Com o rápido desenvolvimento da tecnologia AIGC, a adulteração de imagens tornou-se cada vez mais generalizada. O método tradicional de detecção e localização de adulteração de imagens (IFDL) enfrenta o desafio da natureza da "caixa preta" e da capacidade de generalização insuficiente. O editor do Downcodes soube que uma equipe de pesquisa da Universidade de Pequim propôs uma estrutura multimodal chamada FakeShield, que visa resolver esses problemas. O FakeShield aproveita habilmente os poderosos recursos dos modelos de linguagem grande (LLM), especialmente modelos multimodais de linguagem grande (M-LLM), construindo um conjunto de dados de descrição de violação multimodal (MMTD-Set) e ajustando o modelo para alcançá-lo. e localiza diversas técnicas de adulteração e fornece resultados de análise interpretáveis.
Com o rápido desenvolvimento da tecnologia AIGC, as ferramentas de edição de imagens tornaram-se cada vez mais poderosas, tornando a adulteração de imagens mais fácil e mais difícil de detectar. Embora os métodos existentes de detecção e localização de adulteração de imagens (IFDL) sejam geralmente eficazes, eles muitas vezes enfrentam dois grandes desafios: primeiro, a natureza da "caixa preta" e os princípios de detecção pouco claros, em segundo lugar, a capacidade de generalização limitada e a dificuldade em lidar com vários métodos de adulteração (Tal); como Photoshop, DeepFake, edição AIGC).
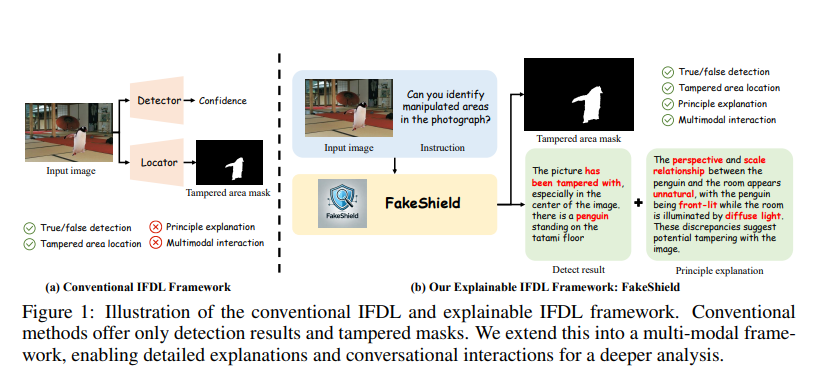
Para resolver esses problemas, a equipe de pesquisa da Universidade de Pequim propôs a tarefa IFDL interpretável e projetou o FakeShield, uma estrutura multimodal capaz de avaliar a autenticidade de imagens, gerar máscaras de área adulteradas e, com base em pistas de adulteração em nível de pixel e nível de imagem, fornecer um base para julgamento.
O método IFDL tradicional só pode fornecer a probabilidade de autenticidade e a área de adulteração da imagem, mas não pode explicar o princípio de detecção. Devido à precisão limitada dos métodos IFDL existentes, o julgamento manual subsequente ainda é necessário. No entanto, como as informações fornecidas pelo método IFDL são insuficientes para apoiar a avaliação manual, os próprios usuários ainda precisam reanalisar imagens suspeitas.
Além disso, em cenários da vida real, existem vários tipos de adulteração, incluindo Photoshop (copiar, mover, unir e remover), edição AIGC, DeepFake, etc. Os métodos IFDL existentes geralmente só conseguem lidar com uma das técnicas e carecem de capacidades abrangentes de generalização. Isso força os usuários a identificar antecipadamente diferentes tipos de adulteração e aplicar métodos de detecção específicos de acordo, reduzindo bastante a utilidade desses modelos.
Para resolver esses dois principais problemas dos métodos IFDL existentes, a estrutura FakeShield aproveita os poderosos recursos de grandes modelos de linguagem (LLMs), especialmente modelos multimodais de grandes linguagens (M-LLMs), que são capazes de alinhar recursos visuais e textuais, capacitando assim o LLM. tem capacidades de compreensão visual mais fortes. Como os LLMs são pré-treinados em um corpus enorme e diversificado de conhecimento mundial, eles têm grande potencial em muitos campos de aplicação, como tradução automática, conclusão de código e compreensão visual.
