.
O que é ainda mais interessante é que os sistemas inteligentes são atualmente incapazes de fazer algo que os humanos e até os animais podem fazer, que é o planeamento hierárquico.
Por exemplo, se você estivesse planejando uma viagem de Nova York a Paris, poderia usar sua compreensão do mundo, seu corpo e talvez sua ideia de toda a configuração de ir daqui até Paris para planejar toda a sua viagem com seu deslocamento muscular de baixo nível.
Certo? Se você somar o número de etapas de controle muscular por dez milissegundos de todas as coisas que você precisa fazer antes de ir para Paris, é um número enorme. Então o que você faz é planejar de forma hierárquica, onde você começa em um nível muito alto e diz, ok, para chegar a Paris, primeiro preciso ir ao aeroporto, pegar um avião.
Como chego ao aeroporto? Digamos que estou em Nova York e preciso descer e pegar um táxi. Como faço para descer? Tenho que levantar da cadeira, abrir a porta, ir até o elevador, apertar o botão, etc. Como faço para me levantar de uma cadeira?
Em algum momento você terá que expressar as coisas como ações de controle muscular de baixo nível, mas não estamos planejando tudo de uma forma de baixo nível, estamos fazendo um planejamento hierárquico.

Como fazer isso usando sistemas de IA ainda está completamente sem solução e não temos ideia.
Este parece ser um requisito importante para um comportamento inteligente.
Então, como aprendemos modelos de mundo capazes de planejamento hierárquico, capazes de funcionar em diferentes níveis de abstração? Ninguém mostrou nada próximo disso. Este é um grande desafio. A imagem mostra o exemplo que acabei de mencionar.
Então, como treinamos esse modelo mundial agora? Porque este é realmente um grande problema.
Tento descobrir com que idade os bebês aprendem conceitos básicos sobre o mundo. Como eles aprendem física intuitiva, intuição física e todas essas coisas? Isso acontece muito antes de começarem a aprender coisas como linguagem e interação.
Portanto, recursos como rastreamento facial acontecem muito cedo. O movimento biológico, a distinção entre objetos animados e inanimados, também aparece cedo. O mesmo vale para a constância do objeto, que se refere ao fato de um objeto persistir quando é ocluído por outro objeto.
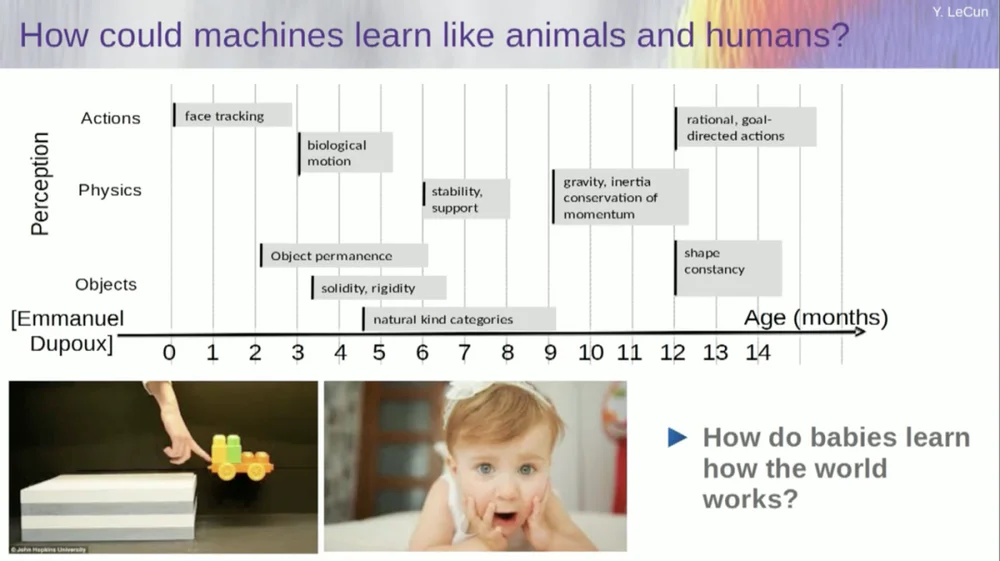
E os bebês aprendem naturalmente, não é preciso dar nomes às coisas. Eles saberão que cadeiras, mesas e gatos são diferentes. Quanto a conceitos como estabilidade e suporte, como gravidade, inércia, conservação e momento, eles na verdade só aparecem por volta dos nove meses de idade.
