O editor do Downcodes aprendeu que um estudo inovador da Universidade de Yale revelou o segredo do treinamento de modelos de IA: a complexidade dos dados não é maior, melhor, mas há um estado ideal de "limite do caos". A equipe de pesquisa usou habilmente o modelo de autômato celular para conduzir experimentos, explorou o impacto de dados de diferentes complexidades no efeito de aprendizagem do modelo de IA e chegou a conclusões atraentes.
Uma equipe de pesquisa da Universidade de Yale divulgou recentemente um resultado de pesquisa inovador, revelando uma descoberta importante no treinamento de modelos de IA: os dados com o melhor efeito de aprendizado de IA não são mais simples ou mais complexos, mas há um nível de complexidade ideal - um estado conhecido como beira do caos.
A equipe de pesquisa conduziu experimentos usando autômatos celulares elementares (ECAs), que são sistemas simples nos quais o estado futuro de cada unidade depende apenas de si mesmo e dos estados de duas unidades adjacentes. Apesar da simplicidade das regras, tais sistemas podem produzir diversos padrões que vão desde simples até altamente complexos. Os pesquisadores então avaliaram o desempenho desses modelos de linguagem em tarefas de raciocínio e previsão de movimentos de xadrez.
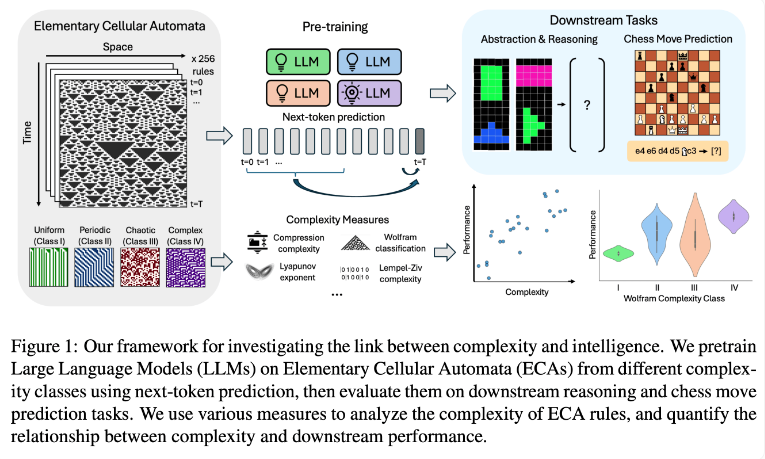
Os resultados da investigação mostram que os modelos de IA treinados em regras de ECA mais complexas têm um melhor desempenho em tarefas subsequentes. Em particular, os modelos treinados em ECAs Classe IV da Classificação Wolfram apresentaram o melhor desempenho. Os padrões gerados por tais regras não são nem completamente ordenados nem completamente caóticos, mas exibem uma complexidade estruturada.
Os pesquisadores descobriram que quando os modelos eram expostos a padrões muito simples, muitas vezes aprendiam apenas soluções simples. Em contraste, modelos treinados em padrões mais complexos desenvolvem capacidades de processamento mais sofisticadas, mesmo quando soluções simples estão disponíveis. A equipe de pesquisa especula que a complexidade desta representação aprendida é um fator chave na capacidade do modelo de transferir conhecimento para outras tarefas.
Esta descoberta pode explicar porque grandes modelos de linguagem, como GPT-3 e GPT-4, são tão eficientes. Os investigadores acreditam que os dados massivos e diversos utilizados no treino destes modelos podem ter criado efeitos semelhantes aos complexos padrões ECA no seu estudo.
Esta pesquisa fornece novas ideias para o treinamento de modelos de IA e uma nova perspectiva para a compreensão dos poderosos recursos de grandes modelos de linguagem. No futuro, talvez possamos melhorar ainda mais o desempenho e as capacidades de generalização dos modelos de IA, controlando com mais precisão a complexidade dos dados de treinamento. O editor do Downcodes acredita que o resultado desta pesquisa terá um impacto profundo no campo da inteligência artificial.