A inteligência artificial fez progressos significativos no reconhecimento de imagens nos últimos anos, mas a compreensão do vídeo continua a ser um enorme desafio. A dinâmica e a complexidade dos dados de vídeo trazem dificuldades sem precedentes para a IA. No entanto, espera-se que o codificador de vídeo VideoPrism desenvolvido pela equipe de pesquisa do Google mude esta situação. O editor de Downcodes lhe dará uma compreensão profunda das funções poderosas do VideoPrism, métodos de treinamento e seu profundo impacto no futuro campo da compreensão de vídeo de IA.
No mundo da IA, é muito mais difícil para as máquinas compreender vídeos do que imagens. O vídeo é dinâmico, com som, movimento e um monte de cenas complexas. No passado, com a IA, assistir a vídeos era como ler um livro do céu, e muitas vezes você ficava confuso.
Mas o surgimento do VideoPrism pode mudar tudo. Este é um codificador de vídeo desenvolvido pela equipe de pesquisa do Google. Ele pode atingir o nível de última geração com um único modelo em uma variedade de tarefas de compreensão de vídeo. Seja classificando vídeos, posicionando-os, gerando legendas ou até mesmo respondendo perguntas sobre vídeos, VideoPrism pode cuidar disso facilmente.

Como treinar o VideoPrism?
O processo de treinamento do VideoPrism é como ensinar uma criança a observar o mundo. Primeiro, você deve mostrar uma variedade de vídeos, desde a vida cotidiana até observações científicas. Em seguida, você também o treina com alguns pares de legendas de vídeo de "alta qualidade" e algum texto paralelo barulhento (como texto de reconhecimento automático de fala).
Método pré-treinamento
Dados: VideoPrism usa 36 milhões de pares de legendas de vídeo de alta qualidade e 58,2 milhões de videoclipes com texto paralelo barulhento.
Arquitetura do modelo: Baseada no transformador visual padrão (ViT), utilizando design fatorado no espaço e no tempo.
Algoritmo de treinamento: inclui duas etapas: treinamento de comparação vídeo-texto e modelagem de vídeo mascarado.
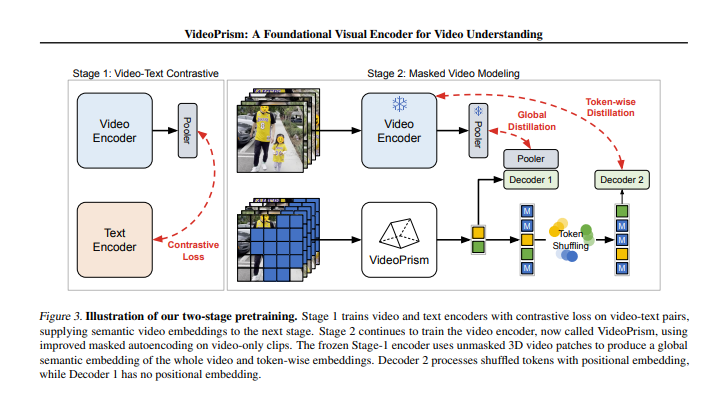
Durante o processo de treinamento, o VideoPrism passará por duas etapas. Na primeira fase, aprende a ligação entre vídeo e texto através da aprendizagem contrastiva e da destilação global-local. Na segunda etapa, melhora ainda mais a compreensão do conteúdo do vídeo por meio da modelagem de vídeo mascarado.
Os pesquisadores testaram o VideoPrism em várias tarefas de compreensão de vídeo e os resultados foram impressionantes. VideoPrism alcança desempenho de última geração em 30 dos 33 benchmarks. Seja respondendo a perguntas de vídeo on-line ou tarefas de visão computacional no campo científico, o VideoPrism demonstrou fortes capacidades.
O nascimento do VideoPrism trouxe novas possibilidades para o campo da compreensão de vídeo de IA. Não só pode ajudar a IA a compreender melhor o conteúdo de vídeo, como também pode desempenhar um papel importante na educação, entretenimento, segurança e outros campos.
Mas o VideoPrism também enfrenta alguns desafios, como lidar com vídeos longos e evitar a introdução de preconceitos durante o processo de treinamento. Essas são questões que precisam ser abordadas em pesquisas futuras.
Endereço do artigo: https://arxiv.org/pdf/2402.13217
Em suma, o surgimento do VideoPrism marca um grande progresso no campo da compreensão de vídeo de IA. Seu desempenho poderoso e amplas perspectivas de aplicação são emocionantes. No futuro, com o desenvolvimento contínuo da tecnologia, acredito que o VideoPrism mostrará seu valor em mais áreas e trará mais comodidade à vida das pessoas.