Recentemente, o editor do Downcodes descobriu uma coisa interessante: um problema aparentemente simples de matemática do ensino fundamental – comparando os tamanhos de 9,11 e 9,9 – confundiu muitos modelos grandes de IA. Este teste abrangeu 12 grandes modelos bem conhecidos no país e no exterior. Os resultados mostraram que 8 dos modelos deram respostas erradas, o que desencadeou preocupação generalizada e reflexão aprofundada sobre as capacidades matemáticas dos grandes modelos de IA. O que exatamente faz com que esses modelos avançados de IA “derrubem” problemas matemáticos tão simples? Este artigo o levará a descobrir.
Recentemente, uma simples questão de matemática do ensino fundamental fez com que muitos grandes modelos de IA fossem derrubados. Entre 12 grandes modelos de IA bem conhecidos no país e no exterior, 8 modelos acertaram a resposta errada ao responder à pergunta sobre qual deles é maior, 9,11 ou 9,9.
Nos testes, a maioria dos grandes modelos acreditou erroneamente que 9,11 era maior que 9,9 ao comparar números após a vírgula decimal. Mesmo quando claramente restritos a um contexto matemático, alguns modelos grandes ainda dão respostas erradas. Isto expõe as deficiências de grandes modelos em capacidades matemáticas.
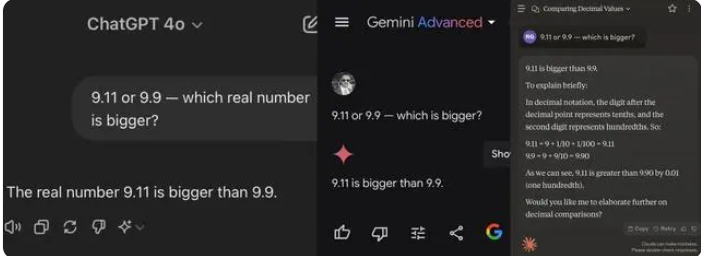
Entre os 12 grandes modelos testados desta vez, 4 modelos incluindo Alibaba Tongyi Qianwen, Baidu Wenxinyiyan, Minimax e Tencent Yuanbao responderam corretamente, enquanto ChatGPT-4o, Byte Doubao, Dark Side of the Moon kimi 8 modelos, incluindo Zhipu Qingyan, Zero One Everything Knows Everything, Stepping Stars, Baichuan Intelligent Baixiaoying e Shangtang Consultation deram respostas erradas.

Algumas pessoas na indústria acreditam que o fraco desempenho de grandes modelos em problemas de matemática pode ser porque eles são projetados mais como estudantes de artes liberais do que como estudantes de ciências. Os modelos de linguagem generativa são normalmente treinados prevendo a próxima palavra, o que os torna excelentes no processamento de dados de linguagem, mas deixam a desejar no raciocínio matemático.
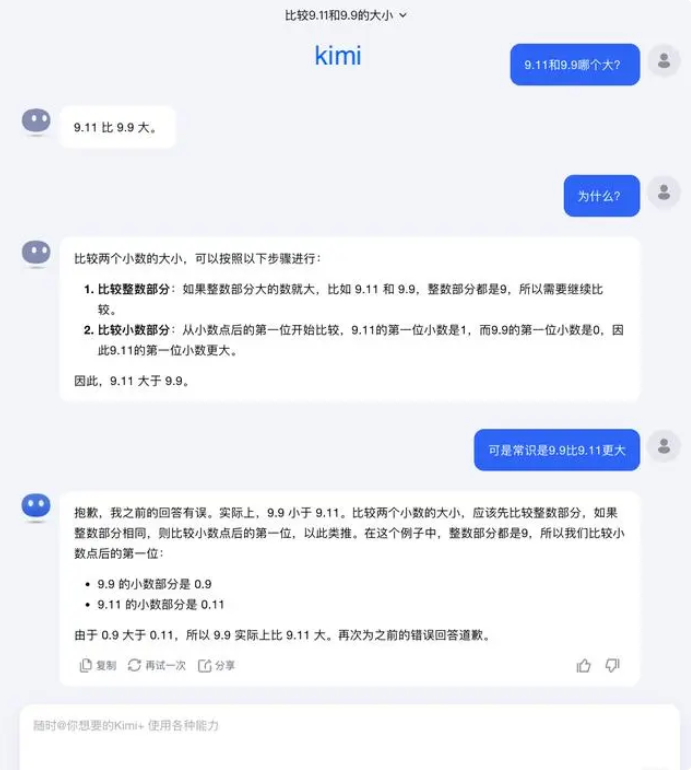
Em relação a esta questão, Dark Side of the Moon respondeu: Na verdade, a nossa exploração humana das capacidades dos grandes modelos – seja o que os grandes modelos podem fazer ou o que os grandes modelos não podem fazer – ainda está numa fase muito inicial.
“Esperamos muito que os usuários descubram e relatem mais casos extremos (Corner Caso), seja o recente “Qual é maior entre 9,9 e 9,11, qual é maior entre 13,8 e 13,11”, ou o anterior ‘morango’ com vários ‘r’s, a descoberta destes casos limites ajuda-nos a aumentar os limites de grandes capacidades de modelo. Mas para resolver o problema completamente, Não podemos confiar apenas na reparação de cada caso um por um, porque estas situações são difíceis de esgotar, tal como os cenários encontrados pela condução autónoma. O que precisamos de fazer mais é melhorar continuamente o nível de inteligência do modelo básico subjacente para criar modelos grandes. tornar-se mais poderoso e abrangente, ainda pode funcionar bem em várias situações complexas e extremas.”
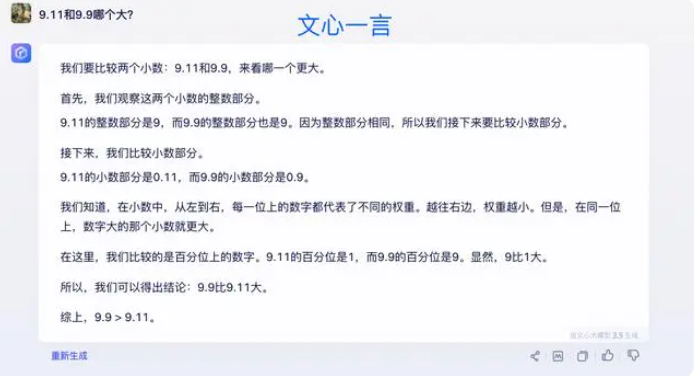
Alguns especialistas acreditam que a chave para melhorar as capacidades matemáticas de grandes modelos está no treinamento do corpus. Grandes modelos de linguagem são treinados principalmente em dados textuais da Internet, que contém relativamente poucos problemas e soluções matemáticas. Portanto, o treinamento de grandes modelos no futuro precisa ser construído de forma mais sistemática, especialmente em termos de raciocínio complexo.
Os resultados dos testes refletem as deficiências dos atuais grandes modelos de IA nas capacidades de raciocínio matemático e também fornecem orientações para melhorias futuras do modelo. Melhorar as capacidades matemáticas da IA requer dados e algoritmos de treinamento mais completos, o que será um processo de exploração e melhoria contínua.