Isso leva muito tempo. Então, se você mostrar a um bebê de seis meses o cenário à esquerda, onde o carrinho está sobre uma plataforma, e você empurrá-lo para fora da plataforma, ele parecerá flutuar no ar. Um bebê de seis meses notará isso, enquanto um bebê de dez meses sentirá que isso não deveria acontecer e que o objeto deveria cair.
Quando algo inesperado acontece, significa que o seu “modelo de mundo” está errado. Então você presta atenção porque isso pode te matar.
Portanto, o tipo de aprendizagem que precisa acontecer aqui é muito semelhante ao tipo de aprendizagem que discutimos anteriormente.
Pegue a entrada, corrompa-a de alguma forma e treine uma grande rede neural para prever as partes que faltam. Se você treinar um sistema para prever o que vai acontecer em um vídeo, assim como treinamos redes neurais para prever o que vai acontecer em um texto, talvez esses sistemas sejam capazes de aprender o bom senso.
Infelizmente, tentamos isso há dez anos e foi um fracasso total. Nunca chegamos perto de um sistema que possa realmente aprender qualquer conhecimento geral apenas tentando prever pixels em um vídeo.
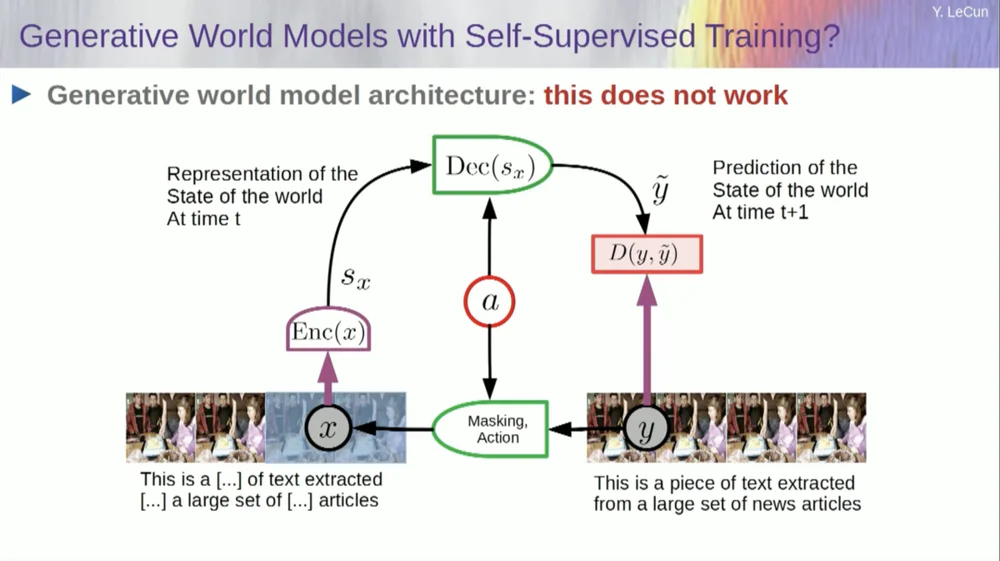
Você pode treinar um sistema para prever vídeos com boa aparência. Existem muitos exemplos de sistemas de geração de vídeo, mas internamente não são bons modelos do mundo físico. Não podemos fazer isso com eles.
Ok, então a ideia de que usaremos modelos generativos para prever o que vai acontecer aos indivíduos, e o sistema compreenderá magicamente a estrutura do mundo, é um completo fracasso.
