Nos últimos anos, o modelo Transformer e seu mecanismo de atenção fizeram progressos significativos no campo dos grandes modelos de linguagem (LLM), mas o problema de ser suscetível à interferência de informações irrelevantes sempre existiu. O editor de Downcodes irá interpretar para você um artigo mais recente, que propõe um novo modelo chamado Transformador Diferencial (Transformador DIFF), que visa resolver o problema de ruído de atenção no modelo Transformer e melhorar a eficiência e precisão do modelo. O modelo filtra efetivamente informações irrelevantes por meio de um mecanismo inovador de atenção diferencial, permitindo que o modelo se concentre mais nas informações principais, alcançando assim melhorias significativas em vários aspectos, incluindo modelagem de linguagem, processamento de texto longo, recuperação de informações importantes e redução da ilusão do modelo, etc. .
Os modelos de linguagem grande (LLM) desenvolveram-se rapidamente recentemente, nos quais o modelo Transformer desempenha um papel importante. O núcleo do Transformer é o mecanismo de atenção, que atua como um filtro de informações e permite que o modelo se concentre nas partes mais importantes da frase. Mas mesmo um Transformer poderoso sofrerá interferência de informações irrelevantes, assim como você está tentando encontrar um livro na biblioteca, mas é sobrecarregado por uma pilha de livros irrelevantes e a eficiência é naturalmente baixa.
A informação irrelevante gerada por esse mecanismo de atenção é chamada de ruído de atenção no artigo. Imagine que você deseja encontrar uma informação importante em um arquivo, mas a atenção do modelo Transformer está espalhada por vários lugares irrelevantes, assim como uma pessoa míope que não consegue ver os pontos-chave.
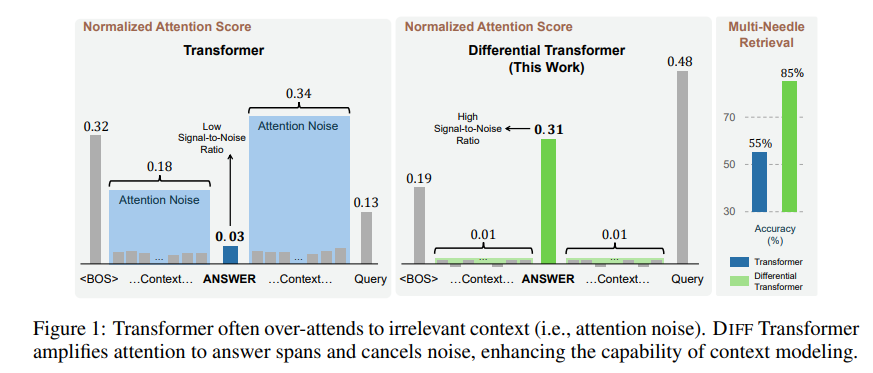
Para resolver este problema, este artigo propõe um Transformador Diferencial (Transformador DIFF). O nome é muito avançado, mas o princípio é realmente muito simples. Assim como os fones de ouvido com cancelamento de ruído, o ruído é eliminado pela diferença entre dois sinais.
O núcleo do Transformador Diferencial é o mecanismo de atenção diferencial. Ele divide os vetores de consulta e chave em dois grupos, calcula dois mapas de atenção respectivamente e depois subtrai esses dois mapas para obter a pontuação final de atenção. Esse processo é como fotografar o mesmo objeto com duas câmeras e depois sobrepor as duas fotos, e as diferenças serão destacadas.
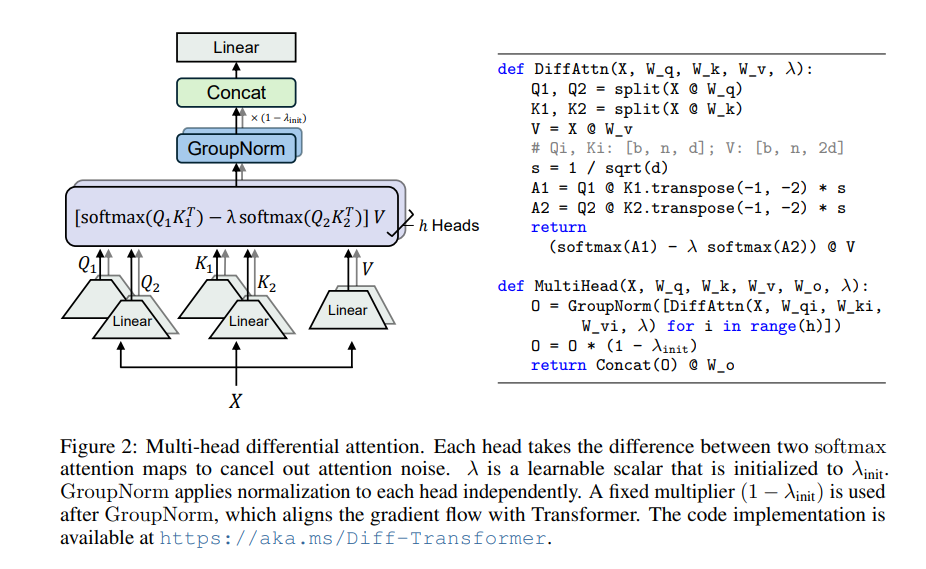
Dessa forma, o Transformador Diferencial pode efetivamente eliminar o ruído de atenção e permitir que o modelo se concentre mais nas informações principais. Assim como quando você coloca fones de ouvido com cancelamento de ruído, o ruído ambiente desaparece e você pode ouvir o som desejado com mais clareza.
