Uma equipe de pesquisa da Universidade Carnegie Mellon lançou recentemente uma tecnologia inovadora - DressRecon, que pode reconstruir um modelo 3D detalhado e consistente no tempo do corpo humano a partir de vídeo monocular. Diferente dos métodos anteriores de reconstrução do corpo humano que exigem roupas justas ou dados de visualização múltipla, o DressRecon pode lidar com cenas usando roupas largas ou até mesmo segurando objetos, expandindo enormemente o escopo de aplicações e trazendo inovação para campos como criação de imagens virtuais e produção de animação. O editor de Downcodes lhe dará uma compreensão profunda desta tecnologia impressionante.
Recentemente, uma equipe de pesquisa da Universidade Carnegie Mellon lançou uma nova tecnologia chamada “DressRecon”, que visa reconstruir um modelo humano consistente no tempo a partir de vídeo monocular. A grande vantagem do DressRecon é que você não só pode inserir um vídeo para construir um modelo 3D, mas também restaurar detalhes finos, como roupas complexas e itens manuais.
Esta tecnologia é particularmente adequada para cenários onde você usa roupas largas ou interage com objetos manuais, rompendo as limitações das tecnologias anteriores. No passado, a reconstrução do corpo humano geralmente exigia o uso de roupas justas ou a calibração de múltiplas visualizações para capturar dados, ou mesmo a digitalização personalizada, que era difícil de coletar em grande escala.
A inovação do "DressRecon" é que ele combina o conhecimento prévio geral da forma do corpo humano e a deformação corporal específica do vídeo, e pode ser otimizado dentro de um vídeo.
O núcleo desta tecnologia é aprender um modelo neural implícito que possa lidar com a deformação do corpo e das roupas separadamente e estabelecer camadas de modelo de movimento separadamente.
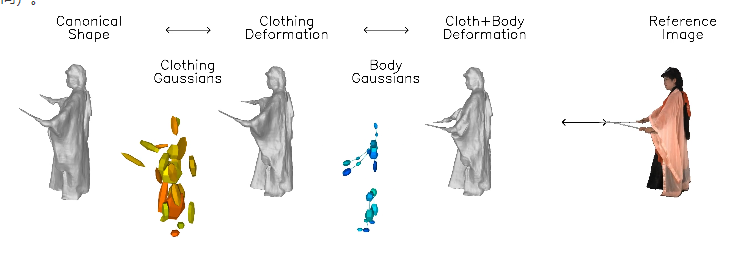
Para capturar as características geométricas sutis das roupas, a equipe de pesquisa utilizou conhecimentos prévios baseados em imagens, incluindo postura humana, normais de superfície e fluxo óptico. Esta informação fornece suporte adicional durante o processo de otimização, tornando o efeito de reconstrução mais realista.

DressRecon é capaz de extrair modelos 3D de alta fidelidade de uma única entrada de vídeo e pode ainda ser otimizado em Gaussianos 3D explícitos para melhorar a qualidade de renderização e oferecer suporte à visualização interativa.
Os pesquisadores demonstraram os efeitos de reconstrução 3D de alta fidelidade que DressRecon pode alcançar em alguns conjuntos de dados desafiadores de deformação de roupas e interação de objetos.
Além disso, a imagem humana virtual reconstruída pode ser renderizada de qualquer ângulo, mostrando um efeito altamente impactante visualmente. A equipe também comparou o desempenho do DressRecon com múltiplas tecnologias de base na reconstrução de formas. Os resultados mostraram que o DressRecon mostrou maior fidelidade ao processar estruturas deformadas complexas.
Entrada do projeto: https://jefftan969.github.io/dressrecon/
Destaque:
?A equipe de pesquisa lançou a tecnologia DressRecon para obter reconstrução do corpo humano de alta qualidade por meio de vídeo monocular, especialmente adequado para cenas com roupas largas e objetos portáteis.
? Utilizando modelos neurais implícitos, esta tecnologia trata as deformações do corpo e das roupas separadamente e captura características geométricas sutis com a ajuda do conhecimento prévio da base de imagens.
? Os resultados da reconstrução podem não apenas gerar modelos tridimensionais de alta fidelidade, mas também suportar a renderização de qualquer ângulo, melhorando a experiência de visualização.
O surgimento da tecnologia DressRecon irá, sem dúvida, promover o desenvolvimento da tecnologia de modelagem 3D do corpo humano, um grande passo em frente. Seus recursos eficientes e convenientes, bem como suas excelentes capacidades de processamento para cenas complexas, trazem possibilidades ilimitadas para as áreas de realidade virtual, produção de animação, desenvolvimento de jogos e outras áreas no futuro. Esperamos que esta tecnologia realize seu grande potencial em mais cenários de aplicação!