Na última década, tentamos muitas abordagens.
Ele falha porque há muitos futuros possíveis. Em um espaço discreto como o texto, onde você pode prever qual palavra seguirá uma sequência de palavras, você pode gerar uma distribuição de probabilidade sobre as palavras possíveis em um dicionário. Mas quando se trata de quadros de vídeo, não temos uma boa maneira de representar a distribuição de probabilidade dos quadros de vídeo. Na verdade, esta tarefa é completamente impossível.

Tipo, eu fiz um vídeo dessa sala, certo? Peguei a câmera e filmei aquela parte e depois parei o vídeo. Perguntei ao sistema o que aconteceria a seguir. Pode prever os quartos restantes. Haverá uma parede, haverá pessoas sentadas nela e a densidade provavelmente será semelhante à da esquerda, mas é absolutamente impossível prever com precisão no nível do pixel todos os detalhes de como será a aparência de cada um de vocês. , a textura do mundo e o tamanho exato da sala.
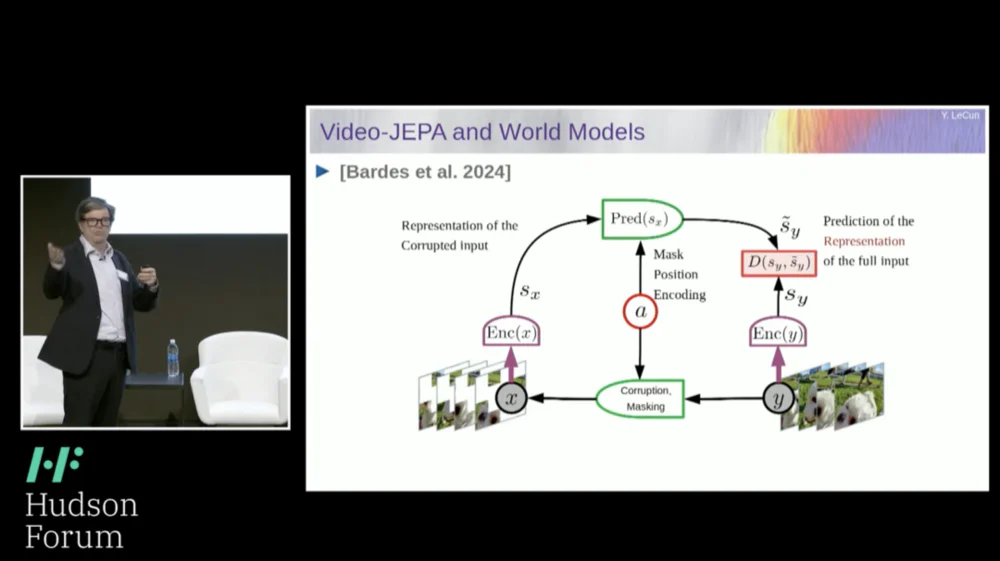
Portanto, minha solução proposta é a Joint Embedding Prediction Architecture (JEPA) .
A ideia é desistir da previsão de pixels e, em vez disso, aprender uma representação abstrata de como o mundo funciona e então fazer previsões dentro desse espaço de representação. Essa é a arquitetura, a arquitetura de previsão de incorporação conjunta. Essas duas incorporações pegam X (a versão corrompida) e Y respectivamente, são processadas pelo codificador e então o sistema é treinado para prever a representação de Y com base na representação de X.
Agora, o problema é que se você treinar tal sistema apenas usando gradiente descendente, retropropagação para minimizar o erro de previsão, ele entrará em colapso. Pode aprender uma representação constante para que as previsões se tornem muito simples, mas pouco informativas.
Então, o que quero que você lembre é a diferença entre autoencoders, arquiteturas generativas, autoencoders mascarados, etc., que tentam reconstruir previsões, versus arquiteturas de incorporação conjunta que fazem previsões no espaço de representação.
