Relatórios do editor de downcodes: Nos últimos anos, a tecnologia de animação de imagens baseada em áudio desenvolveu-se rapidamente, mas os modelos existentes ainda apresentam gargalos em termos de eficiência e duração. Para resolver este problema, os investigadores desenvolveram uma nova tecnologia chamada JoyVASA, que melhora significativamente a qualidade e a eficiência da animação de imagens orientada por áudio através de um design engenhoso de duas fases. JoyVASA não só é capaz de gerar vídeos animados mais longos, mas também suporta animação facial de animais e apresenta boa compatibilidade multilíngue, trazendo novas possibilidades para o campo da produção de animação.
Recentemente, pesquisadores propuseram uma nova tecnologia chamada JoyVASA, que visa melhorar os efeitos de animação de imagens baseados em áudio. Com o desenvolvimento contínuo de modelos de aprendizagem profunda e difusão, a animação de retratos baseada em áudio fez um progresso significativo na qualidade do vídeo e na precisão da sincronização labial. No entanto, a complexidade dos modelos existentes aumenta a eficiência do treinamento e da inferência, ao mesmo tempo que limita a duração e a continuidade entre quadros dos vídeos.
JoyVASA adota um design de dois estágios. O primeiro estágio introduz uma estrutura de representação facial desacoplada para separar expressões faciais dinâmicas de representações faciais tridimensionais estáticas.
Essa separação permite que o sistema combine qualquer modelo facial 3D estático com sequências de ação dinâmicas para gerar vídeos animados mais longos. Na segunda fase, a equipe de pesquisa treinou um transformador de difusão que pode gerar sequências de ação diretamente a partir de sinais de áudio, um processo independente da identidade do personagem. Finalmente, o gerador baseado no treinamento do primeiro estágio utiliza a representação facial 3D e a sequência de ação gerada como entrada para renderizar efeitos de animação de alta qualidade.
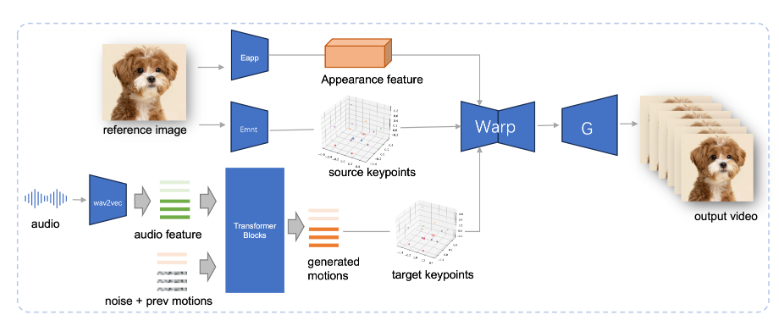
Notavelmente, JoyVASA não se limita à animação de retratos humanos, mas também pode animar rostos de animais perfeitamente. Este modelo é treinado em um conjunto de dados misto, combinando dados privados em chinês e dados públicos em inglês, mostrando boas capacidades de suporte multilíngue. Os resultados experimentais comprovam a eficácia deste método. Pesquisas futuras se concentrarão na melhoria do desempenho em tempo real e no refinamento do controle de expressão para expandir ainda mais a aplicação desta estrutura na animação de imagens.
O surgimento do JoyVASA marca um avanço importante na tecnologia de animação baseada em áudio, promovendo novas possibilidades no campo da animação.
Entrada do projeto: https://jdh-algo.github.io/JoyVASA/
A inovação da tecnologia JoyVASA reside no seu design eficiente de dois estágios e nos poderosos recursos de suporte multilíngue, que fornecem uma solução mais conveniente e eficiente para a produção de animação. No futuro, com o aprimoramento da tecnologia, espera-se que o JoyVASA seja amplamente utilizado em mais campos, trazendo-nos trabalhos de animação mais realistas e emocionantes. Ansioso por mais avanços tecnológicos e liderando um novo capítulo no desenvolvimento da indústria de animação!