A equipe de pesquisa de IA da Apple lançou uma nova geração de família de modelos multimodais de linguagem grande MM1.5, que pode integrar vários tipos de dados, como texto e imagens, e demonstrou desempenho poderoso em tarefas como resposta visual a perguntas, geração de imagens e multi- capacidade de interpretação modal de dados. O MM1.5 supera as dificuldades dos modelos multimodais anteriores no processamento de imagens ricas em texto e tarefas visuais refinadas. Por meio de uma abordagem inovadora centrada em dados, ele usa dados de OCR de alta resolução e descrições de imagens sintéticas para melhorar significativamente o desempenho do modelo. Compreensão. O editor de Downcodes lhe dará uma compreensão aprofundada das inovações do MM1.5 e seu excelente desempenho em vários testes de benchmark.
Recentemente, a equipe de pesquisa de IA da Apple lançou sua nova geração de família de modelos multimodais de grandes linguagens (MLLMs) - MM1.5. Esta série de modelos pode combinar vários tipos de dados, como texto e imagens, mostrando-nos a nova capacidade da IA de compreender tarefas complexas. Tarefas como resposta visual a perguntas, geração de imagens e interpretação de dados multimodais podem ser melhor resolvidas com a ajuda desses modelos.
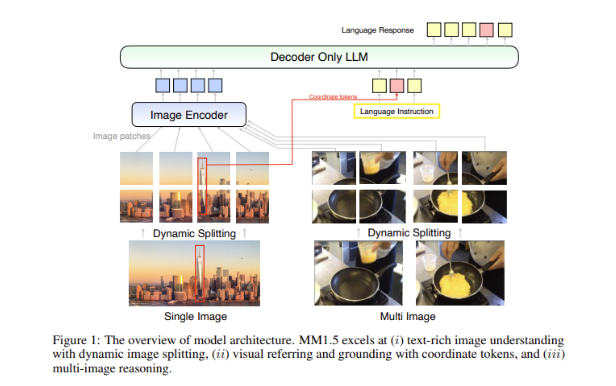
Um grande desafio nos modelos multimodais é como conseguir uma interação eficaz entre diferentes tipos de dados. Os modelos anteriores muitas vezes tiveram dificuldades com imagens ricas em texto ou tarefas de visão refinadas. Portanto, a equipe de pesquisa da Apple introduziu um método inovador centrado em dados no modelo MM1.5, usando dados OCR de alta resolução e descrições de imagens sintéticas para fortalecer as capacidades de compreensão do modelo.
Este método não só permite que o MM1.5 supere os modelos anteriores em tarefas de compreensão visual e posicionamento, mas também lança duas versões especializadas do modelo: MM1.5-Video e MM1.5-UI, que são usadas para compreensão e posicionamento de vídeo, respectivamente. Análise de interface móvel.
O treinamento do modelo MM1.5 é dividido em três etapas principais.
A primeira etapa é o pré-treinamento em grande escala, usando 2 bilhões de pares de dados de imagem e texto, 600 milhões de documentos de imagem-texto intercalados e 2 trilhões de tokens somente de texto.
A segunda etapa é melhorar ainda mais o desempenho das tarefas de imagem enriquecidas com texto através do pré-treinamento contínuo de 45 milhões de dados de OCR de alta qualidade e 7 milhões de descrições sintéticas.
Finalmente, no estágio de ajuste fino supervisionado, o modelo é otimizado usando dados de imagem única, multiimagem e somente texto cuidadosamente selecionados para torná-lo melhor em referência visual detalhada e raciocínio multiimagem.
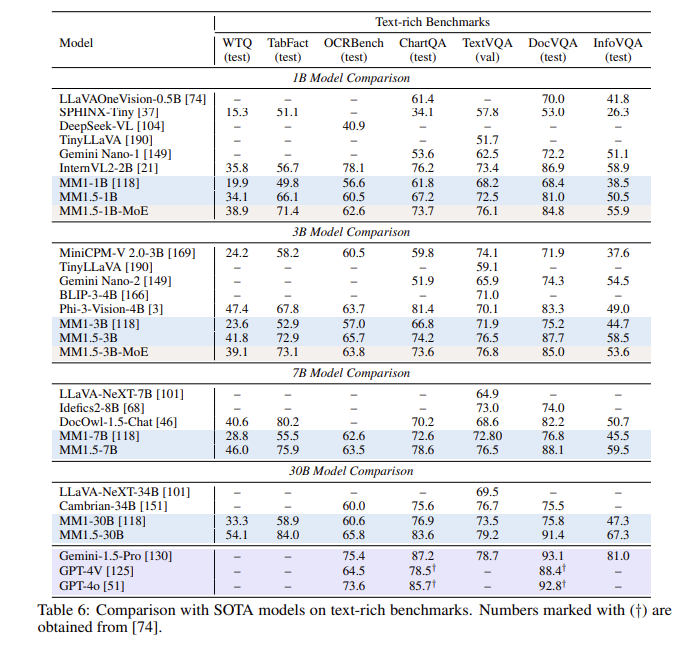
Após uma série de avaliações, o modelo MM1.5 teve um bom desempenho em vários testes de benchmark, especialmente quando se trata de compreensão de imagens ricas em texto, com uma melhoria de 1,4 pontos em relação ao modelo anterior. Além disso, até mesmo o MM1.5-Video, que foi projetado especificamente para compreensão de vídeo, alcançou o nível de liderança em tarefas relacionadas com seus poderosos recursos multimodais.
A família de modelos MM1.5 não apenas estabelece uma nova referência para modelos multimodais de grandes linguagens, mas também demonstra seu potencial em uma variedade de aplicações, desde compreensão geral de texto de imagem até análise de vídeo e interface de usuário, todas com excelente desempenho.
Destaque:
**Variantes de modelo**: Inclui modelos densos e modelos MoE com parâmetros de 1 bilhão a 30 bilhões, garantindo escalabilidade e implantação flexível.
? **Dados de treinamento**: Utilizando 2 bilhões de pares imagem-texto, 600 milhões de documentos imagem-texto intercalados e 2 trilhões de tokens somente de texto.
**Melhoria de desempenho**: em um teste de benchmark focado na compreensão de imagens ricas em texto, foi alcançada uma melhoria de 1,4 ponto em comparação com o modelo anterior.
Em suma, a família de modelos MM1.5 da Apple fez progressos significativos no campo de modelos multimodais de grandes linguagens, e seus métodos inovadores e excelente desempenho fornecem uma nova direção para o desenvolvimento futuro de IA. Esperamos que o MM1.5 mostre seu potencial em mais cenários de aplicação.