A Apple lançou uma grande atualização para seu modelo de inteligência artificial multimodal MM1 - MM1.5. Esta atualização não é uma simples iteração de versão, mas uma melhoria completa das capacidades do modelo, melhorando significativamente seu desempenho na compreensão de imagens, reconhecimento de texto e execução de comandos visuais. O editor de Downcodes explicará detalhadamente as melhorias do MM1.5 e sua importância no campo da inteligência artificial multimodal.
A Apple lançou recentemente uma grande atualização em seu modelo de inteligência artificial multimodal MM1, atualizando-o para a versão MM1.5. Esta atualização não é apenas uma simples mudança no número de versão, mas uma melhoria abrangente de capacidade, permitindo que o modelo mostre um desempenho mais poderoso em vários campos.
A principal atualização do MM1.5 reside no seu método inovador de processamento de dados. O modelo adota uma abordagem de treinamento centrada em dados e o conjunto de dados de treinamento é cuidadosamente selecionado e otimizado. Especificamente, o MM1.5 usa dados OCR de alta definição e descrições de imagens sintéticas, bem como instruções visuais otimizadas para ajustar o mix de dados. A introdução desses dados melhorou significativamente o desempenho do modelo no reconhecimento de texto, compreensão de imagens e execução de instruções visuais.

Em termos de tamanho do modelo, o MM1.5 cobre múltiplas versões que variam de 1 bilhão a 30 bilhões de parâmetros, incluindo variantes intensivas e de mistura de especialistas (MoE). É importante notar que modelos de parâmetros de escala ainda menor, de 1 bilhão e 3 bilhões, podem atingir níveis de desempenho impressionantes com dados e estratégias de treinamento cuidadosamente projetados.
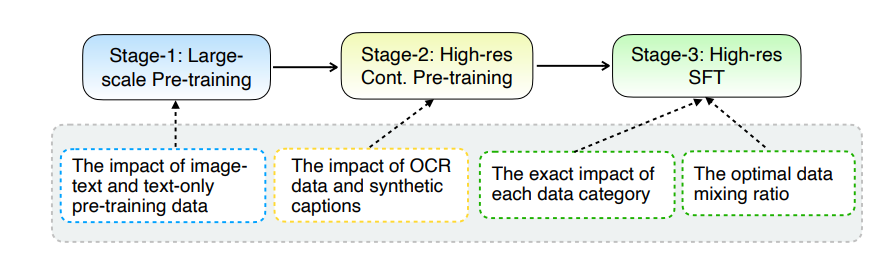
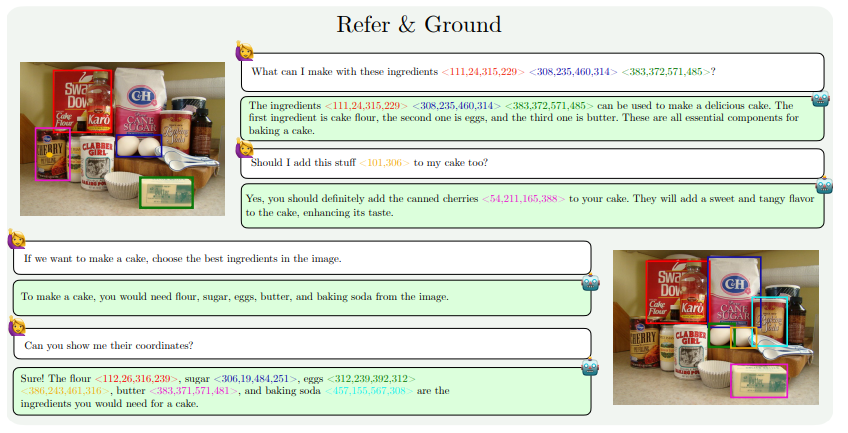
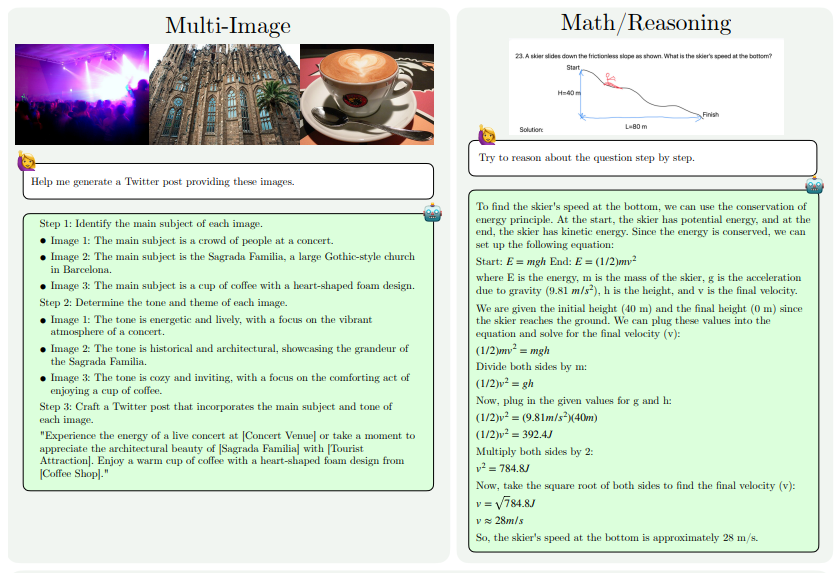
As melhorias de capacidade do MM1.5 refletem-se principalmente nos seguintes aspectos: compreensão de imagem com uso intensivo de texto, referência e posicionamento visual, raciocínio multi-imagem, compreensão de vídeo e compreensão de UI móvel. Esses recursos permitem que o MM1.5 seja aplicado a uma ampla gama de cenários, como identificação de artistas e instrumentos em fotos de shows, compreensão de dados de gráficos e resposta a perguntas relacionadas, localização de objetos específicos em cenas complexas, etc.
Para avaliar o desempenho do MM1.5, os pesquisadores o compararam com outros modelos multimodais avançados. Os resultados mostram que o MM1.5-1B tem um bom desempenho em um modelo com escala de 1 bilhão de parâmetros, significativamente melhor do que outros modelos do mesmo nível. MM1.5-3B supera MiniCPM-V2.0 e está no mesmo nível de InternVL2 e Phi-3-Vision. Além disso, o estudo também descobriu que, quer se trate de um modelo denso ou de um modelo MoE, o desempenho melhorará significativamente à medida que a escala aumenta.
O sucesso do MM1.5 não reflete apenas a força de pesquisa e desenvolvimento da Apple no campo da inteligência artificial, mas também aponta o caminho para o desenvolvimento futuro de modelos multimodais. Ao otimizar os métodos de processamento de dados e a arquitetura do modelo, mesmo os modelos de menor escala podem alcançar um forte desempenho, o que é de grande importância para a implantação de modelos de IA de alto desempenho em dispositivos com recursos limitados.
Endereço do artigo: https://arxiv.org/pdf/2409.20566
Em suma, o lançamento do MM1.5 marca um avanço significativo na tecnologia de inteligência artificial multimodal. Suas inovações em processamento de dados e arquitetura de modelos fornecem novas ideias e orientações para o desenvolvimento de futuros modelos de IA. Esperamos que a Apple continue a trazer mais resultados inovadores no campo da inteligência artificial.