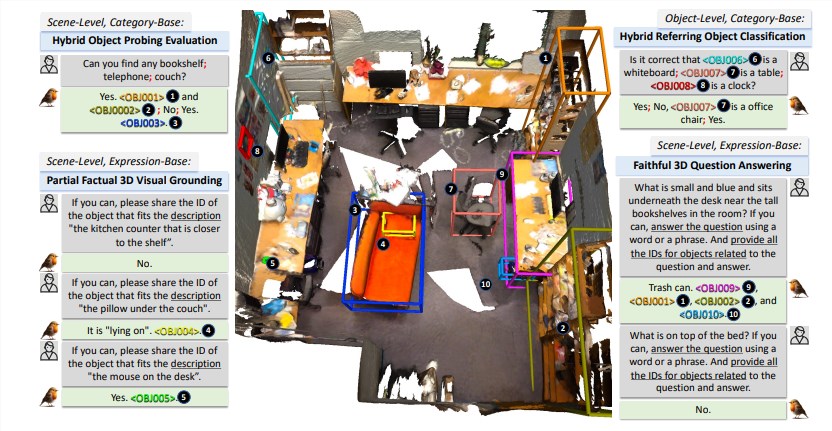
O editor do Downcodes aprendeu que equipes de pesquisa do Instituto de Tecnologia de Illinois e de outras universidades lançaram em conjunto o Robin3D, um novo modelo de linguagem grande para cenas 3D. O modelo foi treinado em um enorme conjunto de dados contendo milhões de instruções e alcançou desempenho de última geração em cinco benchmarks de aprendizagem multimodal 3D comumente usados. A inovação do Robin3D reside em seu mecanismo de dados RIG, que pode gerar dados de instrução adversários e diversificados, melhorando assim as capacidades de discriminação, compreensão e generalização do modelo, superando as capacidades de generalização insuficientes e os problemas de ajuste excessivo do modelo de linguagem 3D existente. Ele também integra tecnologias como Relationship Augmentation Projector (RAP) e ID Feature Binding (IFB) para aprimorar a compreensão do modelo sobre cenas e objetos.
O modelo foi treinado em um conjunto de dados em grande escala contendo um milhão de instruções a seguir e alcançou desempenho de última geração em cinco benchmarks de aprendizagem multimodais 3D comumente usados, marcando um passo importante na construção de um 3D universal Progresso significativo na direção de agentes inteligentes.
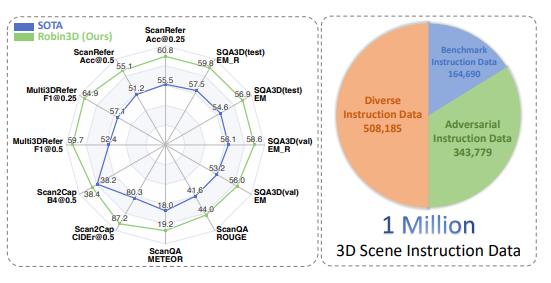
O sucesso do Robin3D se deve ao seu inovador mecanismo de dados RIG (Robust Instruction Generation). O mecanismo RIG foi projetado para gerar dois tipos principais de dados de comando: dados de conformidade de comando adversário e dados diversos de conformidade de comando.
Os dados de acompanhamento adversários melhoram a compreensão discriminativa do modelo, misturando amostras positivas e negativas, enquanto diversos dados de acompanhamento contêm vários estilos de instrução para aprimorar a capacidade de generalização do modelo.
Os pesquisadores apontaram que os grandes modelos de linguagem 3D existentes dependem principalmente de pares frontais de linguagem visual 3D e instruções de treinamento baseadas em modelos, o que leva a capacidades de generalização insuficientes e ao risco de overfitting. Robin3D supera efetivamente essas limitações, introduzindo dados de instrução adversários e diversos.
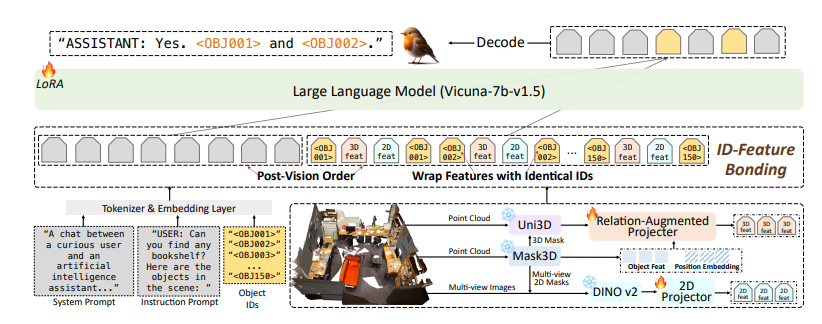
O modelo Robin3D também integra recursos de referência e posicionamento de ID Feature Binding (IFB) do Relationship Augmented Projector (RAP). O módulo RAP aprimora os recursos centrados no objeto com informações contextuais e de localização ricas em nível de cena, enquanto o módulo IFB fortalece as conexões entre cada ID, vinculando-as aos seus recursos correspondentes.
Os resultados experimentais mostram que o Robin3D supera os melhores métodos anteriores em cinco benchmarks, incluindo ScanRefer, Multi3DRefer, Scan2Cap, ScanQA e SQA3D, sem a necessidade de ajuste fino para tarefas específicas.
Especialmente na avaliação Multi3DRefer, incluindo o caso de alvo zero, Robin3D alcançou melhorias significativas de 7,8% e 7,3% nos indicadores F1@0,25 e F1@0,5, respectivamente.
O lançamento do Robin3D marca um progresso significativo na inteligência espacial de modelos 3D de grande linguagem, estabelecendo uma base sólida para a construção de agentes 3D mais versáteis e poderosos no futuro.
Endereço do artigo: https://arxiv.org/pdf/2410.00255
O surgimento do Robin3D sem dúvida trouxe novos avanços nas áreas de visão 3D e inteligência artificial. Vale a pena esperar por seu desempenho poderoso e amplas perspectivas de aplicação. Acredito que, no futuro, o Robin3D desempenhará um papel em mais campos e promoverá o rápido desenvolvimento da inteligência 3D. O editor do Downcodes continuará atento aos últimos desenvolvimentos nesta área.