Acredito que o futuro está nessas arquiteturas de incorporação conjunta, e temos muitas evidências empíricas de que a melhor maneira de aprender boas representações de imagens é usar arquiteturas de edição conjunta.
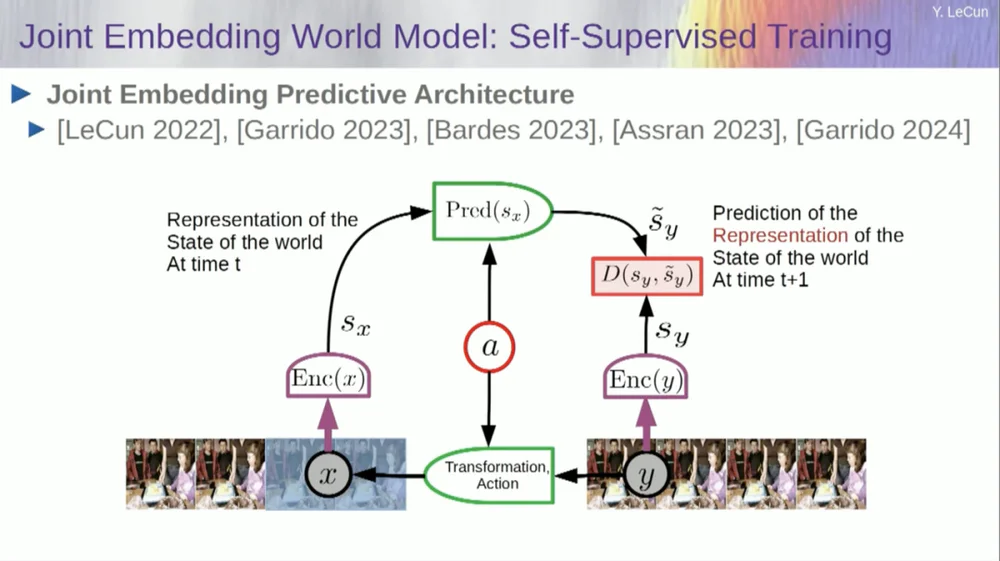
Todas as tentativas de aprender representações de imagens através da reconstrução têm sido fracas e não funcionam bem, e embora existam muitos projetos grandes que afirmam que funcionam, não funcionam, e o melhor desempenho é obtido com a arquitetura à direita.
Agora, se você pensar bem, é disso que se trata a nossa inteligência: encontrar uma boa representação de um fenômeno para que possamos fazer previsões, é disso que se trata a ciência.
real. Pense nisso, se você quiser prever a trajetória de um planeta, um planeta é um objeto muito complexo, é enorme, tem todos os tipos de características como clima, temperatura e densidade.
Embora seja um objeto complexo, para prever a trajetória de um planeta, você só precisa saber 6 números: 3 coordenadas de posição e 3 vetores de velocidade, pronto, não precisa fazer mais nada. Este é um exemplo muito importante que realmente mostra que a essência do poder preditivo reside em encontrar uma boa representação das coisas que observamos.

Então, como treinamos esse sistema?
Então você deseja evitar que o sistema trave. Uma maneira de fazer isso é usar algum tipo de função de custo que mede o conteúdo da informação da representação produzida pelo codificador e tenta maximizar o conteúdo da informação e minimizar a informação negativa. Seu sistema de treinamento deve extrair simultaneamente o máximo de informações possível da entrada e, ao mesmo tempo, minimizar o erro de previsão nesse espaço de representação.
O sistema encontrará algum compromisso entre extrair o máximo de informações possível e não extrair informações imprevisíveis. Você obterá um bom espaço de representação no qual as previsões podem ser feitas.
Agora, como você mede as informações? É aqui que as coisas ficam um pouco estranhas. Vou pular isso.
As máquinas superarão a inteligência humana e serão seguras e controláveis
Na verdade, existe uma maneira de entender isso matematicamente por meio de treinamento, modelos baseados em energia e funções de energia, mas não tenho tempo para entrar nisso.
