Nos últimos anos, o custo de formação de modelos linguísticos em grande escala permaneceu elevado, o que se tornou um factor importante que restringe o desenvolvimento da IA. Como reduzir custos de treinamento e melhorar a eficiência tornou-se o foco da indústria. O editor do Downcodes traz para você uma interpretação do artigo mais recente de pesquisadores da Universidade de Harvard e da Universidade de Stanford. Este artigo propõe uma regra de escalonamento "consciente da precisão" que reduz efetivamente os custos de treinamento, ajustando a precisão do treinamento do modelo, mesmo em alguns casos. caso, também pode melhorar o desempenho do modelo. Vamos dar uma olhada mais de perto nesta pesquisa emocionante.
No campo da inteligência artificial, maior escala parece significar maiores capacidades. Na busca por modelos de linguagem mais poderosos, as principais empresas de tecnologia estão empilhando freneticamente parâmetros de modelos e dados de treinamento, apenas para descobrir que os custos também estão aumentando. Não existe uma maneira econômica e eficiente de treinar modelos de linguagem?
Pesquisadores das universidades de Harvard e Stanford publicaram recentemente um artigo no qual descobriram que a precisão do treinamento de modelos é como uma chave oculta que pode desbloquear o "código de custo" do treinamento de modelos de linguagem.
O que é precisão do modelo? Simplificando, refere-se aos parâmetros do modelo e ao número de dígitos usados no processo de cálculo. Os modelos tradicionais de aprendizagem profunda geralmente usam números de ponto flutuante de 32 bits (FP32) para treinamento, mas nos últimos anos, com o desenvolvimento de hardware, tipos de números de menor precisão são usados, como números de ponto flutuante de 16 bits (FP16) ou 8- inteiros de bits (INT8) O treinamento já é possível.
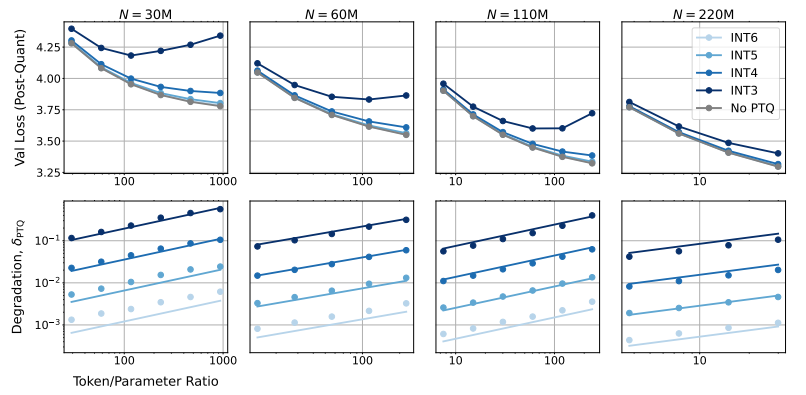
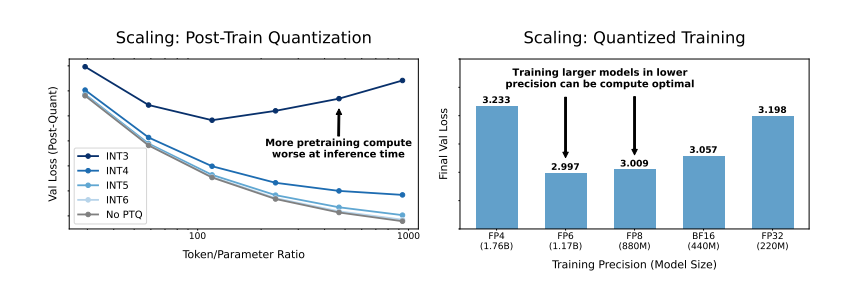
Então, qual será o impacto da redução da precisão do modelo no desempenho do modelo? Esta é exatamente a questão que este artigo deseja explorar. Através de um grande número de experimentos, os pesquisadores analisaram as mudanças de custo e desempenho do treinamento e inferência do modelo sob diferentes acurácias e propuseram um novo conjunto de regras de escalonamento "conscientes da precisão".
Eles descobriram que o treinamento com menor precisão reduz efetivamente o “número efetivo de parâmetros” do modelo, reduzindo assim a quantidade de computação necessária para o treinamento. Isso significa que, com o mesmo orçamento computacional, podemos treinar modelos em maior escala, ou na mesma escala, usar menor precisão pode economizar muitos recursos computacionais.
Ainda mais surpreendentemente, os pesquisadores também descobriram que, em alguns casos, o treinamento com menor precisão pode realmente melhorar o desempenho do modelo. Por exemplo, para aqueles que requerem "quantização pós-treinamento". Se o modelo usar menor precisão durante o estágio de treinamento, o modelo será mais robusto à redução da precisão após a quantização, apresentando assim melhor desempenho durante a etapa de inferência.
Então, qual precisão devemos escolher para treinar o modelo? Ao analisar suas regras de escala, os pesquisadores chegaram a algumas conclusões interessantes:
O treinamento tradicional de precisão de 16 bits pode não ser o ideal. Sua pesquisa sugere que 7 a 8 dígitos de precisão podem ser uma opção mais econômica.
Também não é aconselhável buscar cegamente um treinamento de precisão ultrabaixa (como 4 dígitos). Porque com uma precisão extremamente baixa, o número de parâmetros efetivos do modelo cairá drasticamente. Para manter o desempenho, precisamos aumentar significativamente o tamanho do modelo, o que, por sua vez, levará a custos computacionais mais elevados.
A precisão ideal do treinamento pode variar para modelos de tamanhos diferentes. Para aqueles modelos que exigem muito “overtraining”, como as séries Llama-3 e Gemma-2, o treinamento com maior precisão pode ser mais econômico.
Esta pesquisa fornece uma nova perspectiva sobre a compreensão e otimização do treinamento de modelos de linguagem. Isso nos diz que a escolha da precisão não é estática, mas precisa ser ponderada com base no tamanho específico do modelo, no volume de dados de treinamento e nos cenários de aplicação.
Claro, existem algumas limitações neste estudo. Por exemplo, o modelo que utilizaram é de escala relativamente pequena e os resultados experimentais podem não ser diretamente generalizáveis para modelos de maior escala. Além disso, focaram apenas na função de perda do modelo e não avaliaram o desempenho do modelo em tarefas posteriores.
No entanto, esta pesquisa ainda tem implicações importantes. Ele revela a complexa relação entre a precisão do modelo, o desempenho do modelo e o custo de treinamento, e nos fornece informações valiosas para projetar e treinar modelos de linguagem mais poderosos e econômicos no futuro.
Artigo: https://arxiv.org/pdf/2411.04330
Em suma, esta pesquisa fornece novas ideias e métodos para reduzir o custo do treinamento de modelos de linguagem em larga escala e fornece um valor de referência importante para o desenvolvimento futuro da IA. O editor do Downcodes espera mais progresso na pesquisa de precisão de modelos e contribui para a construção de modelos de IA mais econômicos.