Com o rápido desenvolvimento da tecnologia de IA, a demanda por modelos de linguagem visual está crescendo a cada dia, mas seus altos requisitos de recursos computacionais limitam sua aplicação em dispositivos comuns. O editor de Downcodes apresentará a você hoje um modelo de linguagem visual leve chamado SmolVLM, que pode ser executado de forma eficiente em dispositivos com recursos limitados, como laptops e GPUs de consumo. O surgimento do SmolVLM trouxe a mais usuários a oportunidade de experimentar tecnologia avançada de IA, reduziu o limite de uso e também forneceu aos desenvolvedores ferramentas de pesquisa mais convenientes.
Nos últimos anos, tem havido uma procura crescente pela aplicação de modelos de aprendizagem automática em tarefas de visão e linguagem, mas a maioria dos modelos requer enormes recursos computacionais e não pode funcionar eficientemente em dispositivos pessoais. Especialmente os dispositivos pequenos, como laptops, GPUs de consumo e dispositivos móveis, enfrentam enormes desafios ao processar tarefas de linguagem visual.
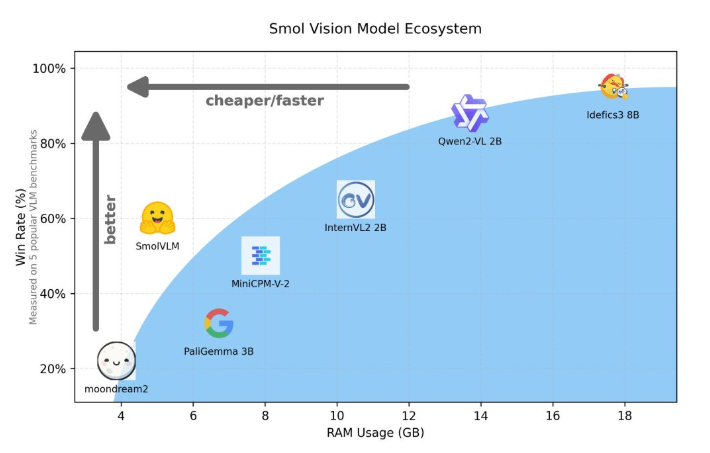
Tomando como exemplo o Qwen2-VL, embora tenha excelente desempenho, possui altos requisitos de hardware, o que limita sua usabilidade em aplicações em tempo real. Portanto, desenvolver modelos leves para rodar com menos recursos tornou-se uma necessidade importante.
Hugging Face lançou recentemente o SmolVLM, um modelo de linguagem visual com parâmetros 2B especialmente projetado para raciocínio do lado do dispositivo. SmolVLM supera outros modelos semelhantes em termos de uso de memória GPU e velocidade de geração de token. Sua principal característica é a capacidade de funcionar com eficiência em dispositivos menores, como laptops ou GPUs de consumo, sem sacrificar o desempenho. O SmolVLM encontra um equilíbrio ideal entre desempenho e eficiência, resolvendo problemas que eram difíceis de superar em modelos anteriores semelhantes.
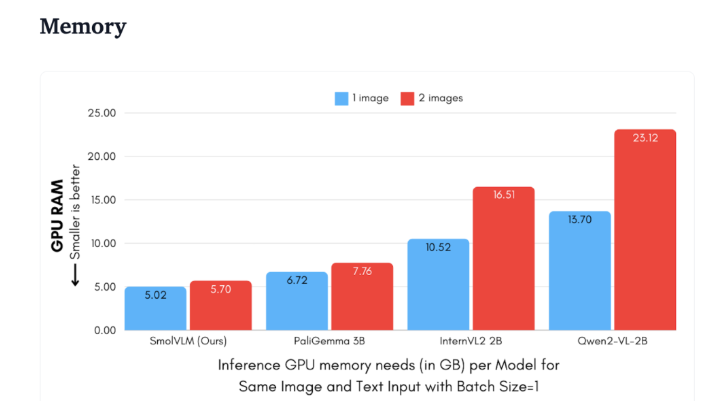
Comparado com Qwen2-VL2B, o SmolVLM gera tokens 7,5 a 16 vezes mais rápido, graças à sua arquitetura otimizada, que torna possível uma inferência leve. Essa eficiência não só traz benefícios práticos para os usuários finais, mas também melhora muito a experiência do usuário.
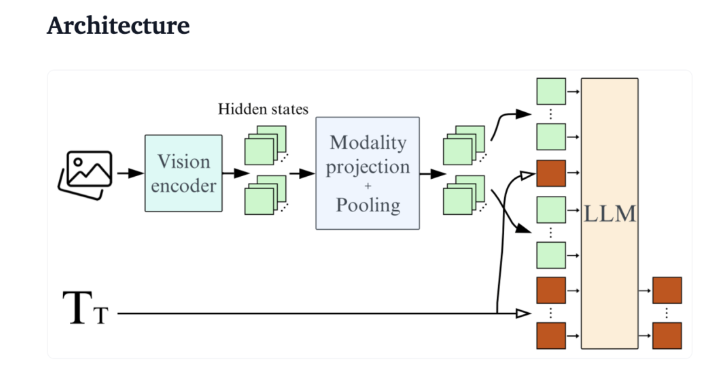
Do ponto de vista técnico, o SmolVLM possui uma arquitetura otimizada que suporta inferência eficiente no lado do dispositivo. Os usuários podem até mesmo fazer ajustes finos no Google Colab, reduzindo bastante o limite para experimentação e desenvolvimento.
Devido ao seu pequeno consumo de memória, o SmolVLM é capaz de funcionar sem problemas em dispositivos que anteriormente não conseguiam hospedar modelos semelhantes. Ao testar um vídeo de 50 quadros do YouTube, o SmolVLM teve um bom desempenho, marcando 27,14%, e superou os dois modelos que mais consomem recursos em termos de consumo de recursos, demonstrando sua forte adaptabilidade e flexibilidade.
SmolVLM é um marco importante no campo de modelos de linguagem visual. Seu lançamento permite que tarefas complexas de linguagem visual sejam executadas em dispositivos do dia a dia, preenchendo uma lacuna importante nas ferramentas atuais de IA.
O SmolVLM não apenas se destaca em velocidade e eficiência, mas também fornece aos desenvolvedores e pesquisadores uma ferramenta poderosa para facilitar o processamento de linguagem visual sem despesas caras de hardware. À medida que a tecnologia de IA continua a se tornar mais popular, modelos como o SmolVLM tornarão os poderosos recursos de aprendizado de máquina mais acessíveis.
demonstração: https://huggingface.co/spaces/HuggingFaceTB/SmolVLM
https://huggingface.co/spaces/HuggingFaceTB/SmolVLM
Em suma, o SmolVLM estabeleceu uma nova referência para modelos de linguagem visual leves. Seu desempenho eficiente e uso conveniente promoverão enormemente a popularização e o desenvolvimento da tecnologia de IA. Esperamos ansiosamente por mais inovações semelhantes no futuro, permitindo que a tecnologia de IA beneficie mais pessoas.