Basicamente, estou lhe dizendo algumas coisas diferentes aqui: abandonar os modelos generativos em favor das arquiteturas JEPA, abandonar os modelos probabilísticos em favor dos modelos baseados em energia, abandonar os métodos de aprendizagem contrastivos e a aprendizagem por reforço. Venho dizendo isso há 10 anos.
E esses são os quatro pilares mais populares do aprendizado de máquina atualmente. Então provavelmente não sou muito popular no momento.
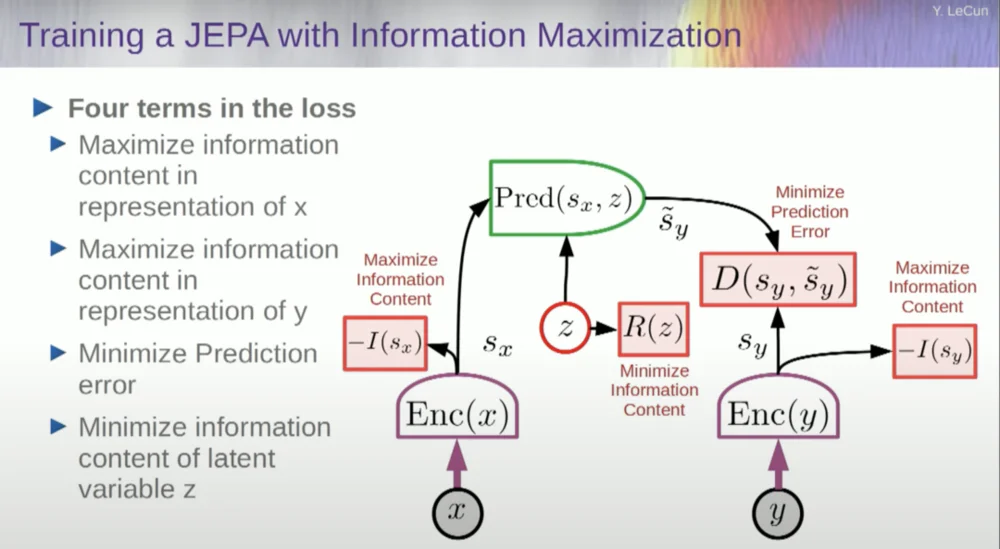
Uma abordagem é estimar o conteúdo da informação, medindo o conteúdo da informação proveniente do codificador.
Existem atualmente seis maneiras diferentes de conseguir isso. Na verdade, existe um método aqui chamado MCR, dos meus colegas da NYU, que evita que o sistema trave e produza constantes.
Pegue as variáveis do codificador e certifique-se de que elas tenham desvio padrão diferente de zero. Você poderia colocar isso em uma função de custo e garantir que os pesos sejam pesquisados e que as variáveis não entrem em colapso e se tornem constantes. Isto é relativamente simples.
