O editor do Downcodes soube que a Ai2, uma instituição de pesquisa de IA sem fins lucrativos, lançou recentemente sua nova série OLMo2 de modelos de linguagem, que é a segunda geração de sua série "Open Language Model" (OLMo). OLMo2 adere ao conceito de código-fonte totalmente aberto e seus dados, ferramentas e códigos de treinamento são totalmente abertos. Isso é particularmente importante no campo de IA atual e representa um novo patamar no desenvolvimento de IA de código aberto. Ao contrário de outros modelos que afirmam ser "abertos", o OLMo2 segue estritamente a definição da Open Source Initiative, atende aos rígidos padrões de IA de código aberto e fornece à comunidade de IA forte suporte técnico e valiosos recursos de aprendizagem.
Ai2, uma organização sem fins lucrativos de pesquisa em IA, lançou recentemente sua nova série OLMo2, que é o modelo de segunda geração da série "Open Language Model" (OLMo) lançada pela organização. O lançamento do OLMo2 não apenas fornece forte suporte técnico para a comunidade de IA, mas também representa o mais recente desenvolvimento de IA de código aberto com seu código-fonte totalmente aberto.
Ao contrário de outros modelos de linguagem "aberta" atualmente no mercado, como a série Llama da Meta, o OLMo2 atende à definição estrita da Open Source Initiative, o que significa que os dados de treinamento, ferramentas e códigos utilizados para o seu desenvolvimento são públicos e acessíveis a qualquer pessoa e. usar. Conforme definido pela Open Source Initiative, o OLMo2 atende aos requisitos da organização para um padrão de “IA de código aberto”, que foi finalizado em outubro deste ano.
Ai2 mencionou em seu blog que durante o processo de desenvolvimento do OLMo2, todos os dados de treinamento, códigos, planos de treinamento, métodos de avaliação e pontos de verificação intermediários foram totalmente abertos, visando promover inovação e descoberta na comunidade de código aberto por meio de recursos compartilhados. “Ao compartilhar abertamente nossos dados, soluções e descobertas, esperamos fornecer à comunidade de código aberto os recursos para descobrir novos métodos e tecnologias inovadoras”, disse Ai2.
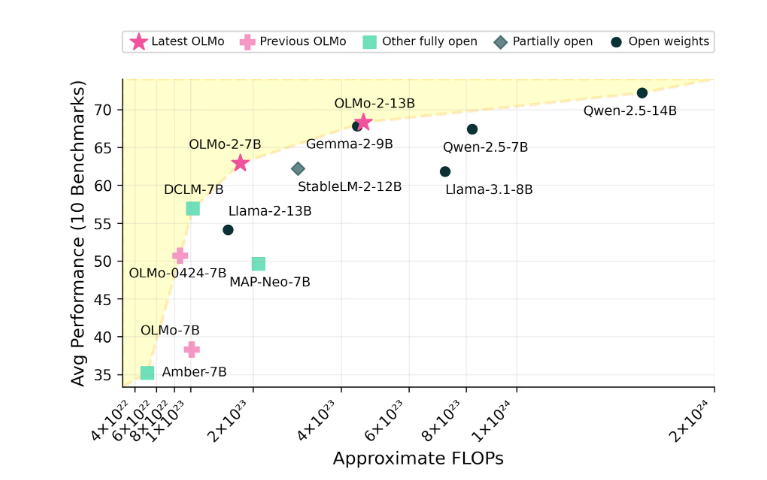
A série OLMo2 inclui duas versões: uma é OLMo7B com 7 bilhões de parâmetros e a outra é OLMo13B com 13 bilhões de parâmetros. O número de parâmetros afeta diretamente o desempenho do modelo, e versões com mais parâmetros geralmente podem lidar com tarefas mais complexas. OLMo2 teve um bom desempenho em tarefas de texto comuns, sendo capaz de completar tarefas como responder perguntas, resumir documentos e escrever código.

Nota sobre a fonte da imagem: a imagem é gerada por IA e autorizada pelo provedor de serviços Midjourney
Para treinar o OLMo2, o Ai2 usou um conjunto de dados contendo cinco trilhões de tokens. Token é a menor unidade no modelo de linguagem. 1 milhão de tokens equivale aproximadamente a 750.000 palavras. Os dados de treinamento incluem conteúdo de sites de alta qualidade, artigos acadêmicos, fóruns de discussão de perguntas e respostas e livros de exercícios de matemática sintética, e são cuidadosamente selecionados para garantir a eficiência e a precisão do modelo.
Ai2 está confiante no desempenho do OLMo2, alegando que ele competiu em desempenho com modelos de código aberto, como o Llama3.1 da Meta. Ai2 destacou que o desempenho do OLMo27B superou até mesmo o Llama3.18B e se tornou um dos modelos de linguagem totalmente aberta mais fortes atualmente. Todos os modelos OLMo2 e seus componentes podem ser baixados gratuitamente através do site oficial do Ai2 e seguem a licença Apache2.0, o que significa que esses modelos podem ser utilizados não apenas para pesquisa, mas também para aplicações comerciais.
A natureza de código aberto do OLMo2 promoverá enormemente a cooperação aberta e a inovação no campo da IA, proporcionando aos investigadores e desenvolvedores um espaço mais amplo para o desenvolvimento. Esperamos que o OLMo2 traga mais inovações e aplicações no futuro.