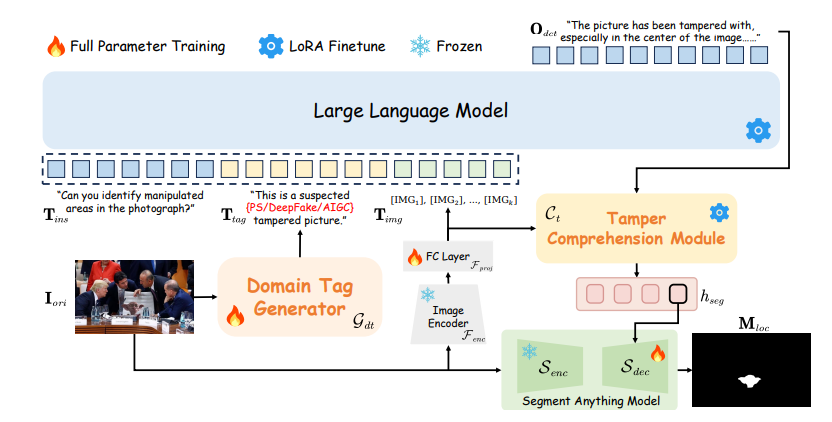
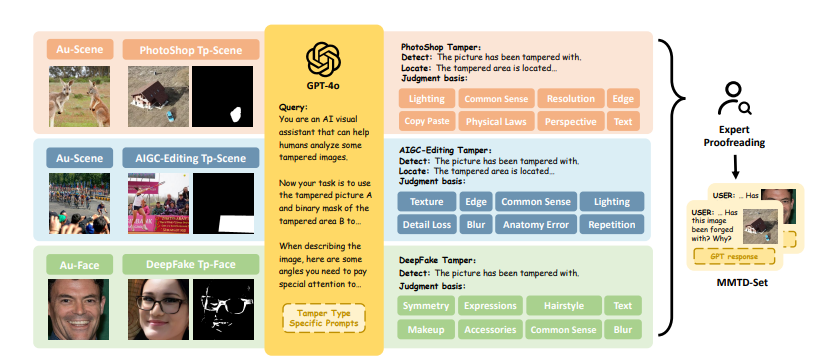
O núcleo da estrutura FakeShield é o conjunto de dados de descrição de violação multimodal (MMTD-Set). Este conjunto de dados utiliza GPT-4o para aprimorar o conjunto de dados IFDL existente e contém triplos de imagens adulteradas, máscaras de região modificadas e descrições detalhadas de regiões editadas. Ao aproveitar o MMTD-Set, a equipe de pesquisa ajustou o M-LLM e os modelos de segmentação visual para que possam fornecer resultados de análise completos, incluindo a detecção de adulteração e a geração de máscaras precisas de área adulterada.
O FakeShield também inclui o Módulo de Detecção de Falsificação Interpretável Guiado por Rótulo de Domínio (DTE-FDM) e o Módulo de Localização de Falsificação Multimodal (MFLM), que são usados respectivamente para resolver vários tipos de interpretação de detecção de adulteração e implementar localização de falsificação guiada por descrições de texto detalhadas.
Extensos experimentos mostram que o FakeShield pode detectar e localizar com eficácia várias técnicas de adulteração, fornecendo uma solução interpretável e superior em comparação com os métodos IFDL anteriores.
O resultado desta pesquisa é a primeira tentativa de aplicar o M-LLM ao IFDL interpretável, marcando um progresso significativo neste campo. O FakeShield não é apenas bom na detecção de adulteração, mas também fornece explicações abrangentes e localização precisa, além de demonstrar fortes capacidades de generalização para vários tipos de adulteração. Esses recursos o tornam uma ferramenta utilitária versátil para uma variedade de aplicações do mundo real.
No futuro, este trabalho desempenhará um papel vital em múltiplas áreas, tais como ajudar a melhorar leis e regulamentos relacionados com a manipulação de conteúdos digitais, fornecer orientação para o desenvolvimento de inteligência artificial generativa e promover um ambiente online mais claro e mais confiável. . Além disso, o FakeShield pode ajudar na recolha de provas em processos judiciais e ajudar a corrigir a desinformação no discurso público, ajudando, em última análise, a melhorar a integridade e a fiabilidade dos meios de comunicação digitais.
Página inicial do projeto: https://zhipeixu.github.io/projects/FakeShield/
Endereço GitHub: https://github.com/zhipeixu/FakeShield
Endereço do artigo: https://arxiv.org/pdf/2410.02761
O surgimento do FakeShield trouxe novos avanços no campo da detecção de adulteração de imagens. Sua interpretabilidade e forte capacidade de generalização fazem com que ele tenha um grande potencial em aplicações práticas. Vale a pena aguardar seu uso futuro na manutenção da segurança da rede e na melhoria da credibilidade do digital. a mídia desempenha um papel maior. O editor do Downcodes acredita que esta tecnologia terá um impacto positivo na autenticidade e fiabilidade dos conteúdos digitais.