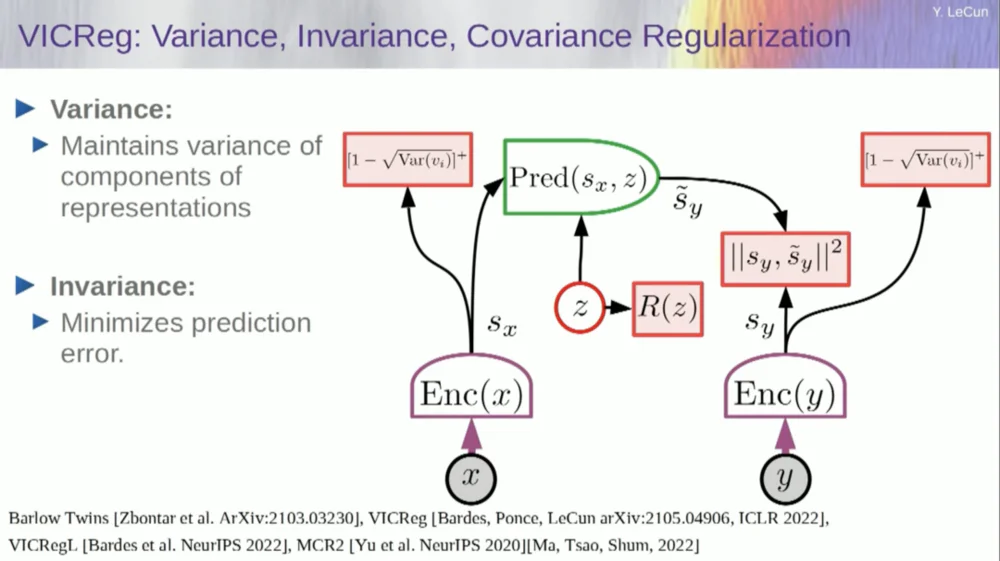
O problema agora é que o sistema pode “trapacear” e tornar todas as variáveis iguais ou altamente correlacionadas. Portanto, é necessário adicionar outro termo, o termo fora da diagonal, necessário para minimizar a matriz de covariância dessas variáveis, para garantir que elas estejam relacionadas.
É claro que isso não é suficiente, pois as variáveis ainda podem ser dependentes, mas não relacionadas. Portanto, adotamos outro método para estender as dimensões de SX para um espaço de dimensão superior VX e aplicamos regularização de variância-covariância neste espaço para garantir que os requisitos sejam atendidos.
Há outro truque aqui, porque o que estou maximizando é o limite superior do conteúdo informativo. Quero que o conteúdo real da informação siga minha maximização do limite superior. O que eu preciso é de um limite inferior para que ele ultrapasse o limite inferior e a informação aumente. Infelizmente, não temos informações sobre limites inferiores, ou pelo menos não sabemos como calculá-los.
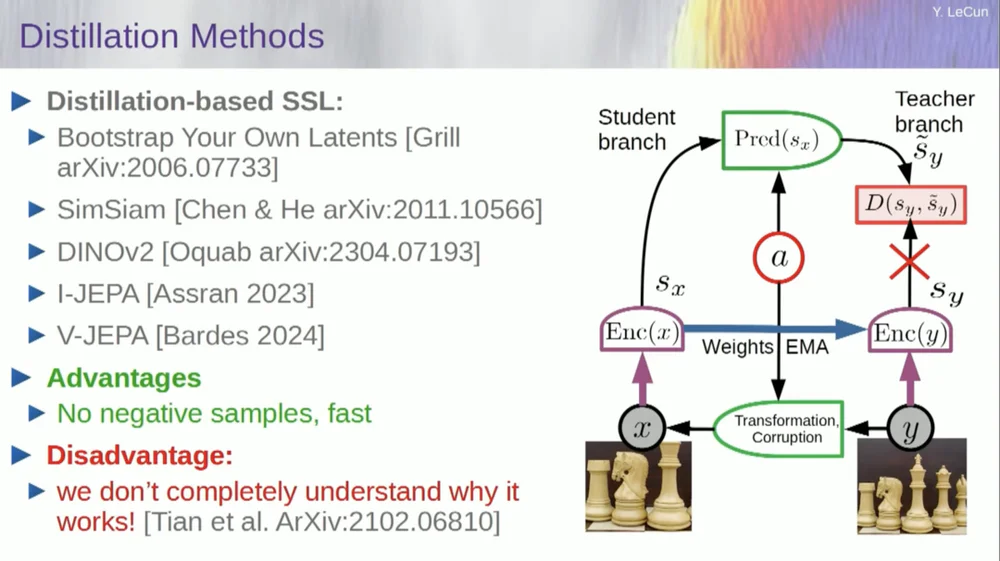
Existe um segundo conjunto de métodos denominado "método de estilo de destilação".
Este método funciona de maneiras misteriosas. Se você quiser saber exatamente quem está fazendo o quê, pergunte ao cara sentado aqui no Grill.
