Na era da explosão da informação, é crucial processar com eficiência informações de texto em imagens. O editor de Downcodes apresentará hoje um modelo revolucionário de OCR - GOT (General Optical Character Recognition Theory), que marca a entrada da tecnologia OCR na era 2.0. O modelo GOT combina as vantagens do OCR tradicional e dos modelos de linguagem extensa e traz novos avanços no campo do reconhecimento de texto com seu poderoso desempenho e versatilidade. Ele pode não apenas reconhecer documentos e textos de cenas em inglês e chinês, mas também lidar com informações complexas, como fórmulas matemáticas e químicas, símbolos musicais, gráficos, etc. Ele pode ser chamado de "player versátil" na área de OCR.
Na era digital, a conversão rápida de conteúdo de texto em imagens em texto editável é um requisito comum e importante. Agora, o advento de um novo modelo de reconhecimento óptico de caracteres (OCR) chamado GOT (General Optical Character Recognition Theory) marca a entrada da tecnologia OCR na era 2.0. Este modelo inovador combina as vantagens dos sistemas tradicionais de OCR e modelos de linguagem em larga escala para criar uma ferramenta de reconhecimento de texto mais eficiente e inteligente.
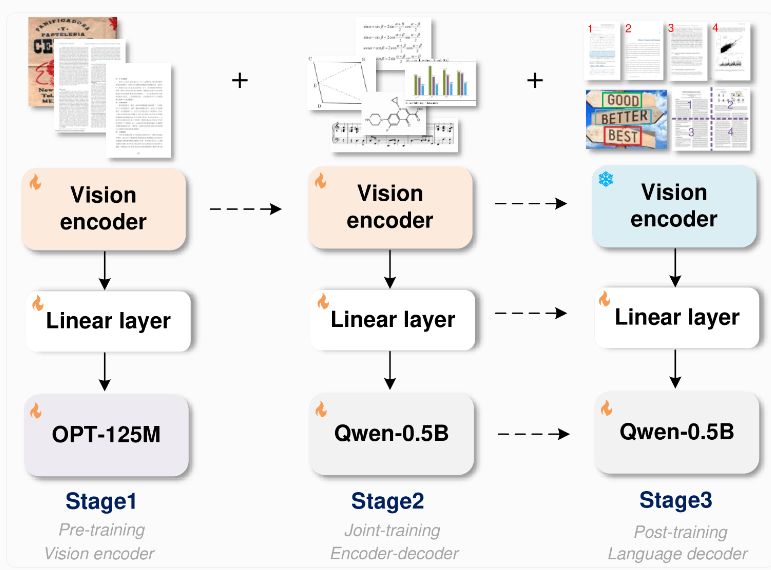
O modelo GOT adota uma arquitetura inovadora de ponta a ponta. Esse design não apenas economiza recursos, mas também expande enormemente os recursos de reconhecimento além do reconhecimento de texto. O modelo consiste em um codificador de imagem com aproximadamente 80 milhões de parâmetros e um decodificador com aproximadamente 5 milhões de parâmetros. O codificador de imagem é capaz de compactar imagens de até 1024x1024 pixels em unidades de dados, enquanto o decodificador converte esses dados em texto de até 8.000 caracteres.
O poder do GOT reside na sua versatilidade. Ele pode não apenas reconhecer e converter documentos e textos de cenas em inglês e chinês, mas também processar fórmulas matemáticas e químicas, símbolos musicais, figuras geométricas simples e vários gráficos. Isso torna o GOT um verdadeiro versátil.
Para treinar este modelo, a equipe de pesquisa primeiro se concentrou em tarefas de reconhecimento de texto, depois usou o Qwen-0.5B do Alibaba como decodificador e o ajustou com uma variedade de dados sintéticos. Eles usaram ferramentas de renderização profissionais como LaTeX, Mathpix-markdown-it e Matplotlib para gerar milhões de pares imagem-texto para treinamento de modelo.

Outro destaque da tecnologia OCR2.0 é a capacidade de extrair texto formatado, títulos e até imagens de várias páginas e convertê-los em um formato digital estruturado. Isto abre novas possibilidades para processamento e análise automatizados em áreas como ciência, música e análise de dados.
Em testes de diversas tarefas de OCR, o GOT demonstrou excelente desempenho, alcançando resultados líderes do setor em reconhecimento de documentos e textos de cena, e até mesmo superando muitos modelos profissionais e modelos de linguagem de grande porte no reconhecimento de gráficos. Quer se trate de fórmulas complexas de estrutura química ou notação musical e visualização de dados, o OCR2.0 pode capturá-los e convertê-los com precisão em formatos legíveis por máquina.
Para permitir que mais usuários experimentem e utilizem essa tecnologia, a equipe de pesquisa lançou demonstrações e códigos gratuitos na plataforma Hugging Face. A chegada do OCR2.0 trouxe, sem dúvida, uma revolução no campo do processamento de informação. Não só melhora a eficiência, mas também aumenta a flexibilidade, permitindo-nos processar mais facilmente informações de texto em imagens.
O surgimento do modelo GOT sem dúvida injetou uma nova vitalidade na tecnologia OCR. Seus recursos eficientes, precisos e versáteis serão amplamente utilizados em todas as esferas da vida, trazendo mais comodidade ao trabalho e à vida das pessoas. Esperamos melhorar ainda mais o modelo GOT no futuro e nos trazer mais surpresas!