Uma série de experimentos foram realizados no artigo para provar a superioridade do Transformador Diferencial. Primeiro, ele tem um bom desempenho na modelagem de linguagem, exigindo apenas 65% do tamanho do modelo ou dos dados de treinamento do Transformer para obter resultados semelhantes.
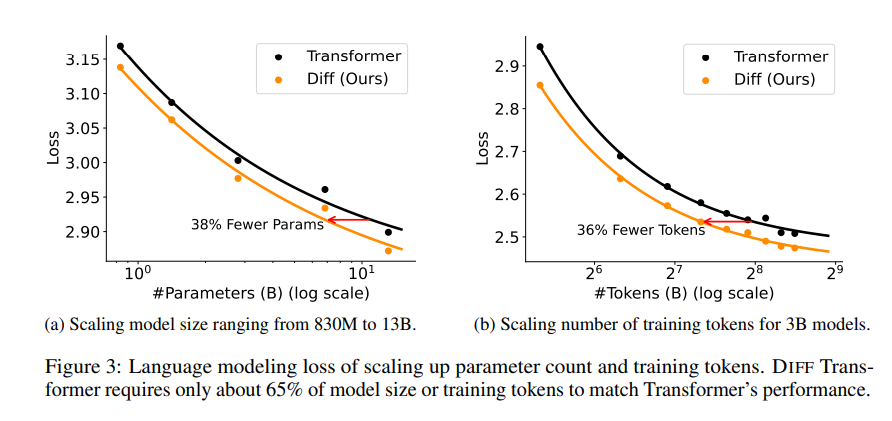
Em segundo lugar, o Transformador Diferencial também é melhor na modelagem de textos longos e pode utilizar efetivamente informações contextuais mais longas.
Mais importante ainda, o Transformador Diferencial mostra vantagens significativas na recuperação de informações importantes, na redução da ilusão do modelo e na aprendizagem de contexto.
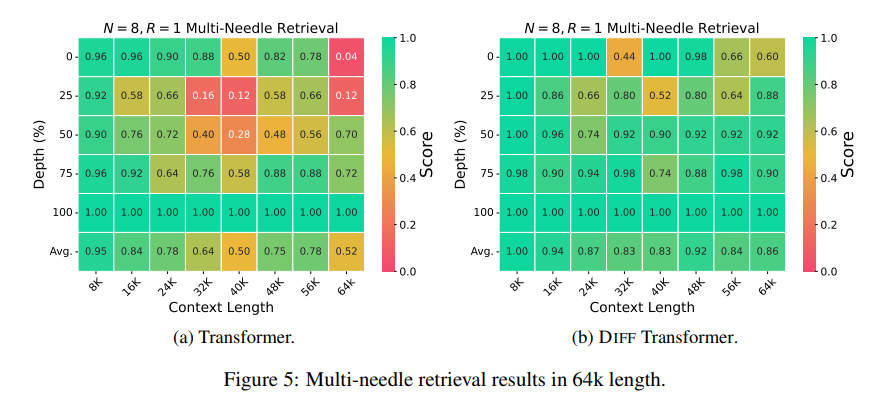
Em termos de recuperação de informações importantes, o Transformador Diferencial é como um mecanismo de busca preciso que pode encontrar com precisão o que você deseja em grandes quantidades de informações. Ele pode manter alta precisão mesmo em cenários com informações extremamente complexas.
Em termos de redução das alucinações do modelo, o Transformador Diferencial pode efetivamente evitar o "absurdo" do modelo e gerar resumos de texto e resultados de perguntas e respostas mais precisos e confiáveis.
Em termos de aprendizagem contextual, o Transformador Diferencial é mais parecido com um mestre em aprendizagem, capaz de aprender rapidamente novos conhecimentos a partir de um pequeno número de amostras, e o efeito de aprendizagem é mais estável, ao contrário do Transformador, que não é facilmente afetado pela ordem das amostras. .
Além disso, o Transformador Diferencial também pode reduzir efetivamente valores discrepantes nos valores de ativação do modelo, o que significa que é mais fácil modelar a quantização e pode obter quantização de bits mais baixos, melhorando assim a eficiência do modelo.
Resumindo, o Transformador Diferencial resolve efetivamente o problema de ruído de atenção do modelo Transformer por meio do mecanismo de atenção diferencial e alcança melhorias significativas em vários aspectos. Fornece novas ideias para o desenvolvimento de grandes modelos de linguagem e desempenhará um papel importante em mais campos no futuro.
Endereço do artigo: https://arxiv.org/pdf/2410.05258
Resumindo, o Transformador Diferencial fornece um método eficaz para resolver o problema de ruído de atenção do modelo Transformer. Seu excelente desempenho em vários campos indica sua posição importante no desenvolvimento de grandes modelos de linguagem no futuro. O editor do Downcodes recomenda que os leitores leiam o artigo completo para obter uma compreensão aprofundada de seus detalhes técnicos e perspectivas de aplicação. Esperamos que o Transformador Diferencial traga mais avanços no campo da inteligência artificial!