Ele tem um ensaio pessoal sobre isso que define muito bem. Sua ideia central é atualizar apenas uma parte do modelo sem retropropagar gradientes na outra parte e compartilhar os pesos de uma forma interessante. Existem também muitos artigos sobre esse aspecto.
Essa abordagem funciona bem se você deseja treinar um sistema totalmente autossupervisionado para gerar boas representações de imagens. A destruição de imagens é feita através de mascaramento, e alguns trabalhos recentes que fizemos para vídeos nos permitem treinar um sistema para extrair boas representações de vídeo para uso em tarefas posteriores, como vídeos de reconhecimento de ação, etc. Você pode ver que mascarar uma grande parte de um vídeo e fazer previsões por meio desse processo usa esse truque de destilação no espaço de representação para evitar o colapso. Isso funciona muito bem.
Portanto, se tivermos sucesso neste projeto e acabarmos com sistemas que possam raciocinar, planear e compreender o mundo físico, é assim que todas as nossas interações serão no futuro.
Levará anos, talvez até uma década, para que tudo funcione corretamente. Mark Zuckerberg fica me perguntando quanto tempo vai demorar. Se conseguirmos fazer isso, tudo bem, teremos sistemas que mediarão todas as nossas interações com o mundo digital. Eles responderão a todas as nossas perguntas.
Eles estarão conosco por muito tempo e formarão essencialmente um repositório de todo o conhecimento humano. Isso parece uma coisa de infraestrutura, como a Internet. Isso é menos um produto e mais uma infraestrutura.
Estas plataformas de IA devem ser de código aberto. IBM e Meta participam de um grupo chamado Artificial Intelligence Alliance, que promove plataformas de inteligência artificial de código aberto. Precisamos que estas plataformas sejam de código aberto porque precisamos de diversidade nestes sistemas de IA.

Precisamos que eles entendam todas as línguas, todas as culturas, todos os sistemas de valores do mundo, e isso não será conseguido com apenas um único sistema produzido por uma empresa na Costa Oeste ou na Costa Leste dos Estados Unidos. Estados. Esta deve ser uma contribuição de todo o mundo.
É claro que treinar modelos financeiros é muito caro, então apenas algumas empresas conseguem fazer isso. Se empresas como a Meta puderem fornecer o modelo subjacente como código aberto, então o mundo poderá ajustá-lo para seus próprios propósitos. Esta é a filosofia adotada pela Meta e pela IBM.

Portanto, a IA de código aberto não é apenas uma boa ideia, é necessária para a diversidade cultural e talvez até para a preservação da democracia.
O treinamento e o aperfeiçoamento serão feitos por meio de crowdsourcing ou por um ecossistema de startups e outras empresas.
Uma das coisas que está impulsionando o crescimento do ecossistema de startups de IA é a disponibilidade desses modelos de IA de código aberto. Quanto tempo levará para alcançar a inteligência artificial geral? Não sei, pode levar anos ou décadas.

Houve muitas mudanças ao longo do caminho e ainda há muitos problemas que precisam ser resolvidos. Isto será quase certamente mais difícil do que pensamos. Isso não acontece em um dia, mas é uma evolução gradual e incremental.
Então não é que um dia descobriremos o segredo da inteligência artificial geral, ligaremos a máquina e instantaneamente teremos superinteligência, e seremos todos exterminados pela superinteligência, não, não é o caso.
As máquinas ultrapassarão a inteligência humana, mas estarão sob controlo porque são orientadas por objectivos. Estabelecemos metas para eles e eles as cumprem. Como muitos de nós aqui somos líderes na indústria ou na academia.
Trabalhamos com pessoas mais inteligentes do que nós, e eu certamente também. Só porque há muitas pessoas mais espertas do que eu não significa que elas queiram dominar ou assumir o controle, essa é apenas a verdade. Claro que há riscos por trás disso, mas deixarei isso para discussão mais tarde